
Eigenschaften von Stichprobenmittelwerten
Ein Hauptziel beim Betreiben von Statistik ist, von einer Stichprobe auf die Grundgesamtheit / Population rückzuschliessen.
Im Normalfall ist es nicht möglich, die Population als Ganzes zu beobachten. Wir nehmen für ein Einführungsbeispiel an, dass eine Grundgesamtheit aus nur \(N=3\) Kindern besteht, welche monatlich 100, 200 und 300 Euro Taschengeld erhalten. Der Populationsmittelwert lautet somit:
\[\mu = \frac{1}{3}\cdot(100+200+300) = 200\]
Die dazugehörige Standardabweichung \(\sigma\) respektive die Varianz \(\sigma^2\) der Variable \(X\): Taschengeld lauten:
\[\sigma^2 = \frac{1}{3}\cdot \left((100-200)^2+(200-200)^2+(300-200)^2 \right) = 6666.67\] \[\sigma = \sqrt{6666.67} = 81.6497\]
Berechnen Sie untenstehend im R-Code den Populationsmittelwert \(\mu\) und die Standardabweichung \(\sigma\):
x<-c(100,200,300)x<-c(100,200,300)
mu<-mean(x)
sigma<-sd(x)*sqrt(2)/sqrt(3)
mu
sigmaDie Eigenschaften der Variable \(X\): Taschengeld lassen sich somit für die Population wie folgt zusammenfassen: \(E(X)=\mu = 200\), \(\sigma(X)=\sigma = 81.65\), mit folgender Verteilung:
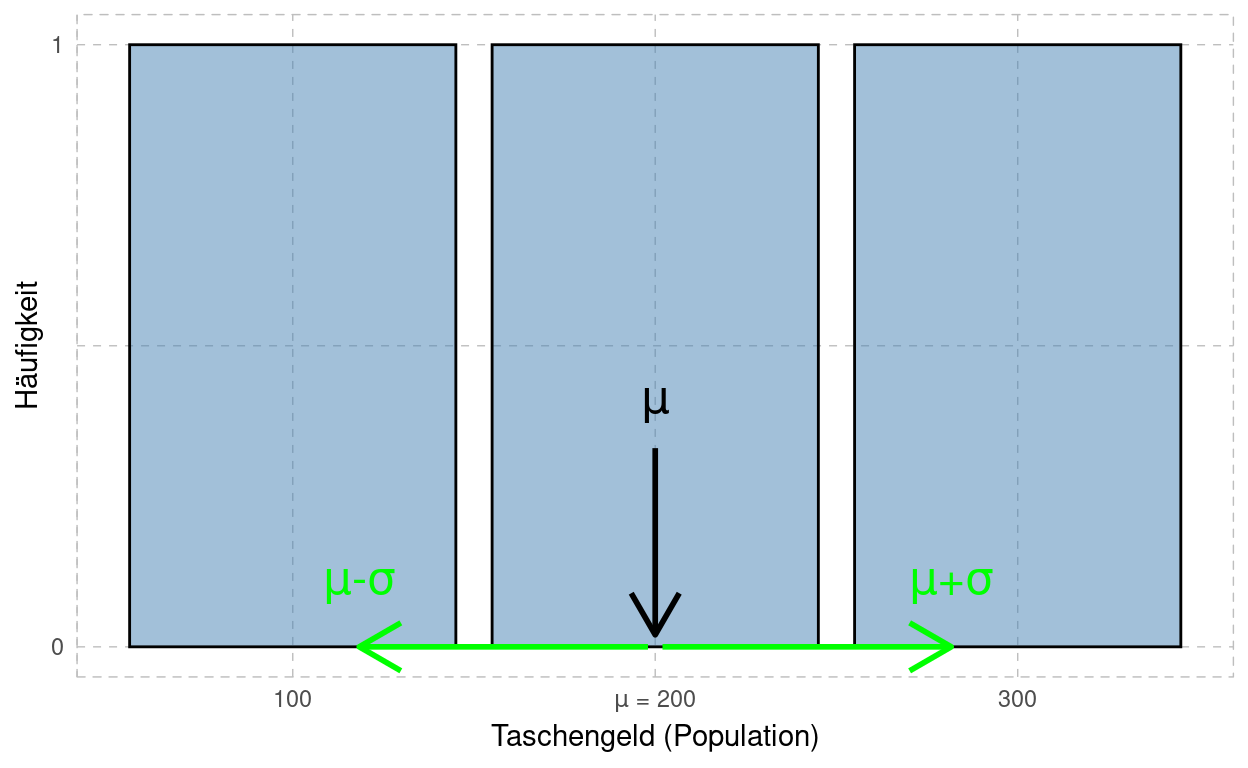
Der Mittelwert der Grundgesamtheit, \(\mu\), ist in der Praxis jedoch nicht bekannt. Vielmehr wird man versuchen, mittels einer Stichprobe den Stichprobenmittelwert \(\bar{x}\) zu berechnen, um dann einen Rückschluss auf die Population zu tätigen.
Wir nehmen an, dass nun eine Zufalls-Stichprobe der Grösse \(n=2\) erhoben wird. Wir nehmen an, dass die Stichproben blind gezogen werden und Wiederholung der Elemente, also das zweimalige Ziehen desselbigen Elementes, erlaubt ist. Aufgrund der zwei gezogenen Elemente möchte man mittels des Stichproben-Mittelwertes \(\bar{x}\) einen Rückschluss auf den (eigentlich) unbekannten Populations-Mittelwert \(\mu\) tätigen.
Folgende Ereignisse können beim Ziehen von Stichproben der Grösse \(n=2\) aus der Population \(X=(100,200,300)\) auftreten.
In obiger Tabelle mit 9 Einträgen ist zu sehen, dass sich unterschiedliche Stichprobenmittelwerte \(\bar{x}\) realisieren können. Manchmal treffen diese Stichprobenmittelwerte \(\bar{x}\) den wahren Populationsmittelwert \(\mu\) besser oder schlechter - Stichprobenmittelwerte folgen also wiederum einer Verteilung.
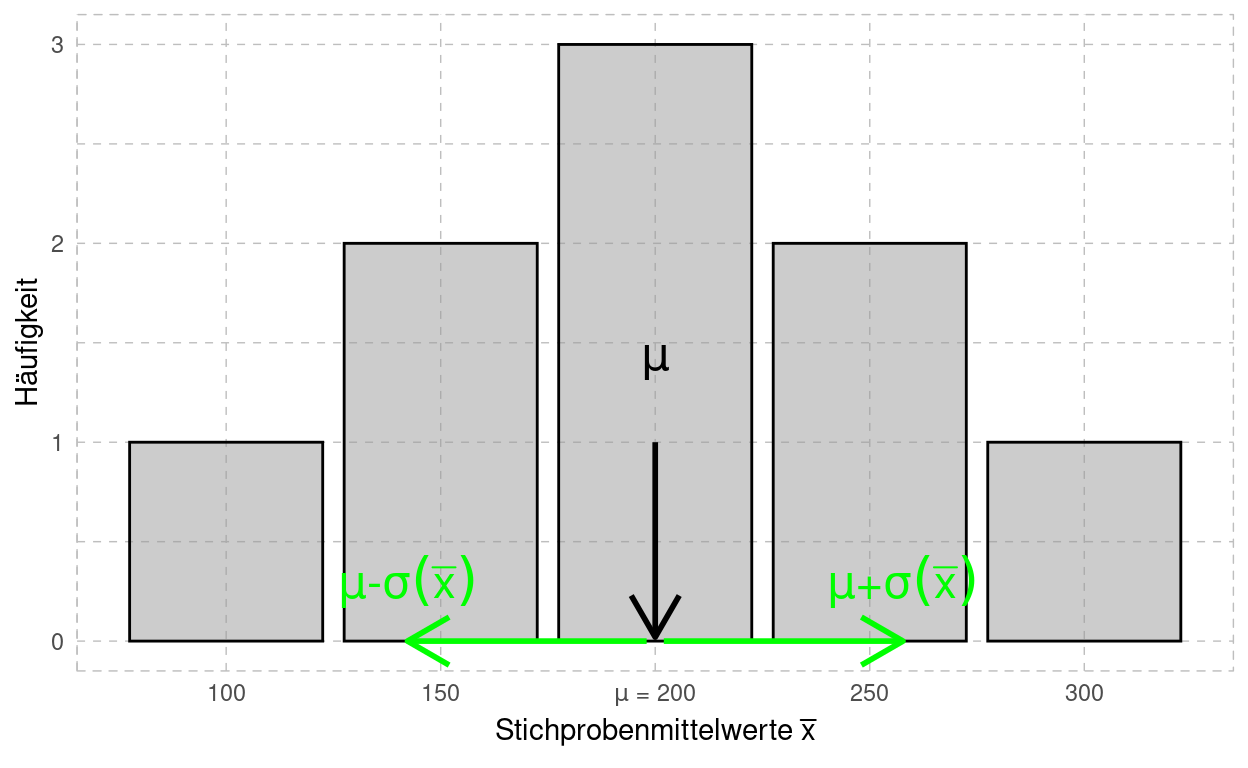
Dabei ergeben sich für die möglichen Stichprobenmittelwerte \(\bar{x}\) folgende Kenngrössen:
\[E(\bar{x}) = \frac{1}{9}\cdot (100+150+\dots+300)=200\]
\[\sigma^2(\bar{x}) = \frac{1}{9}\cdot \left((100-200)^2+(150-200)^2+\dots+(300-200)^2\right) = 3333.33 \]
Daraus lassen sich drei wichtige Erkenntnisse herleiten:
- Der Erwartungswert der Stichprobenmittelwerte \(\bar{x}\) entspricht genau dem wahren (aber meist unbekannten) Populationsmittelwert \(\mu\). Es gilt somit \(E(\bar{x})=\mu\).
- Die Varianz der Stichprobenmittelwerte bezeichnen wir mit \(\sigma^2(\bar{x})\). Diese beträgt im aktuellen Beispiel die Hälfte der Varianz \(\sigma^2\) der Populations-Werte - Es gilt offensichtlich: \(\sigma^2(\bar{x}) = \frac{\sigma^2}{n}\), wobei \(n\) der Stichprobenumfang darstellt.
- Die Verteilungsform der Stichprobenmittelwerte nähert sich mit wachsendem Stichprobenumfang \(n\), unabhängig von der Verteilungsform der Populations-Daten \(X\), einer Normalverteilung an. Das ist auch in diesem einfachen Beispiel mit dem sehr kleinen Stichprobenumfang \(n=2\) gut zu erkennen. Für sehr grosse \(n\) gilt somit: \(\bar{x} \sim N(\mu, \sigma_{\bar{x}})\). Dieser Zusammenhang nennt sich zentraler Grenzwertsatz.
Die wohl wichtigste Erkenntnis hier ist die Tatsache, dass deskriptive Statistiken wie Mittelwerte \(\bar{x}\), welche auf Zufalls-Stichproben berechnet werden, wiederum einer Verteilung unterliegen. Im Mittel scheint man dabei für Stichprobenmittelwerte den wahren Wert \(\mu\) zu treffen. Der Stichprobenmittelwert \(\bar{x}\) hat jedoch eine Schätzunsicherheit \(\sigma_{\bar{x}}\). Diese Grösse wird auch Standardfehler des Mittelwertes genannt und berechnet sich über:
\[\sigma_{\bar{x}} = \frac{\sigma}{\sqrt{n}}\]
Für das aktuelle Beispiel erhält man \(\sigma_{\bar{x}} = \frac{81.65}{\sqrt{2}}=57.74\). Je grösser der Stichprobenumfang \(n\), desto kleiner wird also der Standardfehler \(\sigma_{\bar{x}}\).
Ist die Populations-Standardabweichung \(\sigma\) unbekannt, so wird \(\sigma\) mit der Stichproben-Streuung \(s\) ersetzt.
Quiz
In diesem Abschnitt gibt es ein kurzes Quizz zur Verteilung von Stichproben-Mittelwerten \(\bar{x}\). Im unten stehenden Skript haben Sie die Möglichkeit, die Fragen aus dem Skript eigenständig zu überprüfen.
x<-c(1,2,3,4,5)
mean(x)
n<-length(x)
s<-sd(x)
n
s
s/sqrt(n)Vertrauensintervalle für den Populationsmittelwert \(\mu\)
Stichprobenmittelwerte \(\bar{x}\) folgen für grosse Stichprobenumfänge \(n\) einer Normal-Verteilung:
\[\bar{x} \sim N\left(\mu,\sigma_{\bar{x}}=\frac{\sigma}{\sqrt{n}}\right)\]
Die Annahme der Normalverteilung setzt aber auch voraus, dass die Populations-Streuung \(\sigma\) bekannt ist. Ist dies nicht der Fall, so wird in obiger Formel \(\sigma\) mit \(s\) ersetzt. Die Normal-Verteilung wird dann mit der t-Verteilung ersetzt.
Die \(t\)-Verteilung
Die Form der \(t\)-Verteilung (blau) ist der Standard-Normalverteilung sehr ähnlich, ist aber abhängig von den Freiheitsgraden \(df\) der Verteilung. Die Freiheitsgrade berechnen sich über \(df=n-1\) und sind somit direkt abhängig vom Stichprobenumfang \(n\).
Untenstehende Verteilung zeichnet für beidseitige Quantile \(\alpha\) die \(t\)-Verteilung in blau und die Stanard-Normalverteilung in grau. Durch erhöhen der Freiheitsgrade \(df\) geht die \(t\)-Verteilung in die Standard-Normalverteilung über.
Mit Hilfe der \(t\)-Verteilung kann dann ein Vertrauens-Intervall für den Populationsmittelwert \(\mu\) konstruiert werden, und zwar ausgehend
- vom Stichprobenumfang \(n\), der gewünschten Intervallbreite \(1-\alpha\) (z.B. 95%) und dem dazugehörigen \(t\)-Quantil
- vom Stichprobenmittelwert \(\mu\)
- von der Stichproben-Streuung \(s\)
Man erhält für das Konfidenz-Intervall
\[\bar{x}-t_{\alpha,df=n-1}\cdot\frac{s}{\sqrt{n}}<\mu<\bar{x}+t_{\alpha,df=n-1}\cdot\frac{s}{\sqrt{n}}\]
Beispiel für ein Vertrauensintervall für den Populations-Mittelwert \(\mu\)
Obenstehende Abbildung zeigt das Vertrauensintervall für den Populationsmittelwert \(\mu\) mittels eines Fehlerbalkens und einem blauen Punkt, welcher das Stichprobenmittel \(\bar{x}\) markiert. Angenommen, die Stichprobe x<-c(1,2,3,4,5) wurde von einer Population mit wahrem Mittelwert \(\mu=2\) gezogen, zeigt der Fehlerbalken an, dass dieser wahre Mittelwert noch im Vertrauensintervall enthalten ist. Wird mit obiger Auswahl hingegen der wahre Mittelwert auf \(\mu=0\) gesetzt, so zeigt die rote Linie an, dass das Vertrauensintervall den wahren Wert nicht mehr beinhaltet.
Nutzen Sie nun obenstehende App und/oder untenstehenden R-Code, um folgende Quizz-Fragen zu beantworten.
Quiz
x<-c(1,2,2,3,10,10)Das Wichtigste in Kürze

Simulierte Vertrauensintervalle
In untenstehender Applikation können Sie \(k\) Stichproben der Grösse \(n\) aus einer Normalverteilung mit Mittelwert \(\mu\) und Streuung \(\sigma\) simulieren. Die Grafik zeigt für die \(k\) Stichproben das Vertrauensintervall für (das eingeblich unbekannte) \(\mu\) an. * Für einige Vertrauensintervalle ist der wahre Populationsmittelwert \(\mu\) nicht beinhaltet. * Untenstehnd ist zusätzlich für die gewählte Stichprobe \(i\) die Berechnung des Vertrauensintervalles angezeigt. * Durch Verändern des Wertes \(\alpha\) auf zum Beispiel \(\alpha=0.01\) werden 99%-Vertrauensintervalle angezeigt. Im Mittel werden dann nur noch 1% der angezeigten Anzahl Intervalle den Populationswert \(\mu\) nicht mehr beinhalten.
Vertrauensintervalle für die Populationsstreuung \(\sigma\)
Gleich wie für den Populationsmittelwert \(\mu\) kann auch für die Populationsstreuung \(\sigma\) ein Vertrauensintervall angegeben werden. Dies geschieht wiederum über das Ziehen einer (Zufalls-)Stichprobe der Grösse \(n\) und anschliessender Berechnung der Stichprobenstreuung \(s\). Um folgende Schritte klarer zu gestalten, sei hier direkt die relevante Verteilung eingeführt, die \(\chi^2\)-Verteilung (Chi-Quadrat-Verteilung).
Die \(\chi^2\)-Verteilung
Angenommen, die Zufallsvariablen \(X_1\), \(X_2\), \(\dots\), \(X_k\) seien unabhängige standard-normal-verteilte Zufallsvariablen mit \(X_i \sim N(\mu=0,\sigma=1)\), dann ist die neu gebildete Zufallsvariable, nennen wir Sie \(Y\), \(\chi^2\)-verteilt, falls diese als Summe aus den quadrierten standard-normal-verteilten Variablen \(X_i\) gebildet wird:
\[Y=X_1^2+X_2^2+\dots +X_k^2\]
dann
\[Y \sim \chi^2_{df=k}\]
Wie bekannt nimmt eine Standard-normal-verteilte Zufallsvariable \(X\) Werte zwischen \(-\infty \leq X \leq +\infty\) an. Wird so eine Variable nun quadriert, so nimmt die quadrierte Variable nur noch Realisierungen im Bereich \(0\leq X^2 \leq +\infty\) an, die \(\chi^2\)-Verteilung ist somit nur im positiven Bereich definiert.
Kurzübung 1 zur \(\chi^2\)-Verteilung
Simulieren Sie in R \(n=1000\) Werte einer Standard-normal-verteilten Zufallsvariable \(x_1\) (Befehl: rnorm()) und lassen Sie sich mit dem Befehl hist() das Histogramm (die Verteilungsform) ausgeben. Betrachten Sie anschliessend die Verteilung der quadrierten Zufallsvariable \(x_1^2\) (welche \(\chi^2\)-verteilt ist mit \(df=1\)).
x1<-rnorm(1000,0,1)
hist(x1)
# quadrieren
hist(x1^2)Wie in der Lösung (‘hint’) zu sehen, streut die \(N(0,1)\) verteilte Zufallsvariable \(x_1\) ungefähr im Bereich zwischen -3 und +3, die \(\chi^2\)-verteilte Variable \(x_1^2\) ungefähr im Bereich von 0 bis 10 und weist keine Symmetrie mehr auf.
Eine \(\chi^2\)-verteilte Zufallsvariable \(Y\) mit \(df\) Freiheitsgraden (\(df\) aufsummierte quadrierte standard-normal-verteilte Zufallsvariablen) hat folgenden Mittelwert \(E(Y)\) und Streuung \(\sigma(Y)\):
\[E(X) = df\] \[\sigma(X)=\sqrt{2\cdot df}\]
Kurzübung 2 zur \(\chi^2\)-Verteilung
Simulieren Sie in R \(n=1000\) Werte einer Standard-normal-verteilten Zufallsvariable \(x_1\) und geben Sie dann Erwartungswert \(E(Y)\) und Streuung \(\sigma(Y)\) an, wobei \(Y=x_1^2\) ist. Was erhalten Sie? Wiederholen Sie den Prozess mit \(df=2\) und \(df=3\) Freiheitsgraden (Hinweis: Für z.B. \(df=2\) simulieren Sie zwei Variablen \(x_1\) und \(x_2\), die Standard-normal-verteilt sind und bilden anschliessend \(Y=x_1^2+x_2^2\)).
x1<-rnorm(1000,0,1)
y<-x1^2
mean(y) # sollte df=1 ergeben (oder beinahe)
sd(y) # sollte sqrt(2*1) ergeben
x2<-rnorm(1000,0,1)
y<-x1^2+x2^2
mean(y) # sollte df=2 ergeben (oder beinahe)
sd(y) # sollte sqrt(2*2) ergeben
x3<-rnorm(1000,0,1)
y<-x1^2+x2^2+x3^2
mean(y) # sollte df=3 ergeben (oder beinahe)
sd(y) # sollte sqrt(2*3) ergebenDas Wichtigste in Kürze
Untenstehend finden Sie eine App, mit welcher Sie sich eine \(\chi^2\)-Verteilung mit \(df\) Freiheitsgraden zeichnen lassen können. Zusätzlich können Sie sich Quantile ausgeben lassen. Wie im Buch legen wir hier das \(\alpha\)-Quantil einseitig nach oben und nicht mehr wie bei der t-Verteilung auf beide Seiten der Verteilung.
Beantworten Sie nun mit obenstehender App folgende Fragen zur \(\chi^2\)-Verteilung, nehmen Sie dazu auch die Tabellen im Buch zur Hand.
Das Vertrauensintervall für die Populationsstreuung \(\sigma\)
Angenommen, eine Erhebung von \(n=10\) Wartezeiten in Minuten an einem Postschalter hat folgende Werte ergeben: \(x=(6, 7, 8, 8, 9, 9, 10, 11, 11, 11)\). Die Herleitung für ein (z.B.) 95%-Vertrauensintervall der mittleren Wartezeit \(\mu\) in der Population haben wir schon im vorherigen Abschnitt kennen gelernt. Ziel hier ist nun, ein Vertrauensintervall für die Populationsstreuung \(\sigma\) herzuleiten, ausgehend von der Stichproben-Streuung \(s\). Wir nehmen an, dass die Zufallsvariable \(X\) der Wartezeiten normal-verteilt sei mit Streuung \(\sigma\).
Es gilt:
\[s^2=\frac{1}{n-1}\sum(x_i-\bar{x})^2\]
Beidseitige Multiplikation mit \((n-1)\) liefert:
\[(n-1)\cdot s^2 = \sum(x_i-\bar{x})^2\]
Wir erinnern uns, dass eine \(\chi^2\)-Verteilung die Summe quadrierter, standardnormal-verteilter Variablen darstellt. In der Gleichung oben rechts werden quadrierte Variablen der Form \((x_i-\bar{x})\) aufsummiert - diese haben wie die Standardnormal-Verteilung einen Mittelwert von 0, da der Mittelwert ja von \(x_i\) subtrahiert wird. Beidseitige Division mit \(\sigma^2\) liefert:
\[(n-1)\cdot \frac{s^2}{\sigma^2} = \sum\left(\frac{x_i-\bar{x}}{\sigma}\right)^2\]
Die Terme \(\frac{x_i-\bar{x}}{\sigma}\) sind standardnormal-verteilt mit \(N(0,1)\), daher ist der Term rechts \(\chi^2\) verteilt mit \(df=n-1\) Freiheitsgraden.
Es gilt also:
\[(n-1)\cdot s^2/\sigma^2 \sim \chi^2_{df=n-1}\]
Die Quantile einer \(\chi^2\)-Verteilung zu \(df=n-1=9\) für das obige Beispiel können wir aber problemlos bestimmen, Sie lauten:
\(\chi^2_{df=9,2.5\%} = 2.700\) und \(\chi^2_{df=9,2.5\%} = 19.023\). \(s\) kann aus obiger Stichprobe zu \(s=1.764\) berechnet werden. Dies bedeutet, dass obiger Term nach \(\sigma\) umgeformt werden kann, einmal erhalten wir die Grenze durch Einsetzen der Grenze zu \(\alpha/2\) und einmal für \(1-\alpha/2\). Es gilt:
\[ s\cdot \sqrt{\frac{n-1}{\chi^2_{df=n-1,1-\alpha/2}}}< \sigma < s\cdot \sqrt{\frac{n-1}{\chi^2_{df=n-1,\alpha/2}}}\]
Einsetzen liefert:
\[ 1.764\cdot \sqrt{\frac{9}{19.023}}< \sigma < 1.764\cdot \sqrt{\frac{9}{2.700}}\]
\[1.213 < \sigma < 3.22\]
Es ist zu beachten, dass das Vertrauensintervall nicht symmetrisch um die Stichprobengrösse \(s\) verläuft. Mit untenstehender App können Sie weitere Vertrauensintervalle für Populationsstreuungen \(\sigma\) anhand von Stichproben berechnen und manuell überprüfen:
Quizz zu Vertrauensintervallen für Streuungen \(\sigma\)
Lösen Sie nun mit Hilfe obiger App und untenstehendem R-Code folgendes Quizz:
x<-c(0,50,100)
n<-length(x)
alpha<-0.1
sd(x)*sqrt((n-1)/qchisq(c(1-alpha/2,alpha/2),df=n-1))Vertrauensintervalle für Proportionen \(\pi\)
Zusätzlich zu Statistiken wie Mittelwerten oder Streuungen lassen sich auch Verhältniszahlen oder Proportionen \(p\) aus Stichproben errechnen. Zum Beispiel können wir uns fragen, wieviele Prozent der Befragten in einer Umfrage zum Abstimmverhalten mit “Ja” stimmen würden. Falls diese Grösse \(p\) mittels einer Zufallsstichprobe erhoben wurde, so kann man anschliessend ein Vertrauensintervall für \(\pi\), den “Ja”-Anteil in der Population, bestimmen.
Wir nehmen an, dass in einer Umfrage mit \(n=200\) Personen \(k=112\) angegeben haben, in der kommenden Abstimmung mit “Ja” zu stimmen. Für die Stichprobengrösse \(p\) erhält man:
\[p=\frac{k}{n}=\frac{112}{200} = 0.56\]
Die Summe der “Ja”-Stimmen ist unter der Annahme von konstanter Wahrscheinlichkeit \(\pi\) für eine “Ja”-Stimme binomialverteilt. Da wir uns hier aber die Wahrscheinlichkeit für die “Ja”-Stimmen von einzelnen Personen betrachten und nicht für die Summe aller Personen ergibt sich folgender Standardfehler:
\[\sigma(p) = \sqrt{\frac{p(1-p)}{n}}\]
Man beachte die Ähnlichkeit zur Standardabweichung unter der Binomial-Verteilung. Für unser konkretes Beispiel ergibt sich ein Standardfehler von
\[\sigma(p) = \sqrt{\frac{p(1-p)}{n}} = \sqrt{\frac{0.56(1-0.56)}{200}} = 0.035\]
Ähnlich wie bei den Mittelwerten folgen Stichprobenwerte \(p\) einer Verteilung. Als einfache Approximation kann die Normal-Verteilung hinzugezogen werden, falls folgende Bedingung erfüllt ist:
\[\sqrt{n\cdot p\cdot (1-p)}\geq 3\]
Falls diese Bedingung nicht erfüllt ist, kann zusätzlich geprüft werden, ob beide der folgenden Bedingungen erfüllt sind:
- \(n\cdot p \geq 5\), und
- \(n\cdot (1-p) \geq 5\)
Falls die Bedingungen erfüllt sind (in unserem Beispiel sind sie es), kann die Verteilung von \(p\) mit einer Normalverteilung angenähert werden. Man erhält somit für das Konfidenzintervall für \(\pi\) zum (beidseitigen) Niveau \(1-\alpha\):
\[p-z_{1-\frac{\alpha}{2}}\cdot \sigma(p) < \pi < p-z_{1-\frac{\alpha}{2}}\cdot \sigma(p)\]
\[p-z_{1-\frac{\alpha}{2}}\cdot \sqrt{\frac{p(1-p)}{n}} < \pi < p-z_{1-\frac{\alpha}{2}}\cdot \sqrt{\frac{p(1-p)}{n}}\]
Für die Konstruktion eines beidseitigen 95%-Intervalles gilt: \(z=1.96\) und man erhält:
\[0.56-1.96\cdot 0.035 < \pi < 0.56+1.96\cdot 0.035 \rightarrow 0.491 <\pi <0.629\]
Warum weist die Schätzung für \(\pi\) (also \(p=0.56\)) überhaupt einen Standardfehler auf? Eine erneute Zufalls-Stichprobe von \(n=200\) aus der Grundgesamtheit (von z.B. \(N=10'000\) Personen) würde ziemlich sicher nicht wieder einen exakten “Ja”-Anteil von \(k=112\) Stimmen abwerfen, sondern mal von \(k=105\), \(k=118\) oder \(k=108\). Diese Unsicherheit wird im Standardfehler von \(p\), \(\sigma(p)\), ausgedrückt.
Eine kurze Simulation zur Verteilung der Stichprobengrösse \(p\)
Nehmen wir an, dass in erwähnter Stadt, wo die Umfrage anhand einer Stichprobengrösse \(n=200\) erstellt wurde, \(N=10'000\) Personen leben. Nehmen wir gleichzeitig an, dass der “Ja”-Stimmen-Anteil tatsächlich \(\pi=0.56\) beträgt. Das heisst, dass von \(N=10'000\) Personen \(k=5600\) Personen das Merkmal “1” tragen (Person wird “Ja” stimmen) und \(n-k=4400\) Personen das Merkmal “0”.
Untenstehender R-Code erzeugt in Zeile 1 einen Vektor pop (wie Population), welcher aus den genannten \(4400\) 0-Einträgen und \(5600\) 1-Einträgen besteht.
In Zeile 2 wird \(n=200\) gesetzt und somit die Stichprobengrösse festgelegt. In Zeile 3 wird eine Zufalls-Stichprobe aus pop der Grösse n gezogen (ohne Zurücklegen, replace=FALSE, da eine Person nur einmal abstimmt.). In Zeile 4 wird der Anzeil “Ja”-Stimmen direkt berechnet und ausgegeben. Durch mehrmaliges Drücken des Buttons “Run” können Sie das Zufallsexperiment mehrmals wiederholen. Man stellt fest, dass mal mehr und mal weniger als ein Anteil von \(p=0.56\) ausgewiesen wird. Im Mittel scheinen aber die Stichprobengrössen \(p\) sich zum wahren \(\pi=0.56\) zu mitteln.
pop <- c(rep(0,4400),rep(1,5600))
n <- 200
x <- sample(pop,size=200,replace=FALSE)
length(which(x==1))/n
ps<-replicate(1000,length(which(sample(pop,size=200,replace=FALSE)==1))/n)
print("*******")
mean(ps)
sd(ps)
hist(ps)Um dies zu überprüfen, muss obiges Experiment nur mehrfach hintereinander ausgeführt werden, zum Beispiel \(1000\) mal. Dann kann der Mittelwert der resultierenden \(p\) und die Streuung berechnet werden. Dies erreicht man in der Zeile 6 mit dem Befehl replicate(1000,...). Der Platzhalter ... setzt dabei das x von Zeile 3 in die Zeile 4 ein und speichert die Wiederholungen im Vektor ps. Von diesem Vektor kann der Mittelwert und die Streuung gebildet werden. Der Mittelwert ist tatsächlich (so gut wie) identisch mit \(0.56\) und die Streuung der simulierten \(p\) aus den \(1000\) Stichproben ist (so gut wie) identisch mit \(\sigma(p)=0.035\). Zusätzlich wird mittels des Befehls hist(ps) ein Histogramm der simulierten ps produziert.
Beispiel zur Berechnung von Vertrauensintervallen für \(\pi\)
Mittels untenstehender App können Sie ein Vertrauensintervall für \(\pi\) anhand einer eigenen Stichprobe erstellen. Geben Sie hierfür die Stichprobengrösse \(n\) und die Anzahl Beobachtungen mit dem gewünschten Merkmal (Z.B. die Anzahl “Ja”-Stimmen) \(k\) an.
Lösen Sie nun mit obenstehender App folgendes Quiz:
Illustration Ziehen einer Zufalls-Stichprobe für Einkommen
Einstellungen für Grundgesamtheit
Histogramm der Populations-Einkommen
Rückschluss von der Stichprobe auf die Grundgesamtheit
Berechnen der Stichprobengrösse \(n\) für vorgegebene Stichprobenfehler und FPC-Korrektur
Aufgrund der vorgängig definierten Grössen in der Berechnung von Vertrauensintervallen für Verhältniszahlen \(\pi\) definieren wir den Stichprobenfehler zum beidseitigen Signifikanzniveau \(1-\alpha\) (z.B. \(1-\alpha=95\%\)):
Der Stichprobenfehler \(e\) (wobei \(e\) für error steht) ist die halbe Länge des Vertrauensintervalles für \(\pi\), somit:
\[e = z_{1-\alpha/2}\cdot \sigma_p = z_{1-\alpha/2}\cdot \sqrt{\frac{p\cdot(1-p)}{n}} \]
Beim Design von Zufalls-Stichproben stellt man sich die Frage, wie viele Individuen \(n\) zu befragen sind, wenn der Stichprobenfehler eine gewisse Grenze \(e^*\) nicht überschreiten soll, also
\[e = z_{1-\alpha/2}\cdot \sigma_p = z_{1-\alpha/2}\cdot \sqrt{\frac{p\cdot(1-p)}{n}} < e^*\]
Auflösen nach \(n\) liefert:
\[\frac{z_{1-\alpha/2}^2\cdot p\cdot(1-p)}{e^{*^2}} <n \]
Beispiel:
Man möchte eine Stichprobe so designen, dass der Stichprobenfehler auf dem beidseitigen Signifikanzniveau \(1-\alpha=95\%\) in jedem Fall eine Grenze von \(e=2\%\) nicht überschreitet. Wie gross muss der Stichprobenumfang \(n\) gewählt werden?
Lösung:
Dem Leser fällt wahrscheinlich auf, dass die Grösse \(p\) im Aufgabentext nicht spezifiziert wurde. Diese Situation ist natürlich in der Praxis ebenfalls der Fall - denn zum Zeitpunkt der Stichprobenplanung ist das Stichprobenverhältnis \(p\) für das zu interessierende Merkmal noch unbekannt. Allenfalls hat man eine Ahnung von \(p\) und tätigt eine Annahme. Betrachtet man aber die Formel für den Stichprobenfehler \(e\) so sieht man, dass dieser für \(p=0.5\) maximal wird. Wird somit eine Stichprobe unter der Annahme \(p=0.5\) geplant, so wird der Stichprobenfehler maximal sein, und man wird dann nach Realisierung der Stichprobe sicherlich nicht über der gewünschten Grenze \(e^*\) liegen. Man erhält:
\[\frac{z_{1-\alpha/2}^2\cdot p\cdot(1-p)}{e^{*^2}} <n \]
\[\frac{1.96^2\cdot 0.5 \cdot 0.5}{0.02^2} = 2400.9 <n \]
Streng genommen ist somit eine Stichprobengrösse von \(n=2401\) zu wählen.
Wird die Stichprobe nun durchgeführt und man erhält ein Stichprobenverhältnis von \(p=0.4\) mit \(n=2401\) Teilnehmenden, so beläuft sich der Stichprobenfehler \(e\) auf \(e=1.96\cdot \sqrt{\frac{0.4 \cdot 0.6}{2401}} = 0.0196 = 1.96\%\). Er liegt also leicht unter den geforderten \(e=2\%\).
Hätte man ein Stichprobenverhältnis von rothaarigen Personen erhoben, so würde die Verhältniszahl mit Sicherheit einiges kleiner werden, zum Beispiel \(p=3\%\). Der Stichprobenfehler wäre dann \(e=1.96\cdot \sqrt{\frac{0.03 \cdot 0.97}{2401}} = 0.0068 = 0.68\%\). Beim Planen von Stichproben kann also eine vorgängige Ahnung für \(p\) eingesetzt werden. Hätte man vorgängig angenommen, dass \(p=5\%\) Personen in der Stichprobe rothaarig wären, so hätte man einen Stichprobenumfang von \(\frac{1.96^2\cdot 0.05 \cdot 0.95}{0.02^2} = 456.2 <n\) berechnet, also eine Befragung mit nur \(n=457\) Teilnehmenden.
Die Finite-Population-Correction (FPC)
Die FPC-Korrektur berücksichtigt das Vorliegen von sehr grossen Stichproben \(n\) im Verhältnis zur Populationsgrösse \(N\). Die FPC-Korrektur wird angewandt, falls die Stichprobengrösse \(n\) anteilig an der Population \(N\) 5% oder mehr beträgt.
\[\frac{n}{N}>0.05 \]
Der Standardfehler unter FPC-Korrektur lautet:
\[\sigma_{p,FPC}=\sqrt{\frac{p\cdot(1-p)}{n}} \cdot \sqrt{\frac{N-n}{N-1}} = \sigma_p \cdot \sqrt{\frac{N-n}{N-1}}\]
Der Standardfehler unter FPC ändert sich im Vergleich zum vorherigen Fall (Nichtbeachtung der Populationsgrösse \(N\)) nur um den FPC-Faktor \(\sqrt{\frac{N-n}{N-1}}\). Folgende zwei Überlegungen sich zu berücksichtigen:
- Falls die Populationsgrösse sehr gross ist (\(N \rightarrow \infty\)), so wird der FPC-Faktor gleich eins (\(\sqrt{\frac{N-n}{N-1}} \rightarrow 1\)). Das heisst, für sehr grosse Populationen ist einfach \(\sigma_p\) als Standardfehler für \(p\) zu benutzen.
- Falls eine Vollerhebung vorliegt und als Stichprobengrösse \(n\) die gesamte Population gewählt wird (also \(n=N\)), so wird der FPC-Faktor zu Null. Das heisst, der Standardfehler lautet in dem Fall: \(\sigma_{p,FPC}=0\).
Diese Überlegungen sind umso wichtiger, je nachdem wie die zugrunde liegende Population definiert wird. Ist dies die deutsche Bevölkerung mit gut \(N=83\) Millionen Einwohner, so ist die FPC-Korrektur sehr selten (oder nie) anzuwenden. Ist die zugrunde liegende Population aber die Mitarbeitenden eines Unternehmens mit \(N=2000\) Mitarbeitenden, so ist die \(FPC\)-Korrektur ziemlich sicher anzuwenden, da es wahrscheinlich ist, dass man eine Stichprobe von \(n\) grösser als 5% von \(N=2000\) erwischt (also \(n>100\)).
Berechnen der Stichprobengrösse \(n\) unter der FPC-Korrektur
Will man eine Zufallsstichprobe \(n\) aus der Population \(N\) so auslegen, dass der Stichprobenfehler \(e\) die maximale Grösse \(e^*\) erreicht, so gilt:
\[ \frac{N\cdot z_{1-\alpha/2}^2\cdot p\cdot(1-p)}{(N-1)\cdot e^{*^2}+ z_{1-\alpha/2}^2\cdot p\cdot(1-p)} < n\]
Angenommen, man möchte einen Stichprobenfehler von maximal \(e^*=2\%\) zum beidseitigen Signifikanzniveau von \(1-\alpha=95\%\) einhalten, falls die Populationsgrösse \(N=2000\) beträgt, so gilt für die zu planende Stichprobengrösse \(n\):
\[ \frac{N\cdot z_{1-\alpha/2}^2\cdot p\cdot(1-p)}{(N-1)\cdot e^{*^2}+ z_{1-\alpha/2}^2\cdot p\cdot(1-p)} <n\]
\[ \frac{2000\cdot 1.96^2\cdot 0.5\cdot(1-0.5)}{(2000-1)\cdot 0.02^{^2}+ 1.96^2\cdot 0.5\cdot(1-0.5)} = 1091.4 < n \]
Es ist also eine Stichprobe mit \(n=1092\) Teilnehmenden zu planen.
Quiz zur FPC-Korrektur:
Auf der nachfolgenden Seite erhalten Sie eine kompakte App zum Berechnen der Vertrauensintervalle für:
- den Populationsmittelwert \(\mu\) aus den Stichprobengrössen \(\bar{x}\), \(s\) und \(n\) zum beidseitigen Signifikanzniveau \(1-\alpha\) unter der t-Verteilung.
- die Populationsstreuung \(\sigma\) aus den Stichprobengrössen \(s\) und \(n\) zum beidseitigen Signifikanzniveau \(1-\alpha\) unter der \(\chi^2\)-Verteilung
- das Populationsverhältnis \(\pi\) aus den Stichprobengrössen \(p\), \(n\) und \(N\) zum beidseitigen Signifikanzniveau \(1-\alpha\) unter der Normal-Verteilung. Zusätzlich zur vorherigen App kann \(N\) im Rahmen der FPC-Korrektur geändert werden.
APP für Vertrauensintervalle
Vertrauensintervalle für den Populationsmittelwert \(\mu\)
Vertrauensintervalle für die Populationsstreuung \(\sigma\)
Vertrauensintervalle für das Populationsverhältnis \(\pi\)
Übungs-Generator für schriftliche Aufgaben
Hier können Sie sich Lehrkräfte und Studierende schriftliche Übungen nach Zufallsprinzip generieren lassen. Die Übungen werden in ein Word-Dokument mit Lösungen geschrieben und dieses kann dann zum Zweck eigener Formatierungen noch angepasst werden. Diese Übungen beinhalten (fast) keine R-basierten Aufgaben sondern nur solche, die im Rahmen einer schriftlichen Aufgabe lösbar sind. Die Aufgabensätze werden als Word-Dokument generiert und können nach eigenen Bedürfnissen formatiert werden.