
Die Normalverteilung
Die Normal-Verteilung ist wahrscheinlich die wichtigste Verteilung in der Statistik. Ihre Form und Lage wird durch zwei Parameter festgelegt, nämlich durch den Erwartungswert und durch die Streuung:
\[E(X)=\mu\]
und
\[\sigma(X)=\sigma\]
Die Wahrscheinlichkeitsdichte der Normal-Verteilung lautet:
\[f(x) = \frac{1}{\sqrt{2\pi \cdot \sigma^2}}\cdot e^{-\frac{(x-\mu)^2}{2\cdot \sigma^2}}\]
Die Normalverteilung wird auch oft als ‘Gauss’sche Verteilung’ oder ‘Glockenkurve’ bezeichnet. Untenstehend ist der Verlauf der Dichte-Funktion \(f(x)\) für \(\mu=100\) und \(\sigma=15\) skizziert.
Folgende Eigenschaften der Dichte-Funktion der Normal-Verteilung sind wichtig:
- Die Verteilung ist definiert für \(-\infty \leq x \leq \infty\).
- Die Verteilung ist symmetrisch um den Mittelwert \(\mu\) (rot eigenzeichnet) und die Kurve ist bei \(x=\mu\) am höchsten.
- Die Fläche unter der Kurve beträgt 100%.
- Mit Änderung von \(\mu\) bewegt sich die Kurve horizontal.
- Mit Änderung von \(\sigma\) wird die Kurve breiter oder schmäler.
Übung
Interessanter sind aber Fragen nach der Fläche unter der Kurve der Normalverteilung. Zum Beispiel könnte man sich fragen, welcher Anteil der Bevölkerung IQ-Werte im Intervall \(85 \leq x \leq 115\) abdeckt, oder \(P(x_1\leq x \leq x_2)\). Versuchen Sie, dies in R mit der Funktion pnorm() zu berechnen.
mu<-100
sigma<-15
pnorm(115,mean=mu,sd=sigma)-pnorm(85,mean=mu,sd=sigma)
pnorm(mu+1*sigma,mean=mu,sd=sigma)-pnorm(mu-1*sigma,mean=mu,sd=sigma)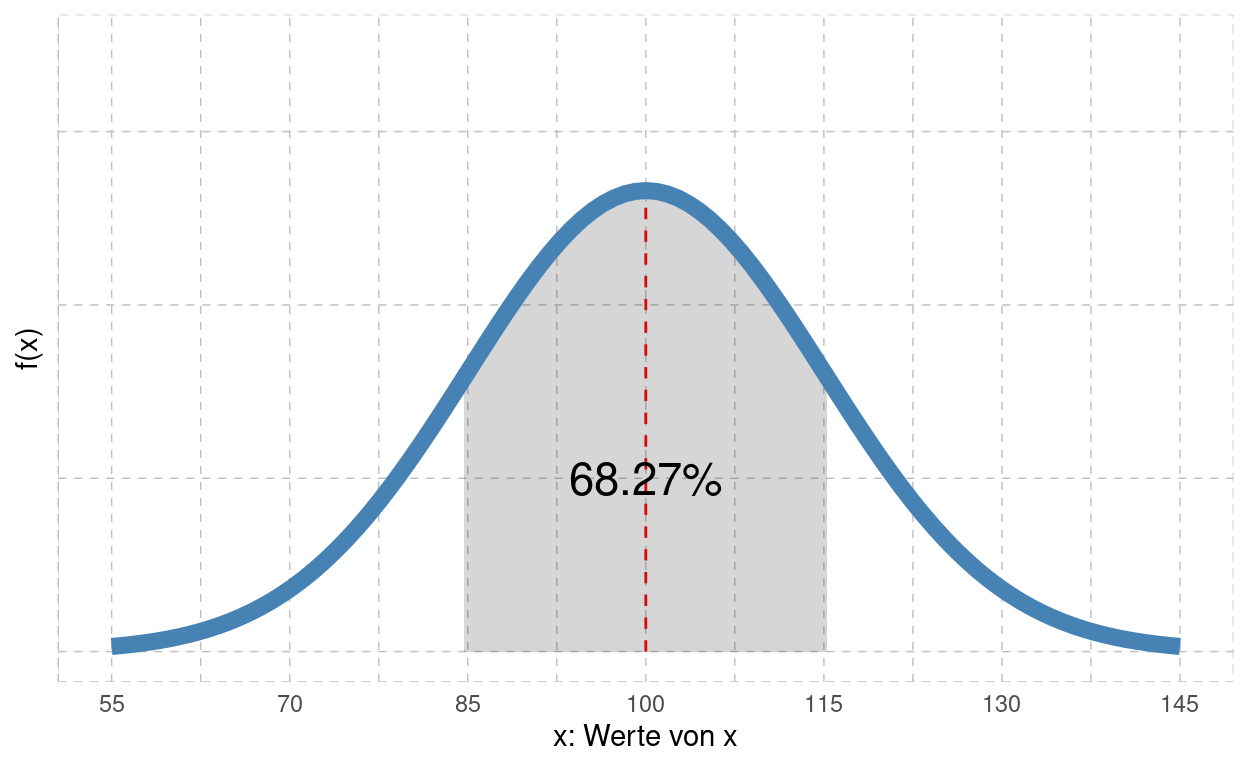
Wir haben also herausgefunden, dass \(68.3%\) der Bevölkerung einen IQ zwischen \(x_1=85\) und \(x_2=115\) hat. Die Parameter wurden so gewählt, als dass die untere Grenze \(1\) Standardabweichung \(\sigma\) vom Mittelwert \(\mu\) entfernt ist, die obere Grenze entsprechend gleich.
\[P(\mu-1\cdot \sigma \leq x \leq \mu+ 1\cdot \sigma) = 0.682\]
Die gleiche Rechnung können wir für \(z=2\) Standardabweichungen vom Mittelwert anstellen:
\[P(\mu-2\cdot \sigma \leq x \leq \mu+ 2\cdot \sigma) = 0.9545\]
\[P(\mu-3\cdot \sigma \leq x \leq \mu+ 3\cdot \sigma) = 0.9973\]
Insbesondere wichtig ist die Standard-Normalverteilung. Diese ist eine Normalverteilung mit den Parametern \(\mu=0\) und \(\sigma=1\). Unter der Standard-Normalverteilung redet man eher von \(z\)-Werten (vorher \(x\) für den IQ). Die z-Werte können wir als die Entfernung zum Mittelwert in Anzahl Standardabweichungen interpretieren.
\[z=\frac{x-\mu}{\sigma}\]
So gehört zum Beispiel zum IQ \(x=115\) der \(z\)-Wert: \(z=\frac{x-\mu}{\sigma}=\frac{115-100}{15}=+1\), da der \(x\)-Wert 115 \(1\)-Standardabweichung von \(\mu\) entfernt ist.
Merke:
Für Flächen unter der Normal-verteilung ist nur entscheidend, wie weit der \(x\)-Wert vom Mittelwert \(\mu\) entfernt ist, dies ausgedrückt in Anzahl Standardabweichungen: \(z=\frac{x-\mu}{\sigma}\).
Die Rücktransformation erfolgt über \(x=\mu+z\cdot\sigma\).
Wenn eine Zufallsvariable \(X\) normal-verteilt ist, so schreibt man \(X\sim N(\mu,\sigma)\).
Beantworten Sie folgendes Quiz und versuchen Sie, dort wo angebracht, die Funktion pnorm() oder die z-Transformation anzuwenden.

Übung
mu<-80
sigma<-10
z<-(85-mu)/sigma
print(z)
pnorm(80,mean=mu,sd=sigma)-pnorm(60,mean=mu,sd=sigma)Die Quantile der Normal-Verteilung berechnen sich allgemein über die Funktion qnorm(). Für IQ-Werte mit \(X\sim N(100,15)\) wollen wir folgende Quantile berechnen: Nämlich die Quantile zu \(\alpha=0.01\) oder \(x_{1\%}\), \(\alpha=5\%\), \(\alpha=95\%\) und \(\alpha=99\%\). Mit der Funktion pnorm() können Sie in R überprüfen, wieviel Flächte unter der Kurve bis zu einem \(x\)-Wert überstrichen wird (kumulierte Verteilung)
Übung
mu<-100
sigma<-15mu<-100
sigma<-15
print("1%-Quantil")
qnorm(0.01,mean=mu,sd=sigma)
qnorm(0.01,mean=0,sd=1)
print("5%-Quantil")
qnorm(0.05,mean=mu,sd=sigma)
qnorm(0.05,mean=0,sd=1)
print("90%-Quantil")
qnorm(0.9,mean=mu,sd=sigma)
qnorm(0.9,mean=0,sd=1)
print("95%-Quantil")
qnorm(0.95,mean=mu,sd=sigma)
qnorm(0.95,mean=0,sd=1)
pnorm(124.67,mean=mu,sd=sigma)Wie in der Lösung im Hint zu sehen, berechnen wir einmal das Quantil für den IQ: So beträgt \(x_{1\%}=65.1\). Das heisst, das 1% der Bevölkerung einen IQ von 65 oder tiefer hat. Die gleiche Rechnung wird nochmals wiederholt für die Standard-Normalverteilung (mean=0 und sigma=1) und wir erhalten einen z-Wert von \(z=-2.33\) (gerundet). Das heisst, dass unabhängig von Mittelwert und Streuung das 1%-Quantil bei \(z=-2.33\) zu finden ist, resp. bei \(x_{1\%}=\mu-2.33\cdot \sigma=100-2.33\cdot 15 = 65.1\). Für das 1%-Quantil befinden wir uns also \(z=-2.33\) Standardabweichungen unterhalb des Mittelwertes - und natürlich - für das 99%-Quantil bei \(z=+2.33\) Standardabweichungen oberhalb des Mittelwertes, da die Verteilung symmetrisch ist.
Aufbau der Tabelle der Normal-Verteilung
z | phi(z) | phi(-z) | p |
|---|---|---|---|
1.28 | 0.89973 | 0.10027 | 0.20054 |
1.64 | 0.94950 | 0.05050 | 0.10100 |
1.96 | 0.97500 | 0.02500 | 0.05000 |
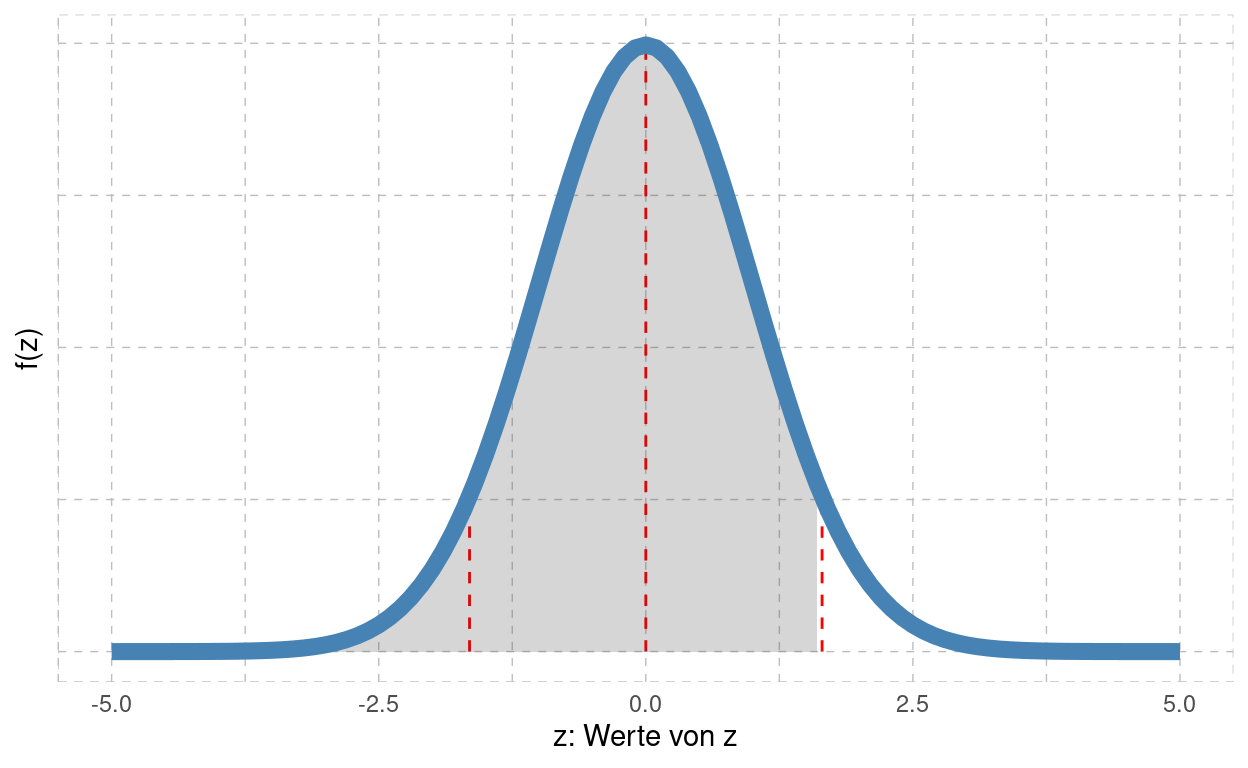
Markiert ist mit dem roten Strich das Quantil \(z=+1.64\). Die grau markierte Fläche von \(-\infty\) bis \(z=+1.64\) ist die kumulierte Verteilung \(\phi(z)\) und erreicht gemäss Tabelle \(\phi(z=+1.64)=95\%\). Um in der Tabelle Platz zu sparen, wird \(\phi(-z)\) in einer separaten Spalte ausgegeben. In der Grafik ist \(-z=-1.64\) ebenfalls eingezeichnet. Die Fläche zwischen \(-\infty\) und \(-z=-1.64\) ist somit \(\phi(z=-1.64)=5\%\). Mit \(p\) werden zudem die beiden Endflächen der Verteilung (pro Stück 5%) zusammen gerechnet, die sich zu \(p=10\%\) addieren.
Wir merken uns die wichtigsten (einseitgen) Quantile der Normal-Verteilung:
alpha | eins. Quantil z | IQ (x) |
|---|---|---|
0.010 | -2.326 | 65.1 |
0.025 | -1.960 | 70.6 |
0.050 | -1.645 | 75.3 |
0.100 | -1.282 | 80.8 |
0.900 | 1.282 | 119.2 |
0.950 | 1.645 | 124.7 |
0.975 | 1.960 | 129.4 |
0.990 | 2.326 | 134.9 |
Beachten Sie die Symmetrie der Quantile: Das (eins. = einseitige) 1%-Quantil lautet gleich wie das 99%-Quantil vom Betrag her, das 5%-Quantil gleich wie das 95%-Quantil und so weiter.
Die Spalte IQ (x) ist hier nicht besonders wichtig, aber Sie soll nochmals die Bedeutung der \(z\)-Transformation unterstreichen. Für das 95%-Quantil erhält man \(z=1.645\). Für den IQ heisst das somit \(x=\mu+z\cdot \sigma=100+1.645\cdot 15 = 124.7\) (gerundet).
Kurzes Quiz zu den einseitigen Quantilen der Normal-Verteilung: Sie dürfen obige Tabelle zu Hilfe nehmen, aber zusätzlich sollten Sie in der Lage sein, die Fragen mit R zu beantworten (oben stehendes Code-Fenster).
Die letzte Frage vom Quiz zielt auf die beidseitigen Quantile einer Verteilung. Anstatt sich nur auf das einseitig untere 5%-Quantil (\(z=-1.645\)) oder dass einseitig obere 95%-Quantil (\(z=+1.645\)) zu fokussieren legt man die Hälfte, also 2.5% in den unteren und 2.5% in den oberen Bereich der Verteilung, so dass symmetrisch um den Mittelwert 95% Fläche überstrichen werden.

Die t-Verteilung
Wie die Normal-Verteilung hat auch die t-Verteilung einen glockenförmigen Verlauf. Ein wichtiger Unterschied ist aber, dass die t-Verteilung mehr Masse in die Enden der Verteilung legt (fat tails). Die t-Verteilung besicht einen sogenannten Freiheitsgrad \(df\) (degrees of freedom). Allgemein berechnet sich der Freiheitsgrad über
\[df = n-1\]
wobei \(n\) der Stichprobenumfang darstellt. Eine t-Verteilung zu \(df=1\) (blau), \(df=3\) (grün) und \(df=50\) (gelb) Freiheitsgraden ist untenstehend dargestellt, zusätzlich ist noch die Kurve der (Standard-)Normalverteilung skizziert.

Offensichtlich erstrecken sich t-Verteilungen über weitere Bereiche als die Normal-Verteilung. Zudem nähert sich die t-Verteilung mit zunehmenden Freiheitsgraden relativ schnell der Normal-Verteilung an.
Aufbau der t-Tabelle
Der Aufbau der Tabelle der t-Verteilung ist wie folgt:
df | p=0.2 | p=0.1 | p=0.09 | p=0.08 | p=0.07 | p=0.06 | p=0.05 | p=0.04 | p=0.03 | p=0.02 | p=0.01 | p=0.005 | p=0.001 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
df=1 | 3.078 | 6.314 | 7.026 | 7.916 | 9.058 | 10.579 | 12.706 | 15.895 | 21.205 | 31.821 | 63.657 | 127.321 | 636.619 |
df=3 | 1.638 | 2.353 | 2.471 | 2.605 | 2.763 | 2.951 | 3.182 | 3.482 | 3.896 | 4.541 | 5.841 | 7.453 | 12.924 |
df=5 | 1.476 | 2.015 | 2.098 | 2.191 | 2.297 | 2.422 | 2.571 | 2.757 | 3.003 | 3.365 | 4.032 | 4.773 | 6.869 |
df=50 | 1.299 | 1.676 | 1.729 | 1.787 | 1.852 | 1.924 | 2.009 | 2.109 | 2.234 | 2.403 | 2.678 | 2.937 | 3.496 |
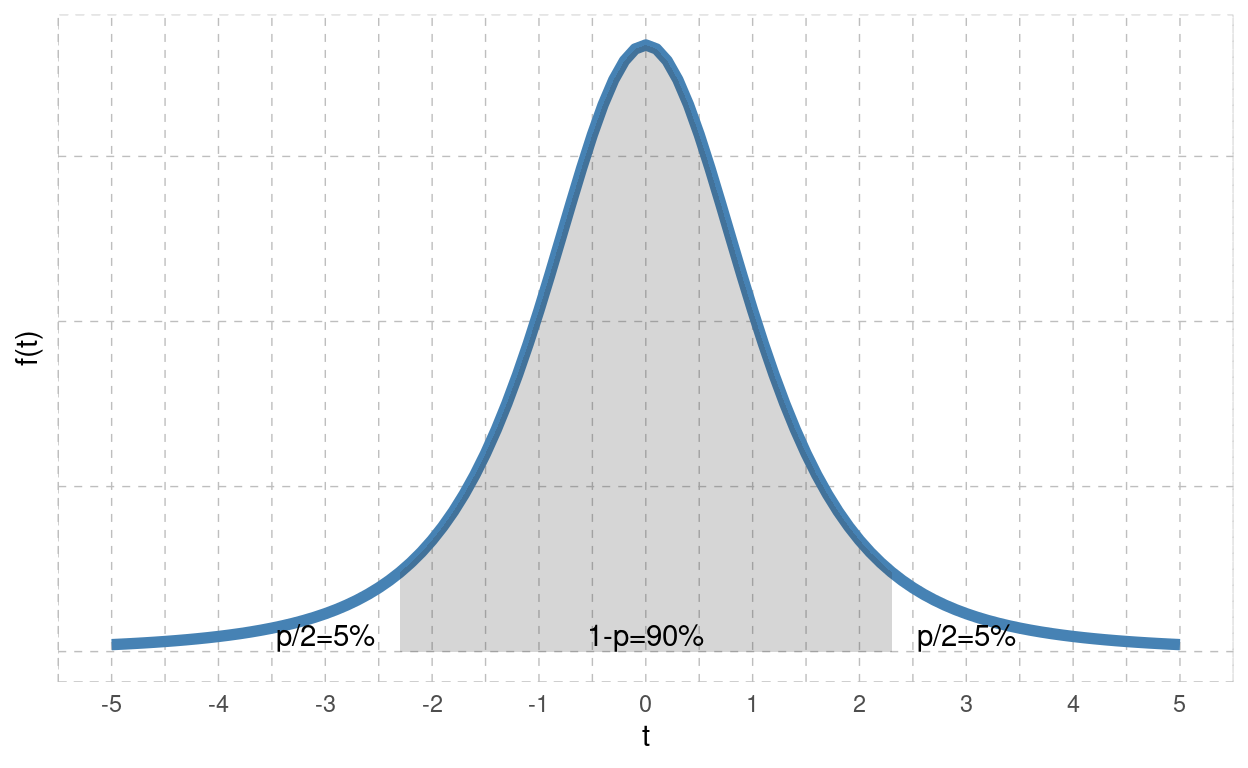
Gleich wie zuvor bei der Normalverteilung sei hier das untere 5%- und obere 95%-Quantil eingezeichnet. Diese lauten \(t=\pm 2.353\) für \(df=3\) Freiheitsgrade. Wichtig sich zu merken ist, dass die t-Tabelle die Summe der Fläche in beiden Enden der Verteilung ausgibt. Möchte man zum Beispiel die obere Grenze kennen, welche 99% der Fläche von links her überschreitet, so liegt in der oberen Endfläche 1% (sprich \(p/2\)), es ist also in der Spalte bei \(p=2\%\) zu schauen.
Lösen Sie nun mit Hilfe der App zur t-Verteilung und mit der Tabelle folgendes Quizz zur t-Verteilung.
Die \(\chi^2\)-Verteilung
Eine Variable ist \(\chi^2\)-verteilt mit \(df=k\) Freiheitsgraden, wenn \(k\) quadrierte, standard-normal-verteilte Zufallsvariablen aufsummiert werden.
Sind also die Variablen \(x_1\), \(x_2\), \(\dots\), \(x_k\) alle \(N(0,1)\) verteilt (standard-normal-verteilt bedeutet Mittelwert 0 und Streuung 1), so ist die Variable
\[Y = x_1^2 + x_2^2 + \dots + x_k^2\]
\(\chi^2\) verteilt mit \(df=k\) Freiheitsgraden.
Überlegen wir uns die Verteilung an einem kleinen Beispiel. Die \(N(0,1)\) verteilte Zufallsvariable bewegt sich um 0 symmetrisch zwischen \(-\infty\) und \(+\infty\). Wird eine solche Variable nun quadriert, so bewegt sie sich zwischen \(0\) und \(+\infty\), da negative Werte beim quadrieren ja positiv werden.
Führen Sie über die Funktion Hint untenstehenden R-Code aus. Es werden drei Variablen \(x_1\), \(x_2\) und \(x_3\) generiert mit je \(n=1000\) Beobachtungen, die alle \(N(0,1)\) verteilt sind. Anschliessend wird eine Variable \(y=x_1^2+x_2^2+x_3^3\) gebildet und in einem Histogramm dargestellt. Was fällt auf?
n<-1000
x1<-rnorm(n,mean=0,sd=1)n<-1000
x1<-rnorm(n,mean=0,sd=1)
x2<-rnorm(n,mean=0,sd=1)
x3<-rnorm(n,mean=0,sd=1)
# Darstellung einer N(0,1)-Variable
hist(x1)
# quadrieren und aufsummieren
y<-x1^2+x2^2+x3^2
hist(y)
# Mittelwert von y
mean(y)
# Streuung von y
sd(y)- Die \(\chi^2\)-Verteilung bewegt sich nur im positiven Bereich
- Die \(\chi^2\)-Verteilung ist nicht symmetrisch
Oben stehend wird von der \(\chi^2\)-verteilten Variablen \(y\) noch der Erwartungswert \(E(y)\) und die Streuung \(\sigma(y)\) gebildet. Für eine \(\chi^2\)-Verteilung mit \(df\) Freiheitsgraden gilt:
\[E(X)=df\] \[\sigma(X)=\sqrt{2\cdot df}\]
Von der obig simulierten Variable \(y\) mit \(df=3\) Freiheitsgraden müsste somit resultieren:
\[E(y)=df=3\] \[\sigma(y)=\sqrt{2\cdot df} = \sqrt{6} = 2.45\]
Aufbau der \(\chi^2\)-Tabelle
df | p=5e-04 | p=0.005 | p=0.01 | p=0.025 | p=0.05 | p=0.1 | p=0.9 | p=0.95 | p=0.975 | p=0.99 | p=0.995 | p=0.9995 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
df=1 | 0.000 | 0.000 | 0.000 | 0.001 | 0.004 | 0.016 | 2.706 | 3.841 | 5.024 | 6.635 | 7.879 | 12.116 |
df=3 | 0.015 | 0.072 | 0.115 | 0.216 | 0.352 | 0.584 | 6.251 | 7.815 | 9.348 | 11.345 | 12.838 | 17.730 |
df=5 | 0.158 | 0.412 | 0.554 | 0.831 | 1.145 | 1.610 | 9.236 | 11.070 | 12.833 | 15.086 | 16.750 | 22.105 |
df=50 | 23.461 | 27.991 | 29.707 | 32.357 | 34.764 | 37.689 | 63.167 | 67.505 | 71.420 | 76.154 | 79.490 | 89.561 |
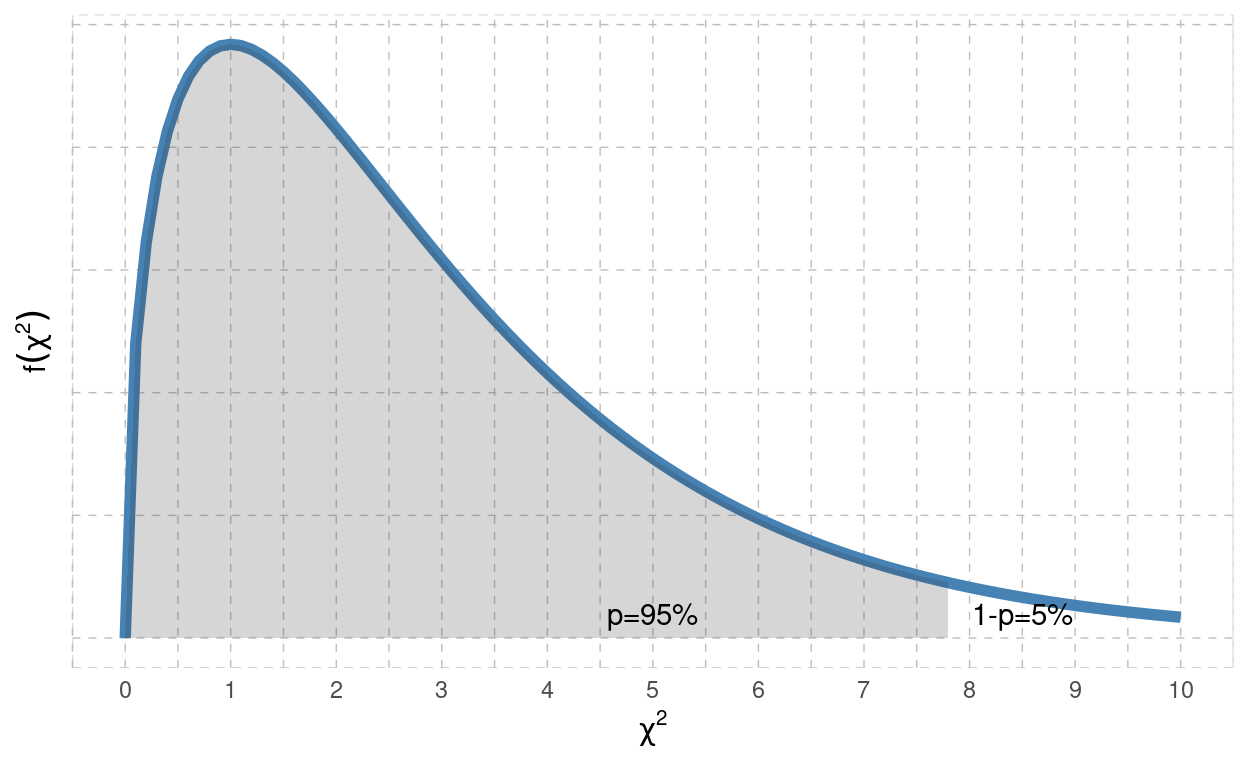
Obige Abbildung zeigt die \(\chi^2\)-Verteilung mit \(df=3\). Der Erwartungswert oder Mittelwert dieser Verteilung, wir erinnern uns, wäre 3. In der Tabelle sind nun die Quantile der \(\chi^2\)-Verteilungen gelistet, wobei \(p\) die Fläche von links her darstellt. Das 95%-Quantil dieser Verteilung lautet offenbar 7.815. Das untere 5%-Quantil lautet 0.352. Um 95% Fläche “in der Mitte” zu überstreichen, geht man vom 2.5%-Quantil, nämlich 0.216, bis zum 97.5%-Quantil, nämlich zu 9.348.
Lösen Sie nun untenstehendes Quizz, und zwar mit Hilfe der Äpp und der Tabelle zur \(\chi^2\)-Verteilung.
Der QQ-Plot
Der QQ-Plot wird als visuelles Mittel benutzt, um zu überprüfen, ob eine empirische Verteilung mit einer bestimmten, vorgängig vermuteten theoretischen Verteilung übereinstimmt.
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
81 | 91 | 91 | 95 | 101 | 101 | 104 | 105 | 111 | 121 |
Wir wollen nun überprüfen, ob diese empirische Verteilung einer theoretischen Verteilung entspricht, nämlich einer Normalverteilung mit Mittelwert \(\mu=100\) und Streuung \(\sigma=10\).
Es gibt mehrere Arten, dies zu prüfen.
Überprüfen mittels Histogramm
Wir berechnen die optimale Klassenbreite über \(b=\frac{max-min}{1+3.32\cdot log_{10}(n)}\) und erhalten
\[b = \frac{121-81}{1+3.32\cdot log_{19}(10)} = 9.3\]
Wir runden auf und nutzen daher \(b=10\) und starten das Histogramm bei 75.
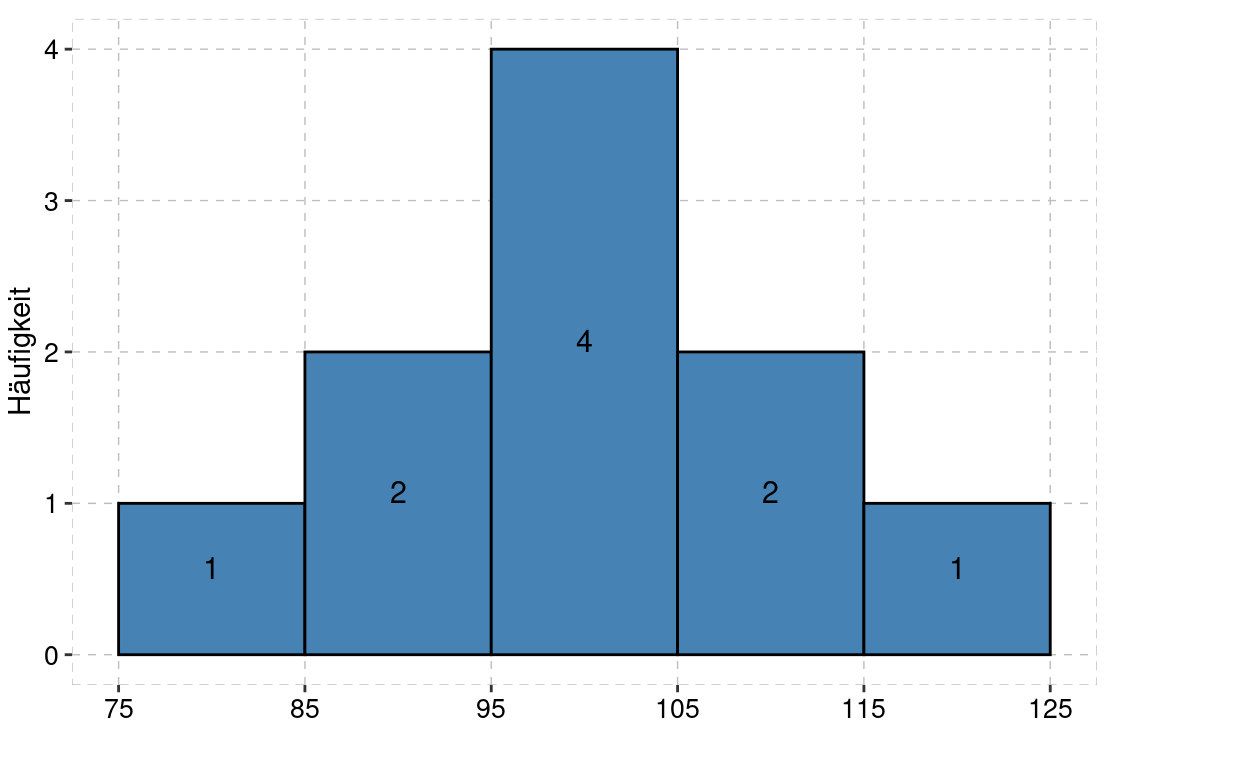
Mit nur \(n=10\) Werten ist die Darstellung eines Histogrammes und die Interpretation hinsichtlich Normal-Verteilung sicherlich zweifelhaft. Im vorliegenden Beispiel ist das Histogramm jedoch perfekt symmetrisch, auch der Mittelwert scheint sehr nahe bei \(\mu=100\) zu sein.
Insbesondere können wir nun die gefundenen Häufigkeiten unter der theoretischen Verteilung überprüfen.
untere Grenze | obere Grenze | empirische Häufigk. | rel. th. Häufigk. | abs. th. Häufigk. |
|---|---|---|---|---|
75 | 85 | 1 | 6.68% | 1 |
85 | 95 | 2 | 24.17% | 2 |
95 | 105 | 4 | 38.29% | 4 |
105 | 115 | 2 | 24.17% | 2 |
115 | 125 | 1 | 6.68% | 1 |
Kommentare zur Tabelle:
- Die unteren und oberen Grenzen sind gemäss Klassenbreite
bund Minimum festgelegt. - Werte, wie zum Beispiel
95, die auf die obere Grenze fallen, werden erst in der nächsten Klasse gezählt. - Die empirischen Häufigkeiten sind identisch wie im Histogramm gezeigt.
- Die relativen theoretischen Häufigkeiten werden mittels der kumulierten Normalverteilung ermittelt. Die erste Häufigkeit ist die Fläche unter der Normalverteilung von \(-\infty\) bis \(x=85\), in
Rberechnet sich die Fläche überpnorm(q=85,mean=100,sd=10). Sie können so versuchen, mit untenstehendemR-Code die Flächen zu berechnen, oder natürlich mit der Verteilungs-Tabelle resp. mit der App zur Normalverteilung. - Die absoluten Häufigkeiten finden sich, indem man die relativen Häufigkeiten mal \(n=10\) rechnet (und auf ganze Zahlen rundet). Wir sehen, dass die theoretische Verteilung sehr gut zur empirischen Verteilung passt.
pnorm(q=85,mean=100,sd=10)
pnorm(q=95,mean=100,sd=10)-pnorm(q=85,mean=100,sd=10)
pnorm(q=105,mean=100,sd=10)-pnorm(q=95,mean=100,sd=10)
pnorm(q=115,mean=100,sd=10)-pnorm(q=105,mean=100,sd=10)
1-pnorm(q=125,mean=100,sd=10)Überprüfen mittels deskriptiven Statistiken
Von IQ-Werten nehmen wir an, dass diese normal-verteilt sind mit Mittelwert \(\mu=100\) und Streuung \(\sigma=10\). Wir erstellen nun eine Tabelle mit einigen deskriptiven Statistiken:
q10 | q25 | q50 | q75 | q90 | MW | SD | skew | kurt |
|---|---|---|---|---|---|---|---|---|
86 | 91 | 101 | 105 | 116 | 100.1 | 11.3 | 0.138 | -0.848 |
myiq<-c(81, 91, 91, 95, 101, 101, 104, 105, 111, 121)myiq<-c(81, 91, 91, 95, 101, 101, 104, 105, 111, 121)
df<-data.frame(q10=quantile(myiq,0.1,type=2),q25=quantile(myiq,0.25,type=2),q50=quantile(myiq,0.5,type=2),
q75=quantile(myiq,0.75,type=2),q90=quantile(myiq,0.9,type=2),MW=round(mean(myiq),1),SD=round(sd(myiq),1),
skew=round(skewness(myiq),3),kurt=round(kurtosis(myiq),3))
dfFeststellungen:
- Mittelwert \(\bar{x}\) und Streuung \(s\) sind nahe bei 100 resp. 10
- Die Quantile sind einigermassen symmetrisch um den Median
- Der Median ist beinahe mit dem Mittelwert identisch
- Die Schiefe ist sehr nahe bei 0, die Wölbung ist (wahrscheinlich) zu weit von 0 weg
Überprüfen mittels QQ-Plot
QQ steht für Quantile-Quantile-Plot, in welchem die Quantile der empirischen Verteilung der Quantile der theoretischen Verteilung in einem Streudiagramm gegenübergestellt werden. Sind die Verteilungen identisch, so müssten auch die Quantile der Verteilungen über einen weiten Bereich identisch sein.
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
81 | 91 | 91 | 95 | 101 | 101 | 104 | 105 | 111 | 121 |
Es können nun die Quantile in Schritten von 0.1%, 0.5%, 1%, 5% usw. berechnet werden. Mit nur \(n=10\) Werten macht es natürlich keinen Sinn, Quantile in Tausendstel oder Hundertstel Schritten darzustellen. Wir berechnen die Quantile: \(x_{10\%}\), \(x_{20\%}\), \(x_{30\%}\), \(x_{40\%}\), \(x_{50\%}\), \(x_{60\%}\), \(x_{70\%}\), \(x_{80\%}\) und \(x_{10\%}\) für die empirische und die theoretische Verteilung ausrechnen.
Für die empirischen Quantile erhalten wir:
q10 | q20 | q30 | q40 | q50 | q60 | q70 | q80 | q90 |
|---|---|---|---|---|---|---|---|---|
86 | 91 | 95 | 98 | 101 | 102.5 | 105 | 108 | 116 |
Zur Erinnerung: In R berechnen wir Quantile über den Befehl quantile(x,0.1,type=2).
myiq<-c(81, 91, 91, 95, 101, 101, 104, 105, 111, 121)
round(quantile(myiq,seq(0.1,0.9,0.1),type=2),1)Für die theoretischen Quantile erhalten wir:
q10 | q20 | q30 | q40 | q50 | q60 | q70 | q80 | q90 |
|---|---|---|---|---|---|---|---|---|
87.2 | 91.6 | 94.8 | 97.5 | 100 | 102.5 | 105.2 | 108.4 | 112.8 |
In R berechnen wir die theoretischen Quantile der Normalverteilung mit dem Befehl qnorm()
myiq<-c(81, 91, 91, 95, 101, 101, 104, 105, 111, 121)
round(qnorm(seq(0.1,0.9,0.1),mean=100,sd=10),1)Nun werden die empirischen Quantile auf der y-Achse und die theoretischen Quantile auf der x-Achse abgetragen.
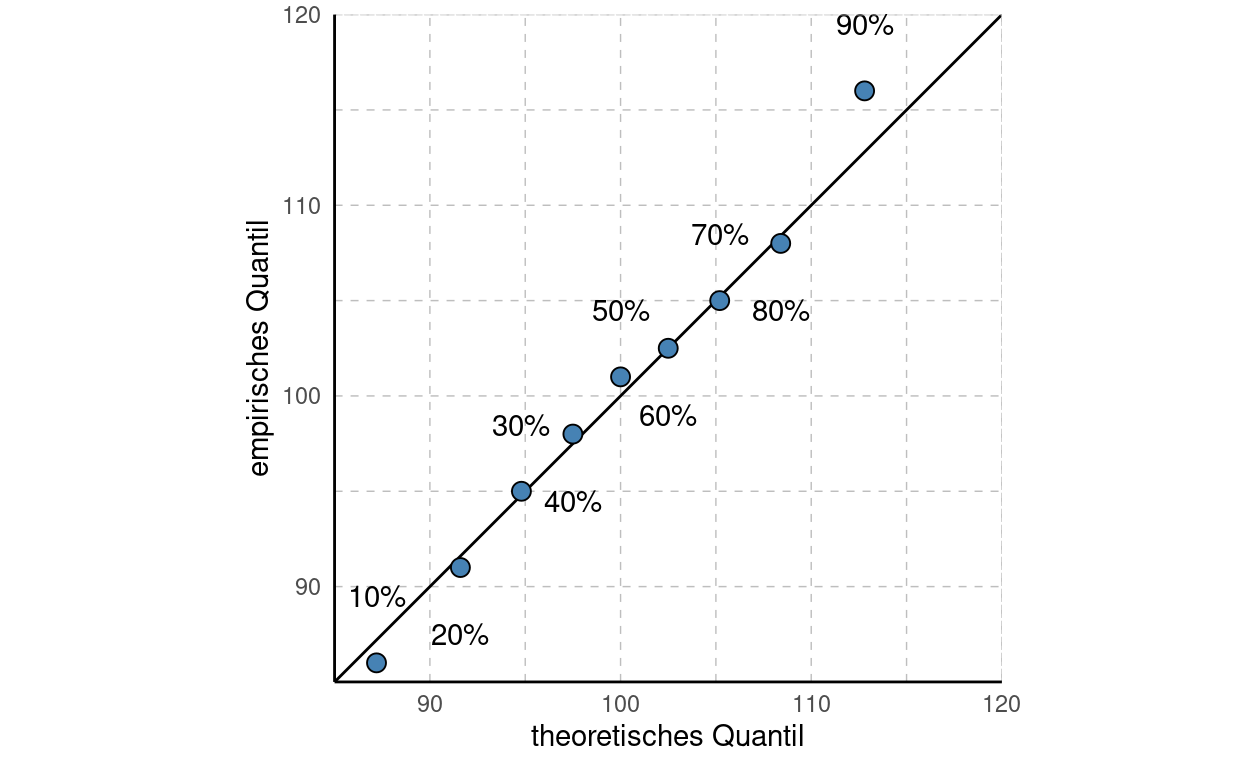
Folgendes lässt sich aus einem QQ-Plot ablesen:
- Im obigen Beispiel entsprechen die Quantile der theoretischen und empirischen Verteilung einander recht genau. Dies war zu erwarten, da wir schon beim Histogramm eine recht genaue Übereinstimmung beider Verteilungen gesehen hatten.
- Sind die Punkte parallel zur Diagonale nach rechts verschoben, so ist der Erwartungswert der theoretischen Verteilung zu hoch angesetzt. Sind die Punkte parallel zu weit links, so ist der Erwartungswert der theoretischen Verteilung zu tief.
- Sind die Punke um den Mittelpunkt der Diagonale im Uhrzeigersinn verdreht, so ist die Streuung der theoretischen Verteilung zu hoch angesetzt, sind sie im Gegenuhrzeigersinn rotiert, so ist die Streuung zu tief.
Üben können Sie die Sachverhalte zum QQ-Plot nun im untenstehenden Quizz. Wenn nichts anderes erwähnt ist, so plotten Sie in der App die Quantile in 10% Schritten.
APP zu allen Verteilungen
Normal-Verteilung
t-Verteilung
\(\chi^2\)-Verteilung
QQ-Plot zur Überprüfung von Verteilungsformen
Empirische Daten
Theoretische Verteilung
Mittelwert und Streuung
Erwartungswert und Streuung
Quantile der empirischen und theoretischen Verteilung
QQ-Plot
...
Übungs-Generator für schriftliche Aufgaben
Hier können Sie sich Lehrkräfte und Studierende schriftliche Übungen nach Zufallsprinzip generieren lassen. Die Übungen werden in ein Word-Dokument mit Lösungen geschrieben und dieses kann dann zum Zweck eigener Formatierungen noch angepasst werden. Diese Übungen beinhalten (fast) keine R-basierten Aufgaben sondern nur solche, die im Rahmen einer schriftlichen Aufgabe lösbar sind. Die Aufgabensätze werden als Word-Dokument generiert und können nach eigenen Bedürfnissen formatiert werden.