
Einführung
Nachdem wir uns bereits ausführlich mit dem Regressionsproblem befasst haben, lernen wir hier nun das andere grosse Supervised Learning Problem kennen: das Klassifikationsproblem. In der Praxis sind Klassifikationsprobleme fast häufiger anzutreffen als Regressionsprobleme. Im binären Klassifikationsproblem ist es unser Ziel vorherzusagen, ob eine Beobachtung der Kategorie 1 (\(y_i=1\), “Erfolg”) oder der Kategorie 0 (\(y_i=0\), “Misserfolg”) angehört. Unsere Output-Variable ist hier also nicht mehr quantitativ sondern qualitativ (kategorisch) und hat zwei mögliche Kategorien (oder Klassen).
Themen und Lernziele
Wir werden uns zwei Modelle für das Klassifikationsproblem anschauen: die logistische Regression und Naive Bayes. Ein wichtiger Aspekt beim Klassifikationsproblem ist die Frage, wie man die Modell- bzw. Vorhersagegüte korrekt evaluiert. Als Beispiel verwenden wir die Klassifikation von Emails in Spam und nicht-Spam (“Ham”). Der Abschnitt Spam Filter enthält den R Code, welcher einen Spam Filter aufsetzt und fittet. Zum Schluss werden wir den Spam Filter deployen.
Lernziele
- Sie sind in der Lage Regressions- von Klassifikationsproblemen zu unterscheiden.
- Sie verstehen die Bag-of-Words Methode.
- Sie verstehen inwiefern sich das Logistische Regressionsmodell vom Linearen Regressionsmodell unterscheidet.
- Sie verstehen den Zweck der Sigmoid Funktion und kennen die Eigenschaften dieser Funktion.
- Sie verstehen die Kostenfunktion des Logistischen Regressionsmodells und verstehen intuitiv, wie der Modell Fitting Prozess funktioniert.
- Sie können die Decision Boundaries im Fall von einer und zwei Input-Variablen herleiten und verstehen, wie die Decision Boundaries grafisch aussehen.
- Sie verstehen das Konzept der linearen Separierbarkeit.
- Sie verstehen den Satz von Bayes und die Übertragung dieses wichtigen Resultats in das Naive Bayes Modell.
- Sie verstehen die wichtige Unabhängigkeitsannahme, welche dem Naive Bayes Modell zugrunde liegt.
- Sie verstehen das Modell Training des Naive Bayes Modells anhand eines einfachen Beispiels.
- Sie kenne die verschiedenen Masse zur Evaluation von Klassifikationsproblemen und können sie mit R, aber auch von Hand und für einfache Beispiele (bzw. mit dem Taschenrechner) berechnen.
- Sie können den R Code im Spam Filter Beispiel nachvollziehen und sind bereit, die Code Fragmente auf neue Beispiele zu übertragen.
- Sie können ein ML Modell mithilfe einer Shiny App deployen.
Praxisbeispiel
Wir werden die erlernten Modelle und Theorien anhand eines Spam Filters illustrieren. Der Spam Filter soll eine gegebene Email möglichst korrekt in die Kategorien Spam (\(y_i=1\)) oder Ham (\(y_i=0\)) klassifizieren. Wichtig: die meisten Klassifikationsmethoden modellieren nicht direkt \(y_i\), sondern die Wahrscheinlichkeit \(p(y_i = 1 | \mathbf{x}_i)\), also die Wahrscheinlichkeit, dass es sich bei der \(i\)-ten Beobachtung um Spam handelt, gegeben die Input-Daten \(\mathbf{x}_i\).
Wie sehen im Fall des Spam Filters die Input-Daten \(\mathbf{x}_i\) aus? Unsere Datengrundlage besteht hier aus Emails, also aus unstrukturierten Daten. Hier eine Beispiels-Email. Sie können selbst erraten, ob es sich hier um Spam oder Ham handelt…
For your kind attention,
It is my humble pleasure to write you this letter irrespective of the fact that you do not know me. However,I am in search of a reliable and trustworthy person that can handle a confidential transaction of this nature.
I am BARRISTER ADEWALE COKER, a family lawyer to our former military rule,General Sani Abacha who died suddenly in power some years ago. Since his untimely demise, the family has suffered a lot of harassment from the regimes that succeeded him. The regime and even the present civilian government are made up of Abacha's enemies.Recently, the wife was banned from traveling outside Kano State their home state as a kind of house arrest and the eldest son still in detention.Although, a lot of money have been recovered from Mrs. Abacha since the death of her husband by the present government, there's still huge sums of money in hard currencies that we have been able to move out of the country for safe keeping to the tune of US$50 million.This money US$50 Million is already in North American and if you are interested,we will prepare you as the beneficiary of the total funds,and you will share 25% of the total funds after clearance from the Security Compan!
y.
Note, there is no risk involved in this project because l am involved as Abacha's confidant.Please you should keep this transaction a top secret and we are prepared to do more business with you pending your approach towards this project.I await your urgent response.Thanks.
Yours Faithfully
BARRISTER ADEWALE COKER.Das Beispiel, das wir uns hier konkret anschauen werden, basiert auf dem Public Spamassassin Corpus und ist angelehnt an ein Beispiel im fantastischen Coursera Kurs von Andrew Ng (einer der Gründer von Coursera).
Im Fall von unstrukturierten Daten muss man sich überlegen, wie man die Daten in eine strukturierte Form bringt. Oder in anderen Worten, wie kommt man von einer Email zu einem Input-Daten Vektor \(\mathbf{x}_i\)? Eine Möglichkeit ist der sogenannte Bag-of-Words Ansatz. Dabei geht man folgendermassen vor:
- Man bestimmt die häufigsten Wörter im Trainingsdatensatz (Emails, die wir für das Training verwenden werden). In unserem Beispiel enthält der Vektor
vocaballe Wörter, die in mindestens 100 Emails des Trainingsdatensatzes vorkommen. Schauen wir uns die ersten paar Wörter doch mal an:
# Erste 10 Wörter in vocab
vocab[1:10]- Das erste Wort in diesem Set von häufig vorkommenden Wörtern wird durch die erste Input-Variable \(x_{i1}\) repräsentiert, das zweite Wort durch die zweite Input-Variable \(x_{i2}\), usw. Für eine Beobachtung \(i\) (bzw. die \(i\)-te Email) ist die Input-Variable \(x_{i1}=1\) falls das erste Wort in der Email vorkommt und sonst 0. Dasselbe gilt natürlich für alle anderen Input-Variablen. So kann eine Email in einen fixen Input-Vektor von Nullen und Einsen transformiert werden. In R lässt sich dies relativ einfach bewerkstelligen:
# Email in tokenized Form
print(email)
# Vektor mit Nullen
email_bow <- rep(0, length(vocab))
# Setze eine 1 für alle Wörter aus vocab, die in der Email vorkommen
email_bow[which(vocab %in% email)] <- 1Die folgende Abbildung illustriert die Bag-of-Words Methode an einem einfachen Beispiel:

Mithilfe der Bag-of-Words Methode können unstrukturierte Textdaten in einen strukturierten Dataframe (oder eine Matrix) transformiert werden. Am Schluss wird uns natürlich interessieren, welche Wörter zu einer besonders grossen Spam-Wahrscheinlichkeit führen.
Wir haben die Daten bereits für Sie geladen und Sie können sie in unten stehendem Code Block anschauen. Sie werden sofort sehen, dass sie bereits im Bag-of-Words Format sind!
# Dimensionen des Trainings- und Testdatensatzes
dim(X_train)
dim(X_test)
# Welche Worte kommen in erster Email (Spam) vor?
colnames(X_train)[X_train[1,] == 1]Schauen wir uns doch auch noch kurz die Labels bzw. die Output-Variablen an:
# Trainingsdaten
table(y_train)
table(y_train) / length(y_train)
# Testdaten
table(y_test)
table(y_test) / length(y_test)Wir wollen nun die Input-Daten und die Labels zu einem Dataframe zusammenfassen. Dabei soll das Label mit mutate() gleich in eine Faktor-Variable transformiert werden. Bitte vervollständigen Sie unten stehenden Code.
# Trainingsdaten
train <- as.data.frame() %>%
mutate()
# Testdaten
test <- as.data.frame() %>%
mutate()# Trainingsdaten
train <- as.data.frame(X_train) %>%
mutate(y = factor(y_train, levels = c(0, 1), labels = c("Ham", "Spam")))
# Testdaten
test <- as.data.frame(X_test) %>%
mutate(y = factor(y_test, levels = c(0, 1), labels = c("Ham", "Spam")))Nun sind wir bereit, in den Modellierungsteil einzusteigen.
Weiterführende Ressourcen
- Kapitel 3 und 4 in HOML
- Kapitel 4 in ISLR
- Get Started with tidymodels
- Kaggle Ressourcen zu NLP
- Tidy Text Mining in R
Logistische Regression
Logistische Regression ist das Gegenstück zur linearen Regression für das Klassifikationsproblem. Es ist ein einfaches Modell, das oft als guter Ausgangspunkt dient. D.h. oft macht es Sinn als erstes Modell ein logistisches Regressionsmodell zu rechnen.
Output-Variable
Die Output-Variable bzw. das Label im binären Klassifikationsproblem ist eine kategorische Variable mit zwei möglichen Kategorien (Klassen). Wie oben erwähnt nimmt die Output-Variable den Wert 1 an (\(y_i=1\)), falls eine Beobachtung der Kategorie 1 angehört und sonst den Wert 0 (\(y_i=0\)). Typischerweise geben wir den Wert 1 der Kategorie, die uns wirklich interessiert (z.B. Spam, Default, Disease).
Wie ebenfalls bereits erwähnt modellieren wir mit Klassifikationsmodellen nicht direkt die Output-Variable \(y_i\) (wie im Regressionsproblem), sondern die Wahrscheinlichkeit, dass \(y_i=1\), gegeben irgendwelche Input-Daten. Mathematisch schreiben wir diese Wahrscheinlichkeit als \(p(y_i = 1 | \mathbf{x}_i)\).
Im einfachsten Fall ist unsere Vorhersage \(\hat{y}_i=1\), falls die geschätzte Wahrscheinlichkeit \(p(y_i = 1 | \mathbf{x}_i) > 50\%\), und sonst \(\hat{y}_i=0\). Hier haben wir einen Threshold von 50% gewählt, aber grundsätzlich können wir auch andere Thresholds wählen (z.B. 20% oder 85%), um von den geschätzten Wahrscheinlichkeiten eine Vorhersage abzuleiten. Dazu später mehr!
Modellspezifikation
Bevor wir das logistische Regressionsmodell spezifizieren, erinnern wir uns ganz kurz an die Modellspezifikation des linearen Regressionsmodells:
\[ f(\mathbf{x}_i) = w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip} \] Im Vergleich zur ersten Veranstaltung haben wir hier die Parameter mit \(w\) bezeichnet anstatt mit \(b\). Im Machine Learning ist es üblich von Gewichten (Weights) zu sprechen, weshalb es intuitiv mehr Sinn macht die Parameter mit \(w\) zu bezeichnen. Sie können obige Formel auch als gewichtete Summe der Input-Daten \(\mathbf{x}_i\) anschauen.
Diese gewichtete Summe wird auch bei der logistischen Regression eine wichtige Rolle spielen. Wir haben oben bereits gesehen, dass folgende Modellgleichung leider nicht eine gute Idee ist:
\[ p(y_i = 1 | \mathbf{x}_i) = w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip} \] Warum nicht? Weil die gewichtete Summe je nach Input-Daten mal negativ sein kann oder auch grösser als 1. Gleichzeitig wissen wir aus der Wahrscheinlichkeitstheorie, dass eine Wahrscheinlichkeit immer zwischen 0 und 1 liegen muss.
Wir müssen also die gewichtete Summe nehmen und in eine mathematische Funktion “verpacken”, so dass die Outputs dieser Funktion immer zwischen 0 und 1 liegen. Die Sigmoid Funktion (auch Logistische Funktion genannt) tut genau das. Sie nimmt einen Input \(z\) und gibt einen Wert zwischen 0 und 1 zurück. Die Funktion sieht folgendermassen aus:
\[ g(z) = \frac{e^z}{1+e^z}=\frac{1}{1+e^{-z}} \] Für jeden Wert von \(z\) gibt uns die Funktion \(g(z)\) einen Wert zwischen 0 und 1 zurück. Grafisch sieht die Sigmoid Funktion folgendermassen aus:
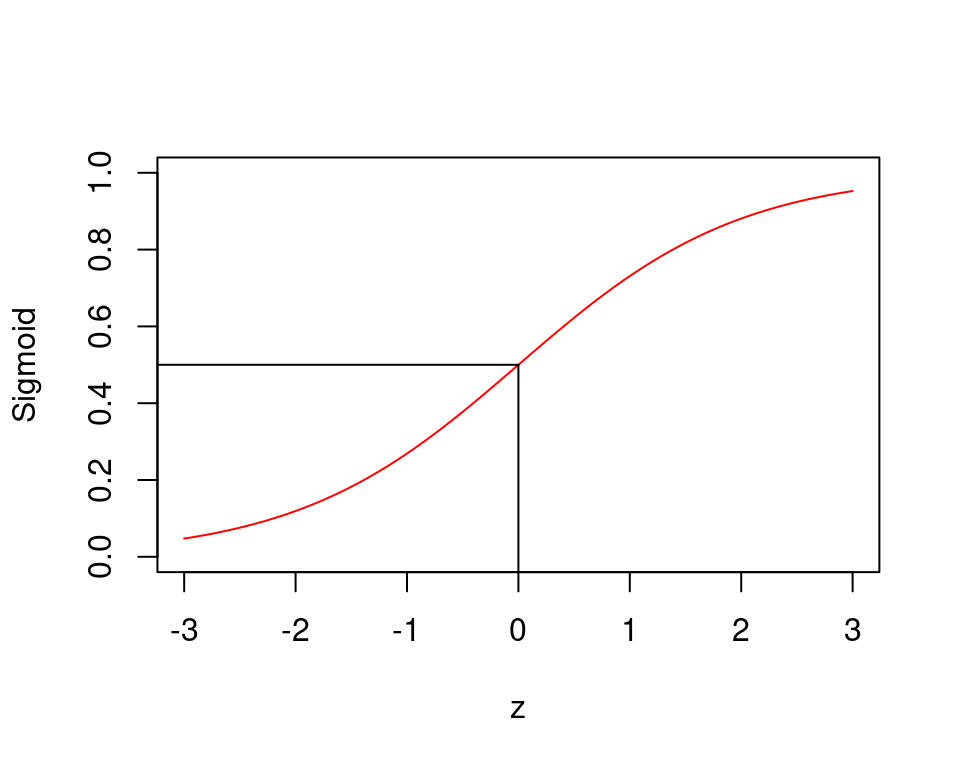
Sie sehen hier eine wichtige Eigenschaft der Sigmoid Funktion: sie nimmt den Wert 0.5 an, wenn \(z=0\).
Versuchen Sie im folgenden Code Block die Sigmoid Funktion in R zu implementieren.
# Probieren Sie die Sigmoid Funktion mit R zu implementieren.
sigmoid <- function(z){"IHR CODE"}
# Plot der Funktion
curve(sigmoid, from = -3, to = 3, xlab = "z", ylab = "Sigmoid", ylim = c(0,1), col = "red")# Sigmoid Funktion
sigmoid <- function(z){1 / (1 + exp(-z))}
# Plot der Funktion
curve(sigmoid, from = -3, to = 3, xlab = "z", ylab = "Sigmoid", ylim = c(0,1), col = "red")Nun können wir alles zusammensetzen, was ganz einfach bedeutet, dass wir nun anstelle von \(z\) die gewichtete Summe in die Sigmoid Funktion einsetzen. Das logistische Regressionsmodell sieht dementsprechend dann wie folgt aus:
\[ p(y_i = 1 | \mathbf{x}_i) = \frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}} \] Im nächsten Abschnitt wollen wir herausfinden, wie die Parameter des Modells, also \(w_0, w_1, \dots\), geschätzt werden.
Modelltraining
Modelltraining heisst auch hier nichts anderes, als dass wir die Parameter eines Modells möglichst optimal schätzen wollen. Sie haben in der Einführung zum Machine Learning bereits gelernt, dass wir in der Phase des Modelltrainings eine Kostenfunktion aufstellen, die es dann zu minimieren gilt. Doch wie soll eine Kostenfunktion für das Klassifikationsproblem aussehen?
Im Idealfall spuckt unser Modell eine Wahrscheinlichkeit von 0 aus für alle Beobachtungen, bei denen \(y_i=0\). Für alle Beobachtungen, wo \(y_i=1\), gibt unser Modell im Idealfall eine Wahrscheinlichkeit von 1 zurück. In diesem Idealfall sollte die Kostenfunktion 0 betragen. Wie können wir das mathematisch abbilden?
Die “Kosten” für eine einzelne Beobachtung mit dem Label \(y_i=1\) schreiben wir als \(-\text{log}(p(y_i = 1 | \mathbf{x}_i))\). Warum das Sinn macht, sehen Sie anhand folgender App:
Für Beobachtungen mit dem Label \(y_i=0\) sind die “Kosten” dementsprechend \(-\text{log}(1-p(y_i = 1 | \mathbf{x}_i))\).
Wir haben nun die Kosten für einzelne Beobachtungen angeschaut und gesehen, dass die Kosten vom Label \(y_i\) abhängen. Die Gesamtkostenfunktion ist der Durchschnitt über die individuellen Kosten (gemittelt über alle Beobachtungen im Trainingsdatensatz). Mathematisch sieht das Ganze folgendermassen aus:
\[ J = -\frac{1}{n}\sum_{i=1}^n \left[y_i \cdot \text{log}(p(y_i = 1 | \mathbf{x}_i)) + (1-y_i) \cdot \text{log}(1-p(y_i = 1 | \mathbf{x}_i))\right] \] Überlegen Sie sich kurz, warum diese Berechnung Sinn macht. Wenn die \(i\)-te Beobachtung das Label \(y_i=1\) hat, dann entfällt der zweite Teil in den eckigen Klammern, weil in diesem Fall \((1-y_i)=0\) ist. Wenn die \(i\)-te Beobachtung hingegen das Label \(y_i=0\) hat, dann entfällt der erste Teil in den eckigen Klammern, weil die individuellen Kosten mit 0 multipliziert werden. Wir haben hier also eine kompakte mathematische Form, um die Gesamtkostenfunktion aufzuschreiben. In der Praxis wird diese Kostenfunktion häufig log-loss genannt.
Wir suchen also nun die Parameter \(w_0, w_1, \dots\), welche die obige log-loss Kostenfunktion minimieren. Leider gibt es keine einfache Formel dazu (oder in Fachsprache: keine closed-form oder analytical solution). Wir können aber die optimalen Parameter mit anderen Optimierungsmethoden (beispielsweise mit Gradient Descent) finden. Zum Glück haben wir in R viele Packages und Funktionen, welche dieses Optimierungsproblem für uns in wenigen Millisekunden lösen!
Zwei letzte wichtige Punkte in diesem Abschnitt:
- Die durchschnittliche Wahrscheinlichkeit, welche unser trainiertes Modell auf dem Trainingsdatensatz schätzt, entspricht bei der logistischen Regression jeweils genau dem Anteil an Beobachtungen (im Trainingsdatensatz) mit Label \(y_i=1\).
- Wie bei der linearen Regression verwenden wir bei der logistischen Regression typischerweise Regularisierung, um dem Overfitting entgegenzuwirken. Von der Idee her funktioniert es genau gleich wie bei der linearen Regression.
Hier nun einige Aufgaben zum Modelltraining der logistischen Regression:
Decision Boundaries
Wir haben oben gesehen, dass das logistische Regressionsmodell wie folgt aussieht:
\[ p(y_i = 1 | \mathbf{x}_i) = \frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}} \] Wir schreiben dieses Modell nun etwas um, so dass wir am Schluss die so genannte Decision Boundary herleiten können. Die Decision Boundary ist in einem gewissen Sinn eine Grenze. Auf der einen Seite der Grenze ist der \(x\)-Wertebereich, für den \(\hat{y}_i=1\) vorhergesagt wird. Auf der anderen Seite der Grenze ist der \(x\)-Wertebereich, für den \(\hat{y}_i=0\) vorhergesagt wird. Die Decision Boundary bezieht sich also auf die Input-Variablen und zeigt uns, wo welche Vorhersagen gemacht werden.
Wir wollen obige Gleichung nun so umschreiben, dass wir auf der linken Seite die Odds haben. Die Odds sind definiert als die Erfolgswahrscheinlichkeit (\(p(y_i = 1 | \mathbf{x}_i)\)) dividiert durch die Misserfolgswahrscheinlichkeit (\(1-p(y_i = 1 | \mathbf{x}_i)\)).
Die mathematische Umformung ist wie folgt (optional bzw. nicht prüfungsrelevant):
\[ \begin{split} \frac{p(y_i = 1 | \mathbf{x}_i)}{1-p(y_i = 1 | \mathbf{x}_i)} &= \frac{\frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}}{1 - \frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}}\\ &= \frac{\frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}}{\frac{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}} - \frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}}\\ &= \frac{\frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}}{\frac{e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}}\\ &= \frac{1}{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}} \cdot \frac{1+e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}{e^{-(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}}\\ &= e^{(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})} \end{split} \]
In einem letzten Schritt können wir nun noch auf beiden Seiten den Logarithmus nehmen:
\[ \begin{split} \text{log}\left(\frac{p(y_i = 1 | \mathbf{x}_i)}{1-p(y_i = 1 | \mathbf{x}_i)}\right) &= \text{log}\left(e^{(w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip})}\right)\\ &= w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2} + \ldots + w_p \cdot x_{ip} \end{split} \]
Diese letzte Form wird Log-Odds genannt. Warum haben wir all das gemacht? Sie sehen, dass wir auf der rechten Seite nun wieder die altbekannte lineare Form haben. Diese letzte Gleichung ist darum nun einfach zu handhaben, wenn es um die Berechnung der Decision Boundary geht.
Eine Input-Variable
Schauen wir uns in einem ersten Schritt an, wie die Decision Boundary aussieht, wenn wir nur eine Input-Variable haben. Die Log-Odds sehen in diesem Fall wie folgt aus:
\[ \text{log}\left(\frac{p(y_i = 1 | \mathbf{x}_i)}{1-p(y_i = 1 | \mathbf{x}_i)}\right) = w_0 + w_1 \cdot x_{i1} \]
Wir haben oben bereits kurz den Threshold angesprochen. Hier wählen wir einen Threshold von 50% (0.5). Wir können das in obige Gleichung einsetzen und kriegen folgendes:
\[ \begin{split} \text{log}\left(\frac{0.5}{1-0.5}\right) &= w_0 + w_1 \cdot x_{i1}\\ \text{log}\left(1\right) &= w_0 + w_1 \cdot x_{i1}\\ 0 &= w_0 + w_1 \cdot x_{i1} \end{split} \]
Nun muss man verstehen, dass die Decision Boundary uns alle \(x\)-Werte gibt, welche zu einer Wahrscheinlichkeit führen, die genau dem Threshold entspricht. Hier in diesem einfachen Fall können wir nun einfach nach \(x_{i1}\) auflösen und kriegen folgendes:
\[ x_{i1} = -\frac{w_0}{w_1} \]
Puhhh, das war jetzt alles sehr theoretisch. Wir sind nun überfällig für ein Beispiel! Folgende App zeigt Ihnen, wie sich die Decision Boundary (vertikale Gerade) verändert, wenn Sie den Threshold verändern.
Wenn wir also nur eine Input-Variable haben, dann ist die Decision Boundary eine Vertikale an einem gewissen Punkt auf der \(x\)-Achse. Wo diese Vertikale ist, hängt vom gewählten Threshold ab.
Zwei Input-Variablen
Wenn wir zwei Input-Variablen haben, dann können wir die Decision Boundary, gegeben ein Threshold \(p^*\), wie folgt herleiten:
\[ \begin{split} \text{log}\left(\frac{p^*}{1-p^*}\right) &= w_0 + w_1 \cdot x_{i1} + w_2 \cdot x_{i2}\\ w_1 \cdot x_{i1} &= \text{log}\left(\frac{p^*}{1-p^*}\right) - w_0 - w_2 \cdot x_{i2}\\ x_{i1} &= \color{blue}{\frac{\text{log}\left(\frac{p^*}{1-p^*}\right) - w_0}{w_1}} - \color{red}{\frac{w_2}{w_1}} \cdot x_{i2} \end{split} \]
Diese Form sollte Ihnen irgendwie bekannt vorkommen! Die Decision Boundary kann bei zwei Input-Variablen als Gerade im Koordinatensystem mit \(x_{i1}\) auf der y-Achse und \(x_{i2}\) auf der x-Achse dargestellt werden. Die Gerade hat eine Konstante (blauer Teil) und eine Steigung (roter Teil).
Die Gerade repräsentiert alle Kombinationen von \(x_{i1}\) und \(x_{i2}\), für welche das Modell eine Wahrscheinlichkeit ausspuckt, die genau dem gesetzten Threshold entspricht.
Wichtig: wir sehen vom ein- und zweidimensionalen Beispiel, das die Decision Boundary immer linear ist. Darum gilt das logistische Regressionsmodell als einfaches Modell: es kann (im Prinzip) nur lineare Decision Boundaries fitten.
Lineare Separierbarkeit
Wir haben in obigem Beispiel gesehen, dass es keinen Threshold gibt, mit dem die Gerade die Datenpunkte perfekt separieren kann. In diesem Fall sind die Daten nicht linear separierbar. Da die logistische Regression nur lineare Decision Boundaries modellieren kann, ist sie etwas limitiert.
Wenn ein Datensatz nicht linear separierbar ist, dann kann das Hinzufügen von weiteren Variablen helfen. Das folgende Beispiel ist inspiriert durch HOML (p. 179):
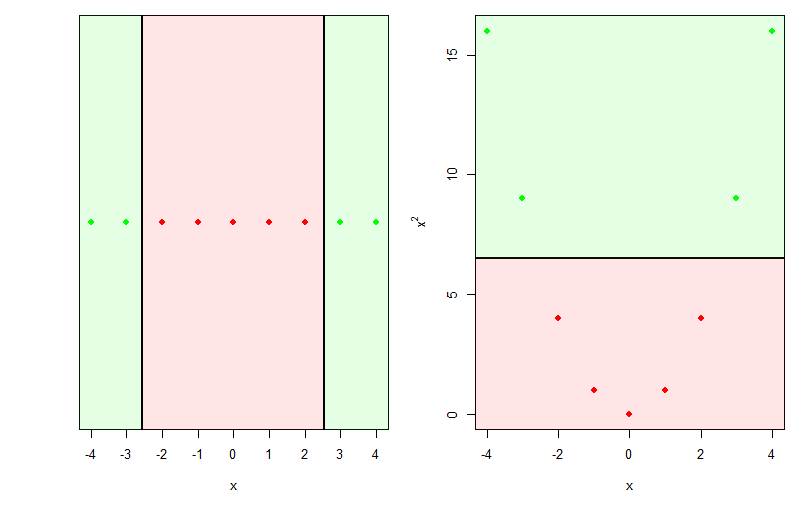
Im eindimensionalen Raum (links) mit nur einer \(x\) Variable ist der Datensatz nicht durch eine Gerade separierbar, weil wir sowohl im Wertebereich \(x<-2.5\) als auch im Wertebereich \(x>2.5\) positive Beobachtungen haben und dazwischen die negativen Beobachtungen.
Wenn wir nun aber als zweite Variable für jedes \(x\) den entsprechenden Wert des Quadrats von \(x\), also \(x^2\), hinzufügen, dann wird der Datensatz plötzlich linear separierbar. Wow, Mathematik ist cool :) Ein logistisches Modell mit zwei Input-Variablen, \(x\) und \(x^2\) kann diese Daten nun perfekt fitten.
Naive Bayes
Ein sehr einfaches, aber oft erstaunlich gut performendes Klassifikationsmodell ist Naive Bayes. Dieses Modell beruht auf dem Satz von Bayes, den Sie in Statistik 1 bereits kennen gelernt haben.
Nachfolgend ein Ausschnitt aus den Folien von Prof. Dr. Tobias Schoch zum Satz von Bayes (falls Sie etwas repetieren möchten):
Modellspezifikation
Das Modell kann folgendermassen spezifiziert werden:
\[ p(y_i = 1 | \mathbf{x}_i) = \frac{p(\mathbf{x}_i | y_i = 1) \cdot p(y_i = 1)}{p(\mathbf{x}_i)} \]
Es lohnt sich, hier kurz zu überlegen, was die Komponenten in dieser Modellspezifikation sind:
- Der linke Teil ist die Wahrscheinlichkeit, dass es sich bei der Email \(i\) um Spam handelt, gegeben die Input-Werte. Es ist dieselbe Wahrscheinlichkeit, die wir auch bei der logistischen Regression zu modellieren versuchen. Man nennt diese Wahrscheinlichkeit in der Fachsprache Posterior.
- Der erste Teil rechts oben, \(p(\mathbf{x}_i | y_i = 1)\), ist die Wahrscheinlichkeit der konkreten Input-Werte der Email \(i\), gegeben es handelt sich um eine Spam-Email. Unsere Input-Werte sind ja im Spam Filter die wichtigsten Wörter gemäss dem Bag-of-Words Ansatz. D.h. wir rechnen hier die Wahrscheinlichkeit der beobachteten Wörter in einer Email, gegeben es ist eine Spam Email. Dieser Teil wird Likelihood genannt.
- Der zweite Teil rechts oben, \(p(y_i = 1)\), ist die a-priori Wahrscheinlichkeit einer Spam Email. Was ist die generelle Wahrscheinlichkeit, dass eine Email Spam ist. Diese Wahrscheinlichkeit wird in der Fachsprache Prior genannt.
- Der Nenner auf der rechten Seite ist die Wahrscheinlichkeit, dass wir für eine Email \(i\) die konkreten Input-Werte beobachten, unabhängig davon ob es sich um Spam oder Ham handelt. Oft wird dieser Teil Evidence genannt. Mit dem Gesetz der totalen Wahrscheinlichkeit lässt sich die Evidence einfach rechnen:
\[ p(\mathbf{x}_i) = p(\mathbf{x}_i | y_i = 1) \cdot p(y_i = 1) + p(\mathbf{x}_i | y_i = 0) \cdot p(y_i = 0) \]
Wichtig: der zentrale Aspekt beim Naive Bayes Modell ist eine Unabhängigkeitsannahme. Warum brauchen wir eine Unabhängigkeitsannahme? Weil es äusserst schwierig ist, die Likelihood \(p(\mathbf{x}_i | y_i = 1)\) aus Daten zu schätzen. Für eine kurze Email mit dem Text “Hallo, wie geht es dir?” müssten wir die gemeinsame Wahrscheinlichkeit (Joint Probability), dass genau diese 5 Worte gemeinsam in einer Spam Email vorkommen und alle anderen Wörter nicht, schätzen. Das ist enorm schwierig. Darum machen wir folgende Unabhängigkeitsannahme:
\[ p(\mathbf{x}_i | y_i = 1) = p(x_{i1} | y_i = 1) \cdot p(x_{i2} | y_i = 1) \cdot \ldots \cdot p(x_{ip} | y_i = 1) \cdot \]
Anstatt die gemeinsame Wahrscheinlichkeit müssen wir hier nur die Randwahrscheinlichkeiten für jedes Wort schätzen und diese dann miteinander multiplizieren.
Das ist eine ziemliche Vereinfachung, denn wir nehmen nun an, dass beispielsweise die Wahrscheinlichkeit des Worts “geht” (gegeben eine Spam Email) unabhängig von der Wahrscheinlichkeit des Worts “wie” (gegeben eine Spam Email) ist. Wenn Sie daran denken, wie oft in einem Text die Phrase “wie geht…” vorkommt, dann dürften die beiden Wahrscheinlichkeiten kaum unabhängig voneinander sein. Aber in der Praxis funktioniert diese Annahme trotzdem erstaunlich gut.
Wenn wir an den Bias-Variance-Tradeoff denken, dann passiert mit dieser Unabhängigkeitsannahme folgendes: wir erhöhen den Bias des Modells willentlich, indem wir diese Unabhängigkeitsannahme machen. Gleichzeitig reduzieren wir jedoch die Varianz substantiell, da das Modell so viel einfacher wird. Oft ist die Reduktion der Varianz grösser als der Anstieg des Bias, weshalb dieses Modell in der Praxis oft gut funktioniert.
Modelltraining
Aus obigen Ausführungen sehen wir, dass wir folgende Wahrscheinlichkeiten aus den Daten schätzen müssen:
- Priors \(p(y_i = 1)\) und \(p(y_i = 0)\)
- Für alle Spam Emails die Randwahrscheinlichkeiten \(p(x_{i1} | y_i = 1)\), \(p(x_{i2} | y_i = 1)\), etc.
- Für alle Ham Emails die Randwahrscheinlichkeiten \(p(x_{i1} | y_i = 0)\), \(p(x_{i2} | y_i = 0)\), etc.
Die Priors können ganz einfach als relative Häufigkeiten von Spam bzw. Ham Emails im Trainingsdatensatz geschätzt werden.
Auch die Randwahrscheinlichkeiten lassen sich im Spam Filter Beispiel einfach schätzen. Für jedes Wort im Bag-of-Words (z.B. “price”) schätzen Sie die relative Häufigkeit in allen Spam Emails und in allen Ham Emails.
Im Spam Filter Beispiel haben wir nur kategorische (qualitative) Input-Variablen, für die sich die Randwahrscheinlichkeiten als relative Häufigkeiten schätzen lassen. Es ist aber auch möglich, quantitative Input-Variablen zu haben, z.B. die Anzahl Worte in einer Email. In diesem Fall nehmen Sie alle Spam Emails und schätzen eine Normalverteilung für die Anzahl Worte in den Spam Emails. Mit der geschätzten Normalverteilung können Sie dann ebenfalls eine Randwahrscheinlichkeit (genauer gesagt einen Wert der Dichte) für eine bestimmte Anzahl Worte rechnen. Das Selbe tun Sie selbstverständlich auch mit den Ham Emails.
Beispiel
Der Einfachheit halber berechnen wir hier ein Spam Filter Beispiel mit nur zwei Input-Variablen. Die beiden Variablen beschreiben, ob das Wort “afford” bzw. “price” in einer Email vorkommen oder nicht.
Berechnen wir als erstes die Priors.
Als nächstes rechnen wir die Randwahrscheinlichkeiten für die Spam Emails. In den 1277 Spam Emails enthalten 40 Emails das Wort “afford” und 223 Emails das Wort “price”.
Wichtig: die Wahrscheinlichkeit, dass das Wort “afford” bzw. “price” nicht vorkommt in einer Spam Email haben wir so indirekt auch bereits berechnet:
\[ p(afford_i = 0 | y_i = 1) = 1 - p(afford_i = 1 | y_i = 1) = 1 - 0.03 = 0.97 \] \[ p(price_i = 0 | y_i = 1) = 1 - p(price_i = 1 | y_i = 1) = 1 - 0.17 = 0.83 \]
Als letztes rechnen wir nun noch die Randwahrscheinlichkeiten für die Ham Emails. In den 2723 Ham Emails enthalten 27 Emails das Wort “afford” und 134 Emails das Wort “price”.
Auch hier können die Wahrscheinlichkeiten für das “Gegenereignis” einfach gerechnet werden:
\[ p(afford_i = 0 | y_i = 0) = 1 - p(afford_i = 1 | y_i = 0) = 1 - 0.01 = 0.99 \] \[ p(price_i = 0 | y_i = 0) = 1 - p(price_i = 1 | y_i = 0) = 1 - 0.05 = 0.95 \]
Nun wollen wir die Posterior Wahrscheinlichkeit berechnen, dass eine Email, welche sowohl das Wort “afford” als auch das Wort “price” enthält, eine Spam Email ist:
\[ \begin{split} p(y_i = 1 | afford_i = 1, price_i = 1) &= \frac{p(afford_i = 1 | y_i = 1) \cdot p(price_i = 1 | y_i = 1) \cdot p(y_i = 1)}{p(afford_i = 1, price_i = 1)}\\ &= \frac{0.03 \cdot 0.17 \cdot 0.32}{0.03 \cdot 0.17 \cdot 0.32 + 0.01 \cdot 0.05 \cdot 0.68}\\ &= \frac{0.001632}{0.001632 + 0.00034}\\ &= 0.83 \end{split} \]
Wow, gegeben, dass die beiden Worte “afford” und “price” in einem Email vorkommen, sind wir also ziemlich sicher, dass es sich um eine Spam Email handelt.
Aufgabe: rechnen Sie die Wahrscheinlichkeit, dass es sich bei einer Email um Spam handelt, wenn nur das Wort “afford” vorkommt, nicht aber das Wort “price”. Lösung: 0.55
Evaluation
Dieser gesamte Abschnitt bezieht sich auf das binäre Klassifikationsproblem Wir werden uns die Modellgütemasse für den Fall einer Zielvariable mit mehr als zwei Kategorien zu einem späteren Zeitpunkt anschauen.
Die allermeisten Klassifikationsmodelle geben uns für eine Beobachtung \(\mathbf{x}_i\) die Wahrscheinlichkeit, dass \(y_i = 1\), also \(p(y_i = 1 | \mathbf{x}_i)\).
Doch wie kommen wir eigentlich von diesen Wahrscheinlichkeiten zu einer richtigen Vorhersage? Wir müssen zuerst einen Threshold wählen. Im einfachsten Fall ist der Threshold 0.5 und wir erstellen die Vorhersagen wie folgt:
- Wenn \(p(y_i = 1 | \mathbf{x}_i) \geq 0.5\), dann ist unsere Vorhersage \(\hat{y}_i = 1\).
- Wenn \(p(y_i = 1 | \mathbf{x}_i) < 0.5\), dann ist unsere Vorhersage \(\hat{y}_i = 0\).
Im folgenden Datensatz haben wir 40 Beobachtungen. Für jede Beobachtung haben wir den wahren Wert der Zielvariable (y), die vorhergesagte Wahrscheinlichkeit des Klassifikationsmodells (prob) sowie die Vorhersagen für einen Threshold von 0.5 (pred):
y prob pred
1 0.95721924 1
1 0.95721924 1
1 0.95721924 1
1 0.90284298 1
1 0.90284298 1
1 0.90284298 1
1 0.90284298 1
1 0.88629832 1
1 0.88629832 1
1 0.88629832 1
1 0.84579393 1
1 0.84579393 1
0 0.84579393 1
1 0.79421077 1
1 0.79421077 1
0 0.79421077 1
1 0.61580323 1
1 0.61580323 1
0 0.61580323 1
0 0.61580323 1
1 0.57895423 1
1 0.39964340 0
0 0.39964340 0
0 0.39964340 0
1 0.21658577 0
0 0.21658577 0
0 0.21658577 0
0 0.21658577 0
0 0.21658577 0
1 0.10299336 0
0 0.10299336 0
0 0.10299336 0
0 0.10299336 0
0 0.10299336 0
0 0.10299336 0
0 0.04551533 0
0 0.04551533 0
0 0.04551533 0
0 0.01941990 0
0 0.01941990 0Die ersten beiden Spalten dieses Datensatzes sind als Data Frame unter dem Name eval_data gespeichert und werden in den folgenden Code Blocks verwendet.
Accuracy
Das einfachste Modellgütemass für das Klassifikationsproblem ist die Accuracy. Bei der Accuracy zählen wir die Anzahl korrekt gemachter Vorhersagen und dividieren durch die Anzahl Beobachtungen.
# Threshold
thres <- 0.5
# Vorhersage basierend auf Threshold
eval_data <-
eval_data %>%
mutate(
y = factor(y),
pred = factor(ifelse(prob >= thres, 1, 0))
)
# Accuracy mit Base R
sum(eval_data$y == eval_data$pred) / nrow(eval_data)
# Accuracy via tidymodels
accuracy(eval_data, y, pred)Wir sehen, dass die Accuracy hier 0.825 (oder 82.5%) beträgt. Wichtig ist, dass Sie bei Verwendung der Funktion accuracy() aus tidymodels sowohl die Zielvariable als auch die Vorhersagen vorher in einen Faktor transformieren.
Konfusionsmatrix
Sobald wir mithilfe eines Thresholds “harte” Vorhersagen berechnet haben, können wir die Klassifikationsresultate mit einer Konfusionsmatrix darstellen. Die generelle Form der Konfusionsmatrix sieht wie folgt aus:
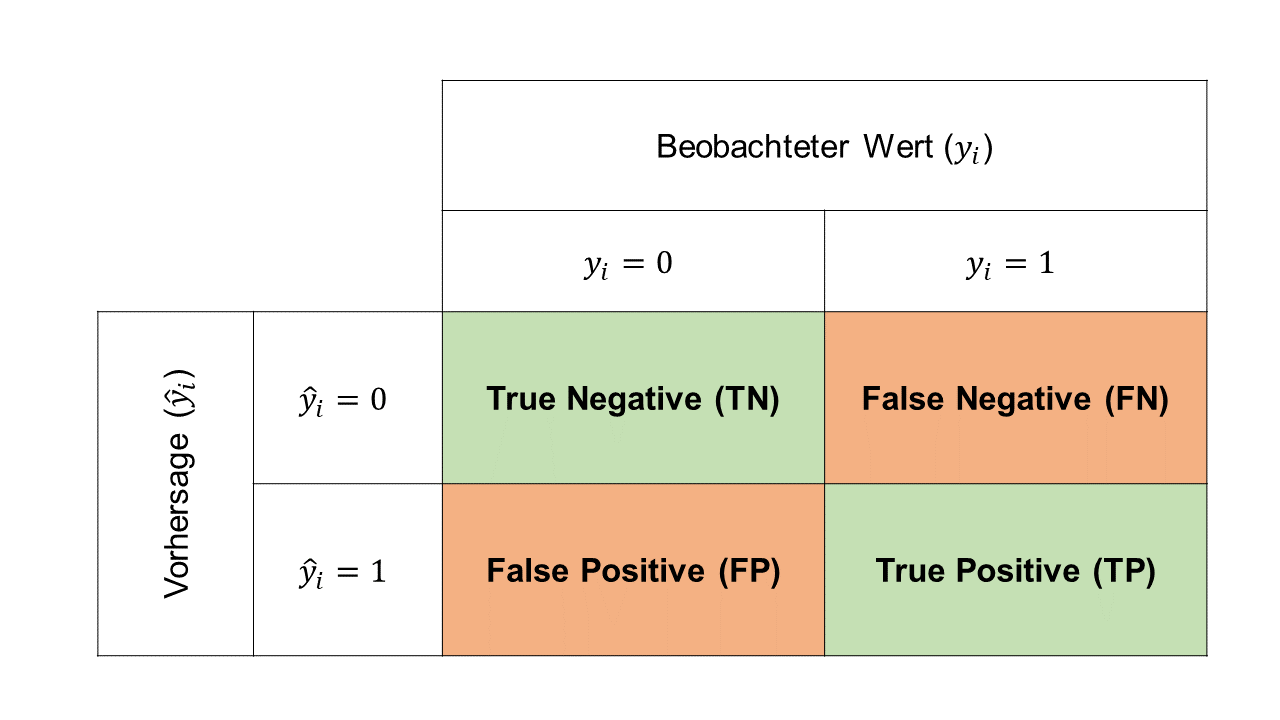
Die vier Zellen der Matrix repräsentieren die vier möglichen Outcomes:
- True Negative (TN): korrekte Vorhersage einer Beobachtung mit \(y_i = 0\). Beispiel: Spam Filter klassifiziert eine Ham Email korrekt als Ham (nicht-Spam).
- True Positive (TP): korrekte Vorhersage einer Beobachtung mit \(y_i = 1\). Beispiel: Spam Filter klassifiziert Spam Email korrekt als Spam.
- False Negative (FN): inkorrekte Vorhersage einer Beobachtung mit \(y_i = 1\). Beispiel: Spam Filter klassifiziert eine Spam Email inkorrekt als Ham (nicht-Spam).
- False Positive (FP): inkorrekte Vorhersage einer Beobachtung mit \(y_i = 0\). Beispiel: Spam Filter klassifiziert eine Ham Email inkorrekt als Spam.
Aufgabe: Überlegen Sie sich kurz, welcher Fehler im Beispiel des Spam Filters schlimmer ist:
- False Negative: der Filter klassifiziert eine Spam Email als Ham.
- False Positive: der Filter klassifiziert eine Ham Email als Spam.
Mit der Funktion table() aus Base R können wir uns die Konfusionsmatrix in R ausgeben lassen. Damit wir genau die Anordnung wie in obiger Abbildung kriegen, übergeben wir der Funktion zuerst die Vorhersagen eval_pred$pred und erst dann die wahren Werte der Zielvariable eval_data$y. Mit dnn = c("pred","true") beschriften wir die Dimensionen der Tabelle.
# Threshold
thres <- 0.5
# Vorhersage basierend auf Threshold
eval_data <-
eval_data %>%
mutate(pred = ifelse(prob >= thres, 1, 0))
# Konfusionsmatrix (Base R)
table(eval_data$pred, eval_data$y, dnn = c("pred","true"))Wir sehen, dass unser Modell 4 False Positive und 3 False Negative Fehler macht.
Sensitivity und Specificity
Wie oben gesehen kriegen wir mit der Accuracy den Anteil korrekter Vorhersagen. Oft möchte man die Klassifikationsresultate etwas genauer aufsplitten. Dazu werden die Gütemasse Sensitivity und Specificity verwendet:
- Die Sensitivity ist der Anteil korrekter Vorhersagen unter allen positiven Beobachtungen. Beispiel: was ist der Anteil korrekt als Spam klassifizierter Emails gemessen an allen Spam Emails? Die Formel ist wie folgt: \(\text{Sensitivity} = \frac{TP}{(TP + FN)}\). Die Sensitivity wird manchmal auch True Positive Rate oder Recall genannt.
- Die Specificity ist der Anteil korrekter Vorhersagen unter allen negativen Beobachtungen. Beispiel: was ist der Anteil korrekt als Ham klassifizierter Emails gemessen an allen Ham Emails? Die Formel ist wie folgt: \(\text{Specificity} = \frac{TN}{(TN + FP)}\). Die Specificity wird manchmal auch True Negative Rate genannt.
In folgendem Code Block rechnen wir die Accuracy, Sensitivity und Specificity mit R. Wichtig: das Argument event_level = "second" in den Funktionen sens() und spec() definiert, dass das zweite Faktorlevel die Kategorie ist, die uns hauptsächlich interessiert (also \(y_i=1\)).
# Threshold
thres <- 0.5
# Vorhersage basierend auf Threshold
eval_data <-
eval_data %>%
mutate(
y = factor(y),
pred = factor(ifelse(prob >= thres, 1, 0))
)
# Konfusionsmatrix (Base R)
table(eval_data$pred, eval_data$y, dnn = c("pred","true"))
# Accuracy via tidymodels
eval_data %>%
accuracy(y, pred)
# Sensitivity (Base R)
sum(eval_data$y == 1 & eval_data$pred == 1) / sum(eval_data$y == 1)
# Sensitivity (tidymodels)
eval_data %>%
yardstick::sens(y, pred, event_level = "second")
# Specificity (tidymodels)
eval_data %>%
yardstick::spec(y, pred, event_level = "second")Aufgabe: Verändern Sie in obigem Code den Threshold einmal zu 0.8 und einmal zu 0.3. Was passiert mit der Accuracy, der Sensitivity und der Specificity?
Wir haben mithilfe von obigem Code feststellen können, dass sich die Modellgütemasse verändern, wenn wir den Threshold verändern. Grundsätzlich gilt folgendes:
- Die Accuracy ist maximal für einen Threshold von 0.5.
- Wenn wir den Threshold senken, dann erhöht sich die Sensitivity (allerdings auf Kosten der Specificity). Warum? Die Senkung des Thresholds führt einerseits zu mehr True Positives, aber auch zu mehr falschen Vorhersagen von \(\hat{y}_i=1\), also mehr False Positives.
- Wenn wir den Threshold erhöhen, dann erhöht sich die Specificity (allerdings auf Kosten der Sensitivity). Warum? Die Erhöhung des Thresholds führt einerseits zu mehr True Negatives, aber auch zu mehr False Negatives. “You can’t have it both ways!”
Folgende Abbildung zeigt die Accuracy, die Sensitivity und die Specificity für viele verschiedene Thresholds zwischen 0 und 1:
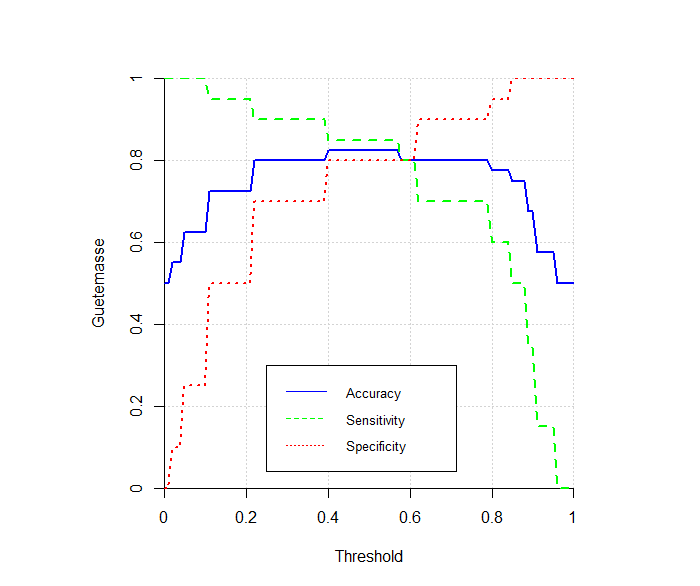
Für reale Datenbeispiele sind die Kurven smoother.
Doch wie machen wir nun da eine gute Entscheidung bezüglich des Thresholds? In praktisch jedem Praxisproblem ist entweder die Sensitivity oder die Specificity wichtiger. Dazu braucht es manchmal etwas Domain Knowledge. Wir wählen den Threshold dann so, dass wir mit dem Tradeoff zwischen Sensitivity und Specificity leben können.
Hier ein paar Beispiele:
- Beim Spam Filter ist es mir wichtiger, dass ich möglichst keinen False Positive Fehler mache (Ham verschwindet im Spam Folder). Hier ist mir also die Specificity wichtiger. Darum wähle ich tendenziell einen Threshold grösser als 0.5.
- Bei der Vorhersage einer Krankheit (\(y_i = 1\)) ist der False Negative Fehler wesentlich schlimmer (kranke Person wird als gesund klassifiziert). Hier ist mir also die Sensitivity wichtiger. Darum wähle ich tendenziell einen Threshold kleiner als 0.5 und “gehe auf Nummer sicher”.
Aufgabe: Überlegt euch kurz anhand folgender Beispiele, welcher Fehler schlimmer ist und wie ihr euch dementsprechend bezüglich Threshold entscheiden würdet.
- Eine Bank möchte mit einem Modell die Zahlungsfähigkeit von Kundinnen und Kunden vorhersagen.
- Die Polizei möchte mit einem Modell vorhersagen, ob eine Person in den nächsten 6 Monaten eine kriminelle Tat begeht.
ROC Kurve
Die ROC Kurve, das bekannteste Konzept zur Messung der Klassifikationsgüte, wurde entwickelt, weil es unbefriedigend ist, dass die Klassifikationsgüte (z.B. Accuracy, Sensitivity oder Specificity) vom gewählten Threshold abhängt. Die ROC Kurve wurde ursprünglich in der Kommunikationstheorie entwickelt und ROC steht für receiver operating characteristic.
Jeder Punkt auf der ROC Kurve zeigt den Wert der Sensitivity und der Specificity für einen bestimmten Threshold, wobei der Threshold nicht explizit in der Grafik dargestellt wird. Ihr könnt es euch folgendermassen vorstellen:
- Für jeden möglichen Threshold, z.B. \(\{0, 0.01, 0.02, 0.03, \ldots, 0.98, 0.99, 1.0\}\), wird sowohl die Sensitivity als auch die Specificity berechnet.
- Dann sortieren wir die Sensitivity-Specificity Paare nach aufsteigender Sensitivity.
- Zum Schluss plotten wir die sortierten Punkte als Kurve. Damit der Plot besser interpretierbar ist, plotten wir auf der x-Achse \(1 - \text{Specificity}\), was nichts anderes als die False Positive Rate ist.
Hier der tidymodels Code dazu:
# y in einen Faktor umwandeln
eval_data <-
eval_data %>%
mutate(y = factor(y))
# Werte für die ROC Kurve
roc_curve(eval_data, y, prob, event_level = "second")
# ROC Kurve
autoplot(roc_curve(eval_data, y, prob, event_level = "second"))Zentrale Punkte für die Interpretation von ROC Kurven:
- Hat ein Modell eine ROC Kurve, die durch den Punkt ganz links oben geht, dann haben wir ein perfektes Modell gefunden. Warum? Für dieses Modell gibt es einen Threshold, mit dem sowohl die Sensitivity als auch die Specificity 1 sind (Achtung: wenn die Specificity 1 ist, dann ist \(1 - \text{Specificity} = 0\)). Das Modell macht also keine Vorhersagefehler!
- Die gestrichelte Diagonale entspricht einem Modell, dessen Vorhersagen nicht besser als ein Münzwurf sind. Unser Modell sollte sich also immer klar von der Diagonalen abheben, nur dann hat es wirklich einen Nutzen.
- Wir können die ROC Kurve auch mit einer einzigen Zahl zusammenfassen, nämlich der Fläche unter der ROC Kurve. Man nennt dieses Mass ROC AUC (Area Under Curve). Wenn die ROC Kurve durch den Punkt links oben geht, dann ist ROC AUC 1.0 (perfektes Modell). Wenn unser Modell aber nicht besser als ein Münzwurf performt, dann ist ROC AUC ungefähr 0.5 (Modell ab in den Kübel).
- Die ROC Kurve eignet sich gut, um Modelle zu vergleichen. Warum? Verschiedene Modelle haben unterschiedliche Thresholds mit denen sie am besten performen. Die ROC Kurven bzw. ROC AUC erlauben einen direkten Vergleich von Modellen, da der Effekt des Thresholds nicht mehr reinspielt, weil alle Thresholds berücksichtigt werden.
Imbalance
Es gibt beim Klassifikationsproblem eine grosse Herausforderung, welche in der Praxis oft auftritt. Nämlich das Problem einer Imbalance (Unausgewogenheit) in der Zielvariable \(y_i\). Es kommt sehr häufig vor, dass die “positive” Klasse (\(y_i=1\)), also die Klasse, an der wir wirklich interessiert sind, weniger häufig vorkommt als die “negative” Klasse (\(y_i=0\)). Beispiel: Zahlungsunfähigkeit, Krankheit, gewaltsames Video auf YouTube, etc.
In diesem Fall ist die Accuracy ein ganz schlechtes Gütemass. Warum seht ihr an folgendem Beispiel:
Aufgabe: Stellen Sie sich vor, dass wir einen Datensatz mit Angaben zu 1000 Patientinnen und Patienten haben. 33 dieser 1000 Patientinnen und Patienten haben eine seltene Krankheit, die wir mit einem Modell vorhersagen möchten.
- Stellen Sie die Konfusionsmatrix auf für ein simples Modell, das immer \(\hat{y}_i=0\) (also keine Krankheit) vorhersagt.
- Rechnen Sie die Accuracy basierend auf den Zahlen in der Konfusionsmatrix. Was fällt Ihnen auf?
- Rechnen Sie nun die Sensitivity und Specificity basierend auf den Zahlen in der Konfusionsmatrix.
Wir sehen also, dass es im Falle einer Imbalance nie eine gute Idee ist, die Accuracy als Gütemass zu verwenden. Doch wir haben ein grundsätzlicheres Problem: unser ML-Modell kann unter Umständen zu wenig gut von den “positiven” (raren) Trainingsbeobachtungen lernen, da es einfach nicht eine genügend grosse Anzahl davon gibt. Das Modell fokussiert in diesem Fall zu stark auf die häufige Kategorie und vernachlässigt die rare Kategorie.
Um dieses Problem zu lösen gibt es zwei Arten von Lösungen:
- Sampling Techniken: wir können einerseits ein Undersampling für die häufige Kategorie oder ein Oversampling für die rare Kategorie machen. Ganz einfach gesagt, entfernen wir beim Undersampling zufällig Beobachtungen, welche der häufigen Kategorie angehören bis die Imbalance weniger stark ist. Beim Oversampling generieren wir (zufällig) neue Beobachtungen für die rare Kategorie bis die Imbalance weniger stark ist.
- Gewichtung in Kostenfunktion: Wir können Trainingsbeobachtungen, welche der raren Kategorie angehören, in der Berechnung der Kostenfunktion stärker gewichten.
Persönlich bevorzuge ich die zweite Variante, weil sie aus meiner Sicht eleganter ist. In praktischen Problemen lohnt es sich jedoch immer etwas auszuprobieren, was am besten funktioniert.
Weitere Ressourcen zum Thema Imbalance:
Precision-Recall Kurve
Optional: Die ROC Kurve (und ROC AUC) sind die am häufigsten verwendeten Techniken, um die Klassifikationsmodelle zu evaluieren. Wenn aber die “positive” Kategorie sehr selten vorkommt (also eine Imbalance vorherrscht) und/oder der False Positive Fehler für das vorliegende Problem wichtiger ist, dann gibt es eine Alternative zur ROC Kurve, nämlich die Precision-Recall Kurve.
Das Mass Recall haben wir bereits kennen gelernt, denn es ist nichts anderes als die Sensitivity. Zur Repetition: \(\text{Recall} = \frac{TP}{(TP + FN)}\). Dieses Mass bezieht sich nur auf die zweite Spalte der Konfusionsmatrix, berücksichtigt also nur die Beobachtungen, die tatsächlich der Kategorie 1 angehören (\(y_i=1\)).
Das Mass Precision bezieht sich auf die zweite Zeile der Konfusionsmatrix, berücksichtigt also nur die Beobachtungen, für die unser Modell 1 vorhersagt (\(\hat{y}_i=1\)). Die Formel ist wie folgt: \(\text{Precision} = \frac{TP}{(TP + FP)}\). Auf den Spam Filter angewendet beantwortet die Precision die Frage “Wie viele unserer Spam Vorhersagen sind korrekt?”.
Sie sehen, dass die beiden Masse, Precision und Recall, sich hauptsächlich mit der positiven Kategorie befassen. Die True Negatives (TN) kommen in den beiden Formeln gar nicht vor.
Wichtig: wie bei der ROC Kurve bzw. Sensitivity und Specificity gibt es einen Tradeoff zwischen Precision und Recall. Eine höhere Precision führt in der Regel zu einem tieferen Recall. Das sieht man auch gut anhand folgender Abbildung, die Precision und Recall für verschiedene Thresholds zeigt:
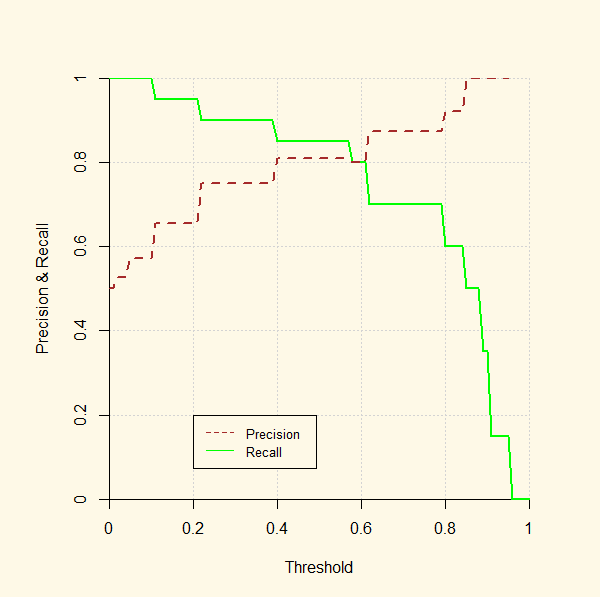
Manchmal will man die Precision und Recall Werte zu einem Score verbinden. Dazu kann man den harmonischen Mittelwert rechnen, den man F1 Score nennt:
\[ \text{F1} = \frac{2}{\frac{1}{\text{Precision}} + \frac{1}{\text{Recall}}} \] Warum ein harmonischer Mittelwert? Weil dieser einen tiefen Wert für Precision oder Recall stärker “bestraft” als der arithmetische Mittelwert. Das führt dazu, dass das F1 Score in der Tendenz nur hoch ist, wenn sowohl Precision als auch Recall hoch ist.
Hier nun noch der R-Code, um Precision und Recall zu rechnen:
# Threshold
thres <- 0.5
# Vorhersage basierend auf Threshold
eval_data <-
eval_data %>%
mutate(
y = factor(y),
pred = factor(ifelse(prob >= thres, 1, 0))
)
# Precision (tidymodels)
eval_data %>%
yardstick::precision(y, pred, event_level = "second")
# Recall (= Sensitivity) (tidymodels)
eval_data %>%
yardstick::recall(y, pred, event_level = "second")
# Werte für die Precision-Recall Kurve
pr_curve(eval_data, y, prob, event_level = "second")
# Precision-Recall Kurve
autoplot(pr_curve(eval_data, y, prob, event_level = "second"))Die letzten beiden Zeilen Code zeigen, wie man (ähnlich wie bei der ROC Kurve) Precision gegen Recall plotten kann, ohne die Thresholds direkt in der Grafik zu zeigen.
Spam Filter
Wir haben uns die Daten, welche wir für das Training des Spam Filters verwenden werden, im ersten Abschnitt bereits angeschaut und in ein Data Frame Format umgewandelt. Ein grosser Teil der ML Pipeline ist hier nicht nötig, da der Datensatz bereits in der richtigen Form und auch bereits in einen Trainings- und Testdatensatz aufgeteilt ist. Darum steigen wir hier direkt im Modellierungsteil ein.
Logistische Regression
Als erstes splitten wir den Trainingsdatensatz in 10 Folds (10-Fold Cross Validation), die wir für das Hyperparameter Tuning, aber auch für die Modellevaluation verwenden werden. Wichtig: auch hier fassen wir den Testdatensatz bis ganz am Schluss nicht an. Sie sehen hier zwei interessante Argumente in der vfold_cv() Funktion: repeats erlaubt Ihnen, die 10-Fold CV mehr als einmal durchzuführen, um präzisere Resultate zu erhalten. Wie bei einer klassischen Schätzung erhalten Sie so mehr Datenpunkte und können die Modellgüte genauer schätzen. Das Argument strata = y sagt der Funktion, dass sie die Folds proportional nach den Anteilen in der Variable y erstellen soll. Das heisst, jeder Fold wird rund 33% Spam Emails und 67% Ham Emails enthalten. Wir kriegen einen sogenannten stratifizierten Split.
# Seed für Reproduzierbarkeit
set.seed(123)
# 10-fold CV
folds <- vfold_cv(train, v = 10, repeats = 1, strata = y)Als nächstes setzen wir das Logistische Regressionsmodell auf. Anstelle der linear_reg() Funktion (siehe ML Pipeline Kapitel) verwenden wir hier nun die logistic_reg() Funktion und spezifizieren, dass wir hier (aus Performance Gründen - so dass das Tuning etwas schneller geht) nur penalty als Hyperparameter tunen wollen. Mit mixture = 1 definieren wir bereits hier, dass ein LASSO Modell gerechnet werden soll.
# Logistische Regression
lr_mod <-
logistic_reg(penalty = tune(), mixture = 1) %>%
set_engine("glmnet")Wir brauchen hier kein Recipe, da die Daten schon im korrekten Format sind. Darum sieht der Workflow hier etwas anders aus als wir es uns gewohnt sind: wir verwenden den add_formula() Layer anstelle des add_recipe() Layers. Der add_formula() Layer ist nötig, weil spezifiziert werden muss, was die Zielvariable ist und welche Variablen als Input-Variablen verwendet werden sollen. Dieser Schritt war im ML Pipeline Kapitel integriert in das Recipe. Mit y ~ . definieren wir hier, dass y die Zielvariable ist und alle anderen Variablen als Input verwendet werden sollen.
# Workflow
lr_workflow <-
workflow() %>%
add_model(lr_mod) %>%
add_formula(y ~ .)Da wir hier nur penalty als Hyperparameter betrachten ist der Tuning Grid eindimensional. Wir testen hier Werte zwischen 0.00001 (1e-05) und 10 (1e+01).
# Tuning Grid
lr_grid <- expand.grid(penalty = 10^seq(-5, 1, by = 1))
# Wie sieht Grid aus?
print(lr_grid)## penalty
## 1 1e-05
## 2 1e-04
## 3 1e-03
## 4 1e-02
## 5 1e-01
## 6 1e+00
## 7 1e+01Hier nun der wichtige Schritt des Model Fittings. Mit resamples = folds übergeben wir der tune_grid() Funktion die 10 (CV) Folds. control = control_grid(save_pred = TRUE) speichert die Vorhersagen für die verschiedenen möglichen Hyperparameterwerte. Warum speichern wir diese Vorhersagen? Weil wir sie verwenden werden für die Berechnung der Modellgüte.
Die folgende Abbildung zeigt nochmals das Prinzip der Cross Validation (hier mit 5 Folds) für eine gegebene Hyperparameter Spezifikation (z.B. penalty = 0.1). Wir haben pro Split einen Fold, der nicht für das Training verwendet wird. Die Vorhersagen auf diesem Test Fold speichern wir im unten stehenden Code. Aus der Abbildung ist ersichtlich, dass wir so für jede Beobachtung im Trainingsdatensatz genau eine Vorhersage kriegen. Diese Vorhersagen werden verwendet, um die Modellgüte zu berechnen.

Welche Modellgütemasse verwenden wir hier überhaupt? Wir verwenden hier die Accuracy und ROC AUC und spezifizieren das mit metrics = metric_set(accuracy, roc_auc).
# Tuning / Model Fitting
lr_res <-
lr_workflow %>%
tune_grid(
resamples = folds,
grid = lr_grid,
control = control_grid(save_pred = TRUE),
metrics = metric_set(accuracy, roc_auc))Nun sortieren wir den Cross-Validation Output nach dem Modellgütekriterium ROC AUC, so dass wir den besten Hyperparameterwert zuoberst sehen:
# Wir sortieren die Hyperparameter Spezifikationen nach ROC AUC
lr_res %>%
show_best(metric = "roc_auc", n = 7) %>%
arrange(desc(mean))Wow! Mit penalty = 0.001 kriegen wir eine Fläche unter der ROC-Kurve (ROC AUC) von beinahe 1.0 (siehe Spalte mean). Die CV-Resultate zeigen, dass unser logistisches Regressionsmodell die Emails fast perfekt klassifiziert. Die Werte in der Spalte mean sind gemittelt über die 10 Test Folds. Die Spalte std_err gibt zusätzlich den Standardfehler an, da es sich mit den mittleren ROC AUC Werte ja um eine Schätzung handelt.
Selbstverständlich können wir die Tuning Resultate auch plotten:
# Plot der Resultate
lr_res %>%
collect_metrics() %>%
filter(.metric == "roc_auc") %>%
ggplot(aes(x = penalty, y = mean)) +
geom_point() +
geom_line() +
labs(x = "Penalty", y = "AUC ROC") +
scale_x_log10() +
theme_bw()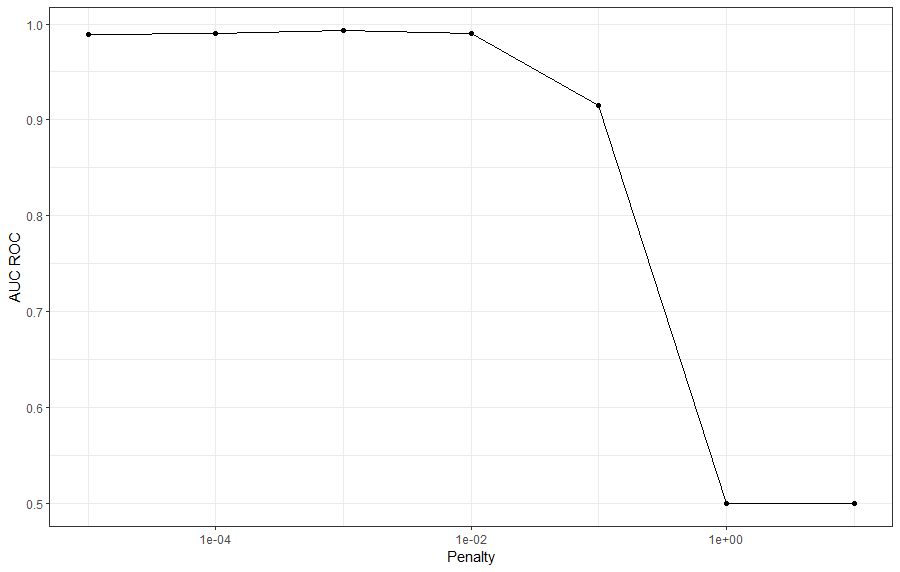
Nun wählen wir das beste Modell mit der Funktion select_best() und speichern es im Objekt lr_best:
# Wir wählen das besten Modell
lr_best <-
lr_res %>%
select_best(metric = "roc_auc")Wir haben oben bereits gesehen, dass das ROC AUC Gütemass sehr hoch ist. Dementsprechend erwarten wir, dass die ROC Kurve mehr oder weniger direkt zur linken oberen Ecke des Diagramms verläuft. Plotten wir doch die ROC Kurve und lassen uns visuell davon überzeugen. Mit collect_predictions() reduzieren wir auf die Vorhersagen unseres besten Modells. Wir übergeben die Vorhersagen dann der Funktion roc_curve(). y ist ein Faktor mit den wahren Werten für die Zielvariable (Spam oder Ham) und .pred_Spam ist die vorhergesagte Wahrscheinlichkeit für Spam.
# Resultate vorbereiten für ROC Kurve
lr_auc <-
lr_res %>%
collect_predictions(parameters = lr_best) %>%
roc_curve(y, .pred_Spam, event_level = "second") %>%
mutate(model = "Logistic Regression")
# ROC Kurve
autoplot(lr_auc)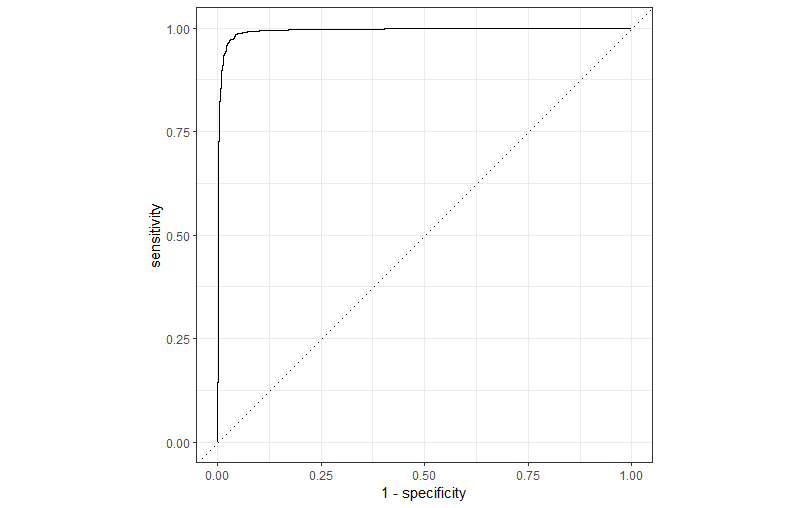
Ha! Tatsächlich ein fantastisches Modell. Sie sehen hier: das Spam Klassifikationsproblem gilt als grösstenteils gelöst!
Nun rechnen wir nur noch den letzten Fit auf dem ganzen Trainingsdatensatz und mit dem optimalen Hyperparameterwert:
# Last Fit
# Last Fit Spezifikation (optimale Hyperparameter Werte)
last_lr_mod <-
logistic_reg(penalty = 0.001, mixture = 1.0) %>%
set_engine("glmnet")
# Workflow anpassen (optimales Modell)
last_lr_workflow <-
lr_workflow %>%
update_model(last_lr_mod)
# Last Fit (auf ganzem Trainingsdatensatz)
last_lr_fit <-
last_lr_workflow %>%
fit(data = train)Wir können die ersten 10 Parameter des Last Fits wie folgt anschauen:
# Parameter Last Fit
last_lr_fit %>%
extract_fit_parsnip() %>%
tidy() %>%
print(n = 10)Und zum Schluss möchten wir ja nun noch wissen, welche Wörter den stärksten positiven oder negativen Einfluss auf die Spam Wahrscheinlichkeit haben:
# Variable importance
# Barplot der Parameter
last_lr_fit %>%
extract_fit_parsnip() %>%
tidy() %>%
filter(abs(estimate) > 1.0 & term != "(Intercept)") %>%
mutate(pos = estimate >= 0) %>%
arrange(desc(estimate)) %>%
ggplot(aes(x = reorder(term, estimate, sort), y = estimate, fill = pos)) +
geom_bar(stat = "identity") +
coord_flip() +
labs(x = NULL, y = "Stärke des Koeffizienten") +
guides(fill = "none") +
theme_bw()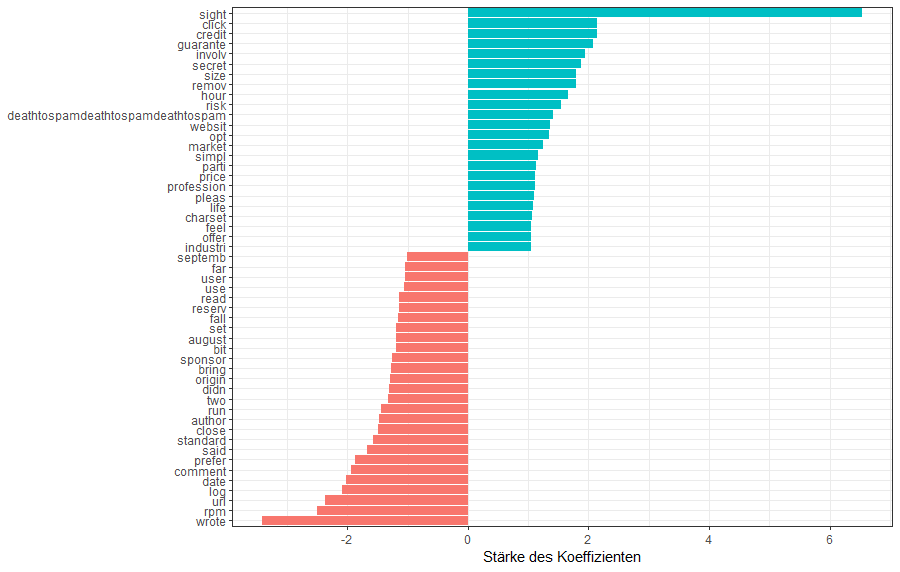
Naive Bayes
Um das Naive Bayes Modell mit tidymodels zu rechnen, benötigen wir zwei zusätzliche R-Packages, die wir hier gleich laden (installieren Sie diese zuerst, falls Sie das nicht bereits getan haben).
# Wir laden zwei zusätzliche R-Packages
library(discrim)
library(naivebayes)Die Dokumentation für die tidymodels Implementation des Naive Bayes Modells finden Sie hier.
Auch hier initialisieren wir als erstes das Modell mit der Funktion naive_Bayes(). Was macht das Argument Laplace = 1.0? Wir haben im Theorieteil gesehen, dass wir für Naive Bayes viele Randwahrscheinlichkeiten aus den Daten schätzen müssen. Doch was passiert, wenn z.B. keine einzige Spam Email das Wort “write” enthält? In dem Fall ist die Wahrscheinlichkeit \(p(write_i | y_i = 1) = 0\). Wenn jetzt also eine neue Spam Email, welche das Wort “write” enthält, in Ihr Postfach reinkommt, dann wird der Spam Filter eine Spam Wahrscheinlichkeit von 0 berechnen. Mit Laplace = 1.0 beheben wir dieses Problem, indem wir bei der Schätzung der Randwahrscheinlichkeiten überall eine 1 addieren.
# Modell Spezifikation
nb_mod <-
naive_Bayes(Laplace = 1.0) %>%
set_engine("naivebayes")Als nächstes erstellen wir ein kleines Recipe für das Naive Bayes Modell. Wir definieren zuerst das Modell (y ~ .) und transformieren danach alle Input-Daten (all_predictors()) in Faktoren, da die Naive Bayes Implementation in tidymodels das so erfordert.
# Recipe für Naive Bayes
nb_recipe <-
recipe(y ~ ., data = train) %>%
step_mutate_at(all_predictors(), fn = factor)Danach erstellen wir den Workflow wie wir das uns bereits gewohnt sind:
# Workflow für Naive Bayes
nb_workflow <-
workflow() %>%
add_model(nb_mod) %>%
add_recipe(nb_recipe)Und danach können wir bereits das Modell fitten. Wichtig: wir müssen hier kein Hyperparameter Tuning machen, da das Naive Bayes Modell keine hat (kleine Notiz: wir könnten theoretisch den Laplace Hyperparameter tunen, aber hier ist das nicht zwingend nötig).
# Model Fitting Naive Bayes
nb_fit <-
nb_workflow %>%
fit(data = train)Schauen wir uns doch das gefittete Objekt kurz an:
# Schauen wir uns das Fit Objekt an
nb_fit %>%
extract_fit_parsnip()parsnip model object
======== Naive Bayes ========
Call:
naive_bayes.default(x = maybe_data_frame(x), y = y, laplace = ~1,
usekernel = TRUE)
------------------------------------------------------
Laplace smoothing: 1
------------------------------------------------------
A priori probabilities:
Ham Spam
0.6673476 0.3326524
------------------------------------------------------
Tables:
------------------------------------------------------
::: number (Bernoulli)
------------------------------------------------------
number Ham Spam
0 0.14525994 0.08375894
1 0.85474006 0.91624106
------------------------------------------------------
::: httpaddr (Bernoulli)
------------------------------------------------------
httpaddr Ham Spam
0 0.2104995 0.4902962
1 0.7895005 0.5097038
------------------------------------------------------
::: list (Bernoulli)
------------------------------------------------------
list Ham Spam
0 0.6019368 0.4790603
1 0.3980632 0.5209397
------------------------------------------------------
::: mail (Bernoulli)
------------------------------------------------------
mail Ham Spam
0 0.6162080 0.4596527
1 0.3837920 0.5403473
------------------------------------------------------
::: can (Bernoulli)
------------------------------------------------------
can Ham Spam
0 0.5983690 0.5566905
1 0.4016310 0.4433095
------------------------------------------------------
# ... and 633 more tables
------------------------------------------------------Wir sehen in diesem Output den geschätzten Prior sowie die ersten fünf Randwahrscheinlichkeitstabellen für die ersten fünf Wörter (number, httpaddr, etc.).
Zum Schluss verwenden wir das gefittete Modell nb_fit, um die Vorhersagen sowohl auf dem Trainings- als auch auf dem Testdatensatz zu rechnen. Dazu verwenden wir die Funktion predict() mit dem Argument type = "prob", so dass wir die vorhergesagten Spam Wahrscheinlichkeiten kriegen.
# Wir rechnen die Vorhersagen auf Training- und Testset
train_pred <- predict(nb_fit, train, type = "prob")
test_pred <- predict(nb_fit, test, type = "prob")Wie bei der logistischen Regression können wir hier die ROC Kurve plotten. Hier allerdings basierend auf den Trainingsdaten, da wir hier keine Cross-Validation gemacht haben und darum keine CV-Resultate haben (Achtung: die Testdaten fassen wir hier noch nicht an).
# Resultate vorbereiten für ROC Kurve
nb_auc <-
train_pred %>%
bind_cols(train["y"]) %>%
roc_curve(y, .pred_Spam, event_level = "second") %>%
mutate(model = "Naive Bayes")
# ROC Kurve
autoplot(nb_auc)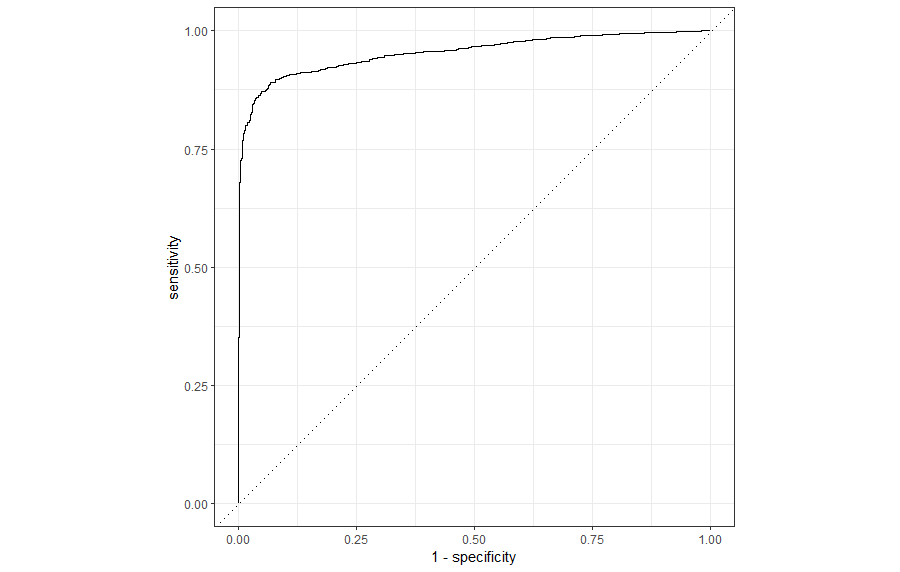
Vergleich der Modelle
Nun wollen wir die ROC Kurven unserer beiden Modelle in einem Plot darstellen. Wir verwenden bind_rows(), um die Resultate beider Modelle zusammenzuführen. Dannach ist es eine klassische ggplot2 Pipe:
# Vergleich der ROC Kurven
bind_rows(nb_auc, lr_auc) %>%
ggplot(aes(x = 1 - specificity, y = sensitivity, col = model)) +
geom_path(linewidth = 0.7, alpha = 0.8) +
geom_abline(lty = 3) +
coord_equal() +
scale_color_viridis_d(option = "plasma", end = .6) +
theme_bw()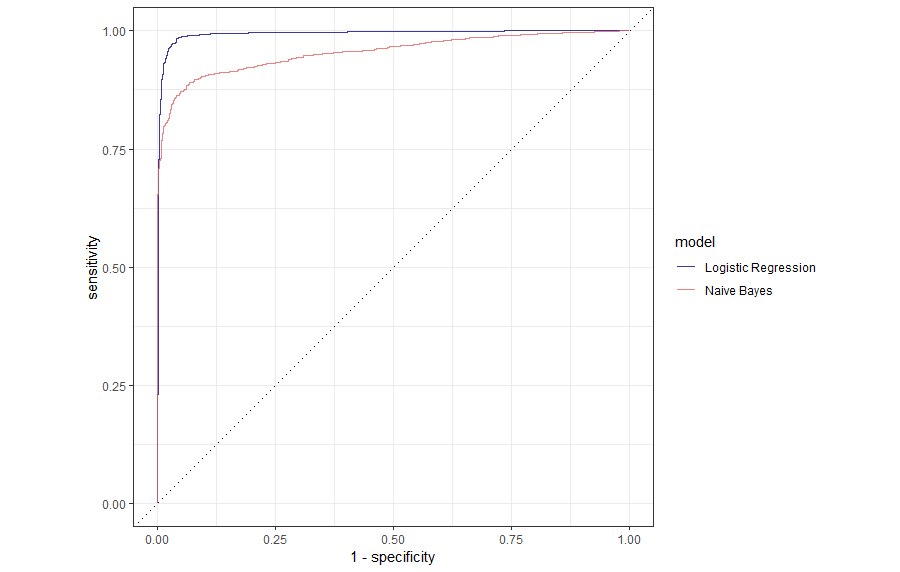
Wir entscheiden uns aufgrund dieser Grafik klar für das logistische Regressionsmodell.
Testset Performance
Ganz am Schluss interessiert uns natürlich nun, wie die Performance auf dem Testdatensatz ist. Als erstes verwenden wir die Funktion augment(), welche für beide Modelle die Vorhersagen zum Testdatensatz hinzufügt.
# Testset-Performance Last Fit (LR und NB)
test_lr_aug <- augment(last_lr_fit, test)
test_nb_aug <- augment(nb_fit, test)Dann wenden wir die Funktion roc_auc() auf den vorher generierten Objekte an:
# ROC AUC für Logistische Regression
test_lr_aug %>%
roc_auc(truth = y, .pred_Spam, event_level = "second")# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 roc_auc binary 0.996Auch auf dem Testdatensatz performt das logistische Regressionsmodell fantastisch! Die Fläche unter der ROC Kurve ist fast 1.0.
# ROC AUC für Naive Bayes
test_nb_aug %>%
roc_auc(truth = y, .pred_Spam, event_level = "second")# A tibble: 1 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 roc_auc binary 0.955Auch das Naive Bayes Modell ist nicht schlecht. Die Fläche unter der ROC Kurve ist 0.955.
Deployment Spam Filter
Um den finalen Spam Filter zu deployen, werden wir in diesem Teil eine kleine Shiny App programmieren.
Shiny Apps basieren auf R und können ganz einfach als R-Skript geschrieben werden. Shiny Apps sind mittlerweile so populär, dass die Dokumentation dazu fantastisch ist. Sie finden unter dem angegebenen Link alle möglichen Tutorials zu Shiny Apps und fantastische Beispiele, von denen man sich inspirieren lassen kann.
Der Grund, warum Shiny so beliebt ist, ist die Einfachheit mit der Apps geschrieben werden können. Eine Shiny App hat drei wichtige Komponenten:
- Im Objekt
uidefinieren wir das User Interface der App, also wie die App aussehen soll. DasshinyPackage stellt ganz viele Funktionen zur Verfügung, mit denen wir das User Interface gestalten können. Im Hintergrund passiert folgendes: R transformiert das von Ihnen geschriebene User Interface in den nötigen HTML, CSS und JavaScript Code. Mit all dem haben wir zum Glück aber nichts zu tun. - Im Objekt
serverdefinieren wir die Server Logik der App, also was die App rechnen soll und welche Visualisierungen erstellt werden sollen. Dort verwenden wir vor allem R-Funktionen, die uns bereits bekannt sind (Base R und Packages). - Am Schluss übergeben wir der Funktion
shinyApp()das User Interface und die Server Logik:shinyApp(ui = ui, server = server). So weiss R, wie die verschiedenen Element zu einer App zusammenzuführen sind.
Shiny App Komponenten
Der nachfolgende Code Block enthält den ersten Teil unserer App. Hier laden wir die notwendigen R Packages und definieren die preprocess() Funktion, welche die Emails vorverarbeitet, so dass sie bereit sind, um dem Modell gefüttert zu werden. Ausserdem definieren wir die Sigmoid Funktion, die wir weiter unten verwenden werden, um Modellvorhersagen zu machen.
# Lade R Packages
library(shiny)
library(tidyverse)
library(tm)
# ----------------------------------------------------------------------
# PREPROCESSING FUNKTION
preprocess <- function(email) {
# Find the location of first '\n\n'
loc_first_nn <- str_locate(email, '\n\n')
# If there is '\n\n' in email, get only body of email (everything after first '\n\n')
if (!is.na(loc_first_nn[,2])) {email <- substr(email, loc_first_nn[,2] + 1, nchar(email))}
# Remove all HTML tags
email <- gsub("<[^<>]+>", " ", email)
# Remove remaining special characters
email <- gsub("\n|\t| ", " ", email)
# Find all URLs and replace with 'httpaddr'
email <- gsub('(http|https)://[^[:space:]]*', "httpaddr", email)
# Find all email addresses and replace with 'emailaddr'
email <- gsub('[^[:space:]]+@[^[:space:]]+', 'emailaddr', email)
# Replace all numbers with 'number'
email <- gsub('[0-9]+', ' number ', email)
# Replace dollar signs with 'dollar'
email <- gsub('[$]+', ' dollar ', email)
# Remove all punctuation
email <- gsub('[[:punct:]]+', ' ', email)
# Trim all extra spaces
email <- trimws(gsub("\\s+", " ", email))
# All lower-case letters
email <- tolower(email)
# Tokenize such that we get a vector of words instead of one string
email_tokens <- tm::scan_tokenizer(email)
# Remove stop words
email_tokens <- email_tokens[!(email_tokens %in% stopwords(kind = "en"))]
# Stemming
email_tokens <- stemDocument(email_tokens)
# Remove all one-character words, e.g., 'e'
email_tokens <- email_tokens[nchar(email_tokens) > 1]
# Return unique character vector
unique(email_tokens)
}
# Sigmoid Funktion
sigmoid <- function(z){1 / (1 + exp(-z))}Im nächsten Code Block definieren wir das User Interface. Im Sidebar Panel erstellen wir ein Textfeld mit textAreaInput() und zwei Action Buttons. Der eine lässt den Spam Filter laufen, der andere setzt alles wieder zurück. Im Main Panel lassen wir vorerst mal etwas Text anzeigen. Die Funktion textOutput("text") wird das Element mit der ID "text" anzeigen, das wir unten in der Server Logik definieren werden.
# ----------------------------------------------------------------------
# Definiere User Interface (UI) für App
ui <- fluidPage(
# Titel
titlePanel("Spam Filter"),
# Sidebar Panel
sidebarLayout(
sidebarPanel(
# Textfenster, um Email einzugeben
textAreaInput("email", NULL, width = '100%', rows = 15, placeholder = "Enter your email here"),
# Button, um Spam Filter laufen zu lassen
actionButton("run", "Run Spam Filter"),
# Button, um alles zurückzusetzen
actionButton("clear", "Clear")
),
# Main Panel, in dem wir die Ergebnisse anzeigen
mainPanel(
# Textoutput, der die Wahrscheinlichkeit, dass die Email Spam ist, beziffert
textOutput("text"),
# Plot
plotOutput(outputId = "plot")
)
)
)Hier definieren wir nun die Server Logik. Als erstes laden wir die .rds Dateien. Weil wir den Output nur anzeigen wollen, nachdem der Button Run Spam Filter geklickt wurde (siehe Action Buttons in UI), müssen wir sogenannte Reaktive Events definieren. Mit der Funktion reactiveValues() bilden wir zuerst einen Container, in dem wir dann die Outputs von den reaktiven Events speichern. Die Objekte im Container werden mit NULL initialisiert.
In der Funktion observeEvent(input$run, {...}) definieren wir danach den reaktiven Event, der passiert, wenn Run Spam Filter geklickt wird. Dasselbe dann noch einmal mit observeEvent(input$clear, {...}), wo wir den Reset Event definieren, der alles wieder zurücksetzt.
Mit den Funktionen renderText() und renderPlot() können wir dann Text- oder Plotausgaben programmieren.
# ----------------------------------------------------------------------
# Definiere Server-Logik (hier wird definiert, was gerechnet werden soll)
server <- function(input, output, session) {
# Lade den Vektor 'vocab' (häufigste Wörter)
vocab <- read_rds("vocab.rds")
# Lade das finale Modell
final_model <- read_rds("final_model.rds")
# Container zur Speicherung der Resultate nach Knopfdruck
v <- reactiveValues(prob = NULL)
# Reaktiver Event (soll nur nach Knopfdruck gerechnet werden)
observeEvent(input$run, {
# Wir holen Email aus Textinput und lassen preprocess() laufen
email <- preprocess(input$email)
# Bag-of-Words Vektor mit Nullen
email_bow <- rep(0, length(vocab))
# Setze eine 1 für alle Wörter aus 'vocab', die in der Email vorkommen
email_bow[which(vocab %in% email)] <- 1
# Multipliziere Parameter w1, w2, ... mit dem Bag-of-Words Vektor
ws <- final_model$estimate[2:nrow(final_model)] * email_bow
# Rechne Spam-Wahrscheinlichkeit und speichere sie in 'v$prob'
v$prob <- sigmoid(sum(c(final_model$estimate[1], ws)))
})
# Reaktiver Event, um alles zurückzusetzen
observeEvent(input$clear, {
# Im Container alles wieder auf NULL setzen
v$prob <- NULL
# Text im Textfeld löschen
updateTextAreaInput(session, "email", NULL, "")
})
# Textoutput, um Spam-Wahrscheinlichkeit zurück zu geben
output$text <- renderText({
# Wenn der Button noch nicht gedrückt wurde, soll nichts ausgegeben werden
if (is.null(v$prob)) return()
# Gebe folgenden Satz zurück
sprintf("Diese Email ist mit einer Wahrscheinlichkeit von %.2f eine Spam Email.", v$prob)
})
# TODO: SCHREIBEN SIE HIER DEN CODE FÜR EINEN PLOT, DEN SIE IN DER APP ANZEIGEN WOLLEN
output$plot <- renderPlot({
# Wenn der Button noch nicht gedrückt wurde, soll nichts ausgegeben werden
if (is.null(v$prob)) return()
# CODE FÜR PLOT HIER EINSETZEN
# WICHTIG: SIE MÜSSEN DIE ELEMENT, DIE SIE IM PLOT VERWENDEN WOLLEN IM CONTAINER SPEICHERN!
})
}Der letzte Teil der App definiert, wie alles zusammengesetzt werden muss:
# ----------------------------------------------------------------------
# App laufen lassen
shinyApp(ui = ui, server = server)Anleitung
Gehen Sie nun wie folgt vor, um Ihre App zu deployen:
- Kopieren Sie obige R Codes in ein neues R-Skript mit dem Name
app.R. - Installieren Sie die R Packages
shiny,tmundSnowballC, falls Sie diese nicht bereits früher installiert haben. - Speichern Sie die beiden Files
vocab.rdsundfinal_model.rds(siehe Moodle) im selben Ordner wie Ihr Skriptapp.R. - Öffnen Sie das Programm FileZilla (stellen Sie vorher sicher, dass der FHNW VPN an ist oder Sie im FHNW Netzwerk sind).
- Stellen Sie mit den Credentials, die Ihnen Fabian Heimsch zugestellt hat, eine Verbindung zum Server her.
- Benennen Sie einen der bestehenden Ordner auf Ihrem Server Directory um in “SpamFilter”. Wichtig: erstellen Sie auf dem Server keine neuen Ordner.
- Laden Sie die drei Dateien
app.R,vocab.rdsundfinal_model.rdsin Ihren Server-Ordner “SpamFilter” hoch. - Nun können Sie Ihre App aufrufen unter https://rapp.fhnw.ch/RAPP/MDS/VornameName/SpamFilter/.
app.R in Ihrem Server-Ordner “SpamFilter” ersetzen.