
Mittelwerte testen: Der t-test für eine Stichprobe
Das Wichtigste in Kürze

Gegeben sind Beobachtungen einer Zufallsvariable \(X\), nämlich die Körpergewichte von \(n=20\) Jugendlichen:
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
34 | 44 | 45 | 47 | 50 | 50 | 53 | 56 | 56 | 58 |
11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
58 | 62 | 66 | 67 | 69 | 76 | 78 | 80 | 86 | 94 |
Aus einer Fachzeitschrift erfährt man, dass der Mittelwert der Population, also das mittlere Gewicht aller Jugendlichen mit \(\mu=69\) Kilogramm angegeben wird.
- Die Frage beim Testen ist, ob die Hypothese zum Populations-Parameter \(\mu\) mit der Stichprobe \(x\) vereinbar ist.
- Parameter aus der Grundgesamtheit werden mit griechischen Buchstaben bezeichnet, z.B. der Mittelwert in der Population mit \(\mu\).
- Parameter aus der Stichprobe werden mit lateinischen Buchstaben, z.B. der Mittelwert in der Stochprobe mit \(\bar{x}\).
Berechnen Sie nun mit untenstehendem R-Code den Stichproben-Mittelwert \(\bar{x}\) und die Stichproben-Streuung \(s\).
x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)
m<-mean(x)
s<-sd(x)
m
sDie Grössen aus der Stichprobe lauten somit: \(\bar{x}=61.45\), \(s=15.48\) und \(n=20\).
Das Vorgehen beim Testen fassen wir in untenstehender Liste zusammen:
- Schritt: Formulieren der Null- und Alternativ-Hypothesen \(H_0\) und \(H_A\)
- Schritt: Wahl des Signifikanzniveau \(1-\alpha\)
- Schritt: Berechnen der Test-Statistik
- Schritt: Konstruktion des Annahme- und Verwerfungs-Bereichs
- Schritt: Test-Entscheid
Schritt 1: Formulieren der Null- und Alternativ-Hypothesen \(H_0\) und \(H_A\)
Die Nullhypothese \(H_0\) ist eine Aussage über den Populationsparameter \(\mu\). Die Behauptung gemäss Fachzeitschrift lautet:
\[H_0: \mu=69\]
Die Alternativhypothese \(H_A\) ist das Gegenteil von \(H_0\). Somit lautet sie:
\[H_A: \mu \neq 69\]
\(H_0\) hat immer etwas mit einem Test auf Gleichheit zu tun, \(H_A\) mit Ungleichheit. So, wie unsere Hypothesen aktuell formuliert sind, sprechen wir von einem beidseitigen Test, da die in \(H_A\) ausgedrückte Ungleichheit (\(\neq\)) bedeutet, dass der wahre aber unbekannte Mittelwert in der Population kleiner oder grösser als der Wert unter der Nullhypothese \(H_0: \mu=69\) ist.
Es gibt auch eine einseitige Test-Strategie. Unser Stichprobenmittelwert \(\bar{x}=61.45\) könnte die Vermutung aufkommen lassen, dass unter \(H_A\) der wahre Populationsmittelwert signifikant kleiner als \(69\) ist. Unter einseitigem Testen wäre die Formulierung also:
\[H_0: \mu=69\] oder allenfalls \[H_0:\mu \geq 69\]
und
\[H_A: \mu < 69\]
Wir testen zuerst einseitig.
Schritt 2: Wahl des Signifikanzniveau \(1-\alpha\)
Das Signifikanzniveau \(1-\alpha\) ist eine gewählte Wahrscheinlichkeit, zu welcher die Nullhypothese \(H_0\) angenommen wird. Die Wahrscheinlichkeit \(\alpha\) ist jene, zu welcher die Alternativhypothese \(H_A\) angenommen (und \(H_0\) verworfen) wird.
Typischerweise wählt man \(1-\alpha\) zu 90%, 95% oder 99% und somit \(\alpha\) zu 10%, 5% oder 1%. Wenn nichts spezifisches erwähnt wird, so wählt man das Signifikanzniveau \(1-\alpha=95\%\). Wir können Schritt 1 und Schritt 2 zusammen erledigen, indem wir aufschreiben:
\[H_0:\mu \geq 69, \texttt{ zu } 1-\alpha=95\%\]
\[H_A: \mu < 69, \texttt{ zu } \alpha=5\%\]
Schritt 3: Berechnen der Test-Statistik
Die Test-Statistik überprüft, wie weit der erhobene Parameter der Stichprobe, also der Mittelwert \(\bar{x}\), von dem hypothetischen Wert der Grundgesamtheit, also \(H_0: \mu=69\), entfernt ist. Die Test-Statistik lautet:
\[t=\frac{\bar{x} - \mu}{\frac{s}{\sqrt{n}}}\]
Der Zähler des Bruches \(\bar{x}-\mu\) überprüft, wie weit der Stichprobenmittelwert vom hypothetischen Populationsmittel entfernt ist. Der Nenner ist der Standardfehler des Mittelwertes. Eine Test-Statistik berechnet also die Entfernung der Stichprobe zu \(H_0\), ausgedrückt in Anzahl Standardfehler. Ist die Entfernung “klein”, so wird \(H_0\) beibehalten. Ist sie gross, so wird \(H_0\) verworfen. Die Test-Statistik wird mit \(t\) bezeichnet, dies bedeutet für uns, dass der berechnete Wert einer \(g\) Verteilung mit \(df=n-1\) folgt. Falls der Stichprobenmittelwert \(\bar{x}\) gerade identisch mit dem Populationsmittelwert \(\mu\) ist, lautet die t-Statistik \(t=0\), was dem Erwartungswert der t-Verteilung entspricht.
Die \(t\) Statistik berechnet sich zu:
\[t = \frac{61.45-69}{\frac{15.48}{\sqrt{20}}}= -2.181\]
Schritt 4: Konstruktion des Annahme- und Verwerfungs-Bereichs
Die \(t\)-Statistik ist \(t\)-verteilt mit \(df=n-1=19\) Freiheitsgraden. Da die Alternativ-Hypothese \(H_A\) einseitig nach unten (\(H_A: \mu < 69\)) formuliert ist, wird die Wahrscheinlichkeitsmasse \(\alpha=5\%\) in den unteren Bereich der Verteilung gelegt wird.
Gemäss Tabelle liegt dieses Quantil bei \(t_{5\%,df=19} = -1.729\)
Dieses Quantil wird untenstehend durch das rote Kreuz markiert und trennt den Annahmebereich von \(H_0\) vom Verwerfungsbereich von \(H_0\).
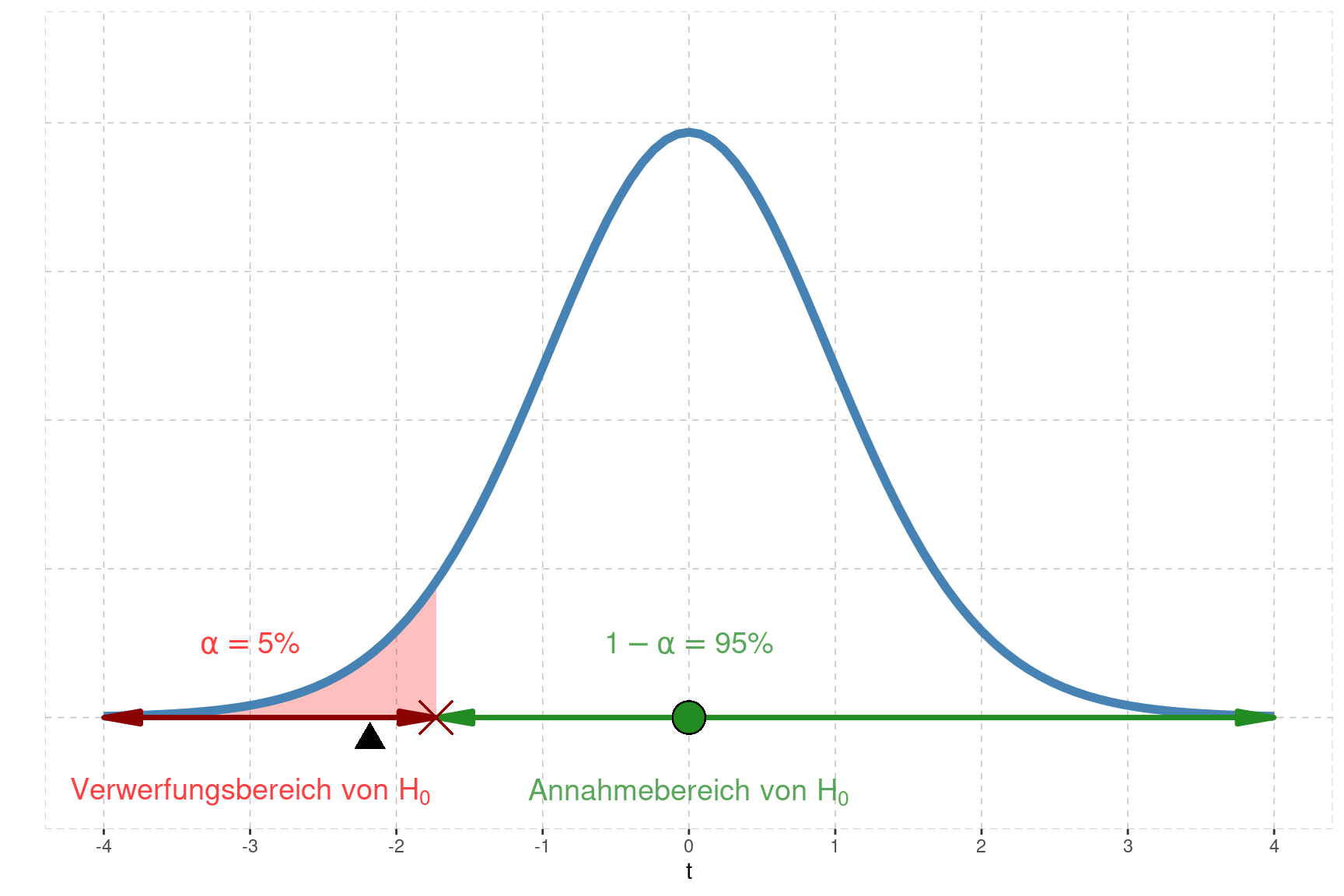
Eine Bedeutung hat der Wert \(t=0\), welcher in der Grafik mit einem grünen Punkt markiert ist. Wäre nämlich der Stichprobenmittelwert \(\bar{x}\) gerade identisch zum hypothetischen Populationsmittel unter \(H_0\), so wäre natürlich \(t=0\) und die Nullhypothese wäre ‘perfekt’ mit der Stichprobe vereinbar. Je weiter wir uns aber nun nach unten weg von diesem grünen Punkt bewegen, umso eher trifft die Alternative \(H_A: \mu<69\) zu.
Da wir der Alternative \(\alpha=5\%\) Gewicht geben wird die Nullhypothese verworfen, sobald die Test-Statistik \(t\) in den roten Bereich fällt. Diese Grenze liegt wie erwähnt bei \(t_{5\%,df=19} = -1.729\).
Schritt 5: Test-Entscheid
Unsere Test-Statistik \(t=-2.181\), markiert mit dem schwarzen Dreieck, fällt offensichtlich in den Verwerfungsbereich von \(H_0\). Das bedeutet nun, dass auf dem Signifikanz-Niveau \(1-\alpha=95\%\) die Nullhypothese \(\mu=69\) nicht mit der erhobenen Stichprobe vereinbar ist.
Mit statistischer Software wird übrigens meist nur der sogenannte \(p\)-Wert (oder \(p\)-value) ausgegeben.
Der \(p\)-Wert ist die Wahrscheinlichkeit, ein noch extremeres Test-Resultat zu sehen.
Noch extremer heisst in unserem Fall, eine Test-Statistik zu beobachten, die eben noch weiter von \(H_0\) entfernt ist, als dass wir es ohnehin schon sind. Dies entspricht der Fläche unter der \(t\)-Verteilung mit \(df=19\) zwischen \(t=-2.181\) und \(-\infty\). Gemäss Tabelle der \(t\)-Verteilung liegt diese Fläche zwischen \(p=5\%\) und \(p=4\%\) beidseitig (die Tabelle ist beidseitig aufgestellt), der einseitige \(p\)-Wert liegt somit zwischen \(p=2.5\%\) und \(p=2\%\). Da diese Fläche kleiner als \(\alpha=5\%\) ist, wird \(H_0\) verworfen. Wir merken uns:
Der \(p\)-Wert ist die Wahrscheinlichkeit, ein noch extremeres Test-Resultat zu sehen. Falls \(p<\alpha\), so wird \(H_0\) verworfen.
Testen mir R
Mit der Funktion t.test() können wir mit R einen \(t\)-Test berechnen.
x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)
t.test(x,mu=69,alternative="less")Wir sehen, dass R einen \(p\)-Wert von \(p=2.1\%\) ausgibt. Da \(p=2.1\% < \alpha=5\%\) ist, wird \(H_0\) verworfen. Der Populationsparameter \(\mu\) liegt statistisch signifikant unter 69 (im Sinne von \(H_A\)).
Beidseitiges Testen
Wir wiederholen die obigen fünf Schritte für beidseitiges Testen.
Schritte 1 und 2: Formulieren der Hypothesen und Wahl des Signifikanzniveau \(1-\alpha\)
\[H_0:\mu = 69, \texttt{ zu } 1-\alpha=95\%\]
\[H_A: \mu \neq 69, \texttt{ zu } \alpha=5\%\]
Wie Sie sehen testen wir unter der Alternative nun auf ungleich (\(\neq\)) und nicht auf kleiner (\(<\)). Das heisst, wir verwerfen \(H_0\) nun bei grossen Abweichungen nach unten oder nach oben.
Schritt 3: Berechnen der Test-Statistik
Die \(t\) Statistik berechnet sich zu:
\[t = \frac{61.45-69}{\frac{15.48}{\sqrt{20}}}= -2.181\]
Sie sehen, der \(t\)-Wert ändert sich nicht.
Schritt 4: Konstruktion des Annahme- und Verwerfungs-Bereichs
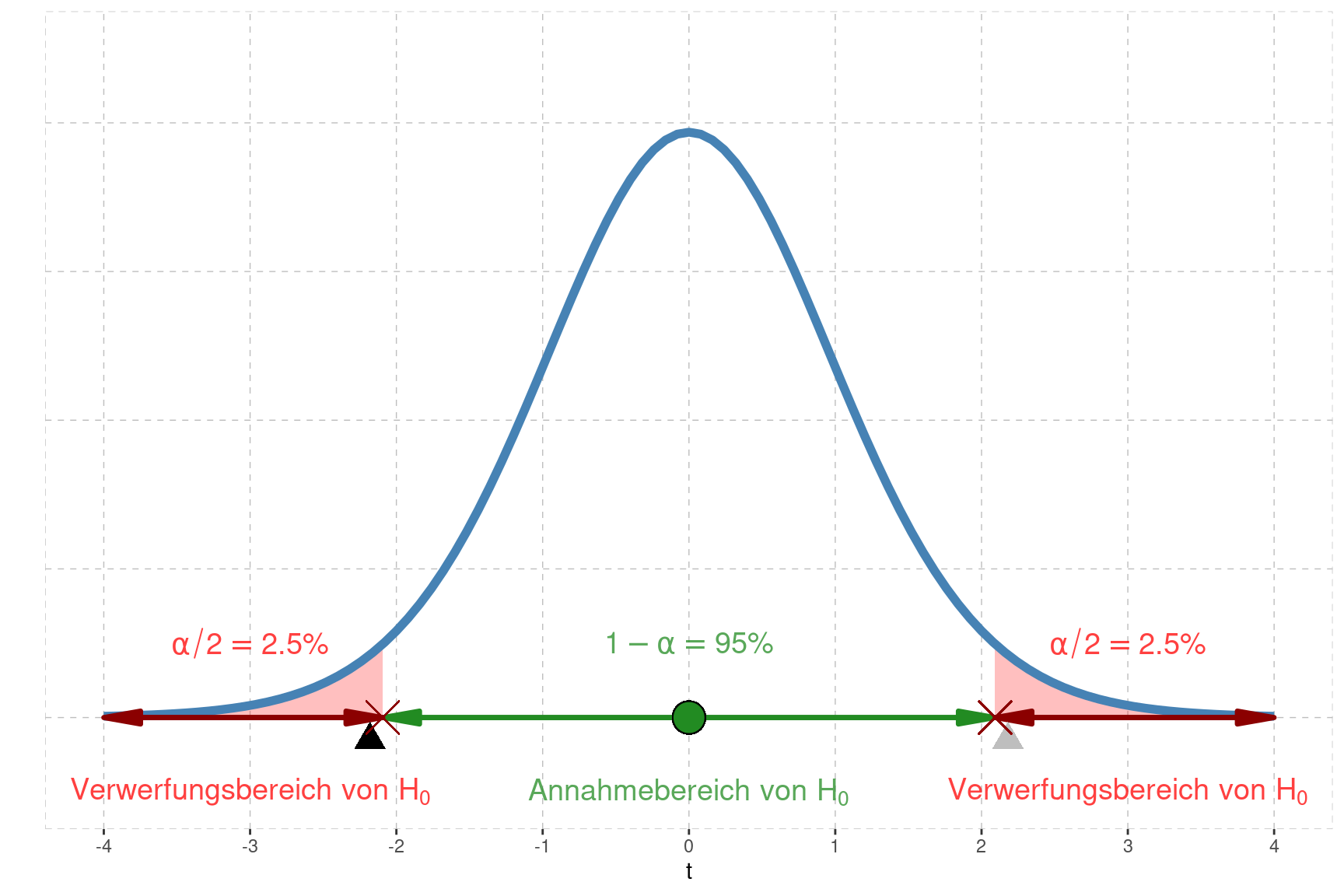
Beim beidseitigen Testen wird der Verwerfungsbereich in beide Enden der Verteilungen gelegt, und zwar jeweils hälftig zu \(\frac{\alpha}{2}=2.5\%\). Die Quantile, wiederum markiert mit einem roten Kreuz, lauten nun \(t_{2.5\%,97.5\%,df=19}=\pm 2.093\).
Schritt 5: Test-Entscheid
Unsere Test-Statistik \(t=-2.181\), markiert mit dem schwarzen Dreieck, fällt offensichtlich knapp in den Verwerfungsbereich von \(H_0\). Das bedeutet nun, dass auf dem Signifikanz-Niveau \(1-\alpha=95\%\) die Nullhypothese \(\mu=69\) nicht mit der erhobenen Stichprobe vereinbar ist.
Der p-Wert ist nun aber doppelt so gross wie beim einseitigen Testen. Die Fläche unterhalt der Test-Statistik \(t=-2.181\) lautet nach wie vor \(2.1\%\). Da aber beidseitig getestet wird, muss auch die Fläche hinter der ‘gespiegelten’ Test-Statistik, die gleich gross ist, berücksichtigt werden. Der \(p\)-Wert beim beidseitigen Testen lautet: \(p=2\cdot 2.1\%=4.2\%\). Mit der Tabelle hätte man gesagt, dass der \(p\)-Wert zwischen \(4\%\) und \(5\%\) liegen muss. Da gilt: \(p<\alpha\) wird \(H_0\) wiederum verworfen.
Testen mir R
Mit der Funktion t.test() können wir mit R einen \(t\)-Test berechnen.
x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)
t.test(x,mu=69,alternative="two.sided")Wir sehen, dass R einen \(p\)-Wert von \(p=4.2\%\) ausgibt. Da \(p=4.2\% < \alpha=5\%\) ist, wird \(H_0\) verworfen. Der Populationsparameter \(\mu\) liegt statistisch signifikant unter 69 (im Sinne von \(H_A\)).
Varianzen testen - der \(\chi^2\)-Test für eine Stichprobe
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
34 | 44 | 45 | 47 | 50 | 50 | 53 | 56 | 56 | 58 |
11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
58 | 62 | 66 | 67 | 69 | 76 | 78 | 80 | 86 | 94 |
Wir erinnern uns: Der Stichprobenmittelwert beträgt \(\bar{x}=61.45\) und die Streuung beträgt \(s=15.48\).
Wir haben vorhin obige Stichprobe auf eine Hypothese hinsichtlich des Populationsparameters \(\mu\) getestet. Getestet werden soll nun die Behauptung, dass die Streuung in der Grundgesamtheit \(\sigma=20\) beträgt. Wir folgen nun den gleichen Schritten wie beim Testen für Mittelwerte.
Schritte 1 und 2: Formulieren der Hypothesen und Wahl des Signifikanzniveau \(1-\alpha\)
\[H_0:\sigma = 20, \texttt{ zu } 1-\alpha=95\%\]
\[H_A: \sigma \neq 20, \texttt{ zu } \alpha=5\%\]
Schritt 3: Berechnen der Test-Statistik
Die Test-Statistik heisst:
\[\chi^2 = \frac{(n-1)\cdot s^2}{\sigma^2} \texttt{ mit } df=n-1\]
Interpretieren wir kurz diese Formel. Wie gross wird diese Test-Statistik, wenn die Streuung aus der Stichprobe \(s\) exakt gleich gross wie die hypothetische Streuung unter \(H_0\) ist (also gleich \(\sigma\)). Die Test-Statistik lautet dann \(\chi^2=n-1\). Wir erinnern uns, dass der Erwartungswert einer \(\chi^2\)-Verteilung gleich \(df=n-1\) ist.
Wir berechenen die Test-Statistik:
\[\chi^2 = \frac{(n-1)\cdot s^2}{\sigma^2} = \frac{19\cdot 15.48^2}{20^2} = 11.39\]
Wie erwähnt, falls der Stichprobenwert perfekt zum hypothetischen Wert unter \(H_0\) passen würde, müsste die Grösse \(df=n-1=19\) sein. Die Frage ist nun, ob der berechnete Test-Wert zu weit von diesem Wert entfernt ist.
Schritt 4: Konstruktion des Annahme- und Verwerfungs-Bereichs
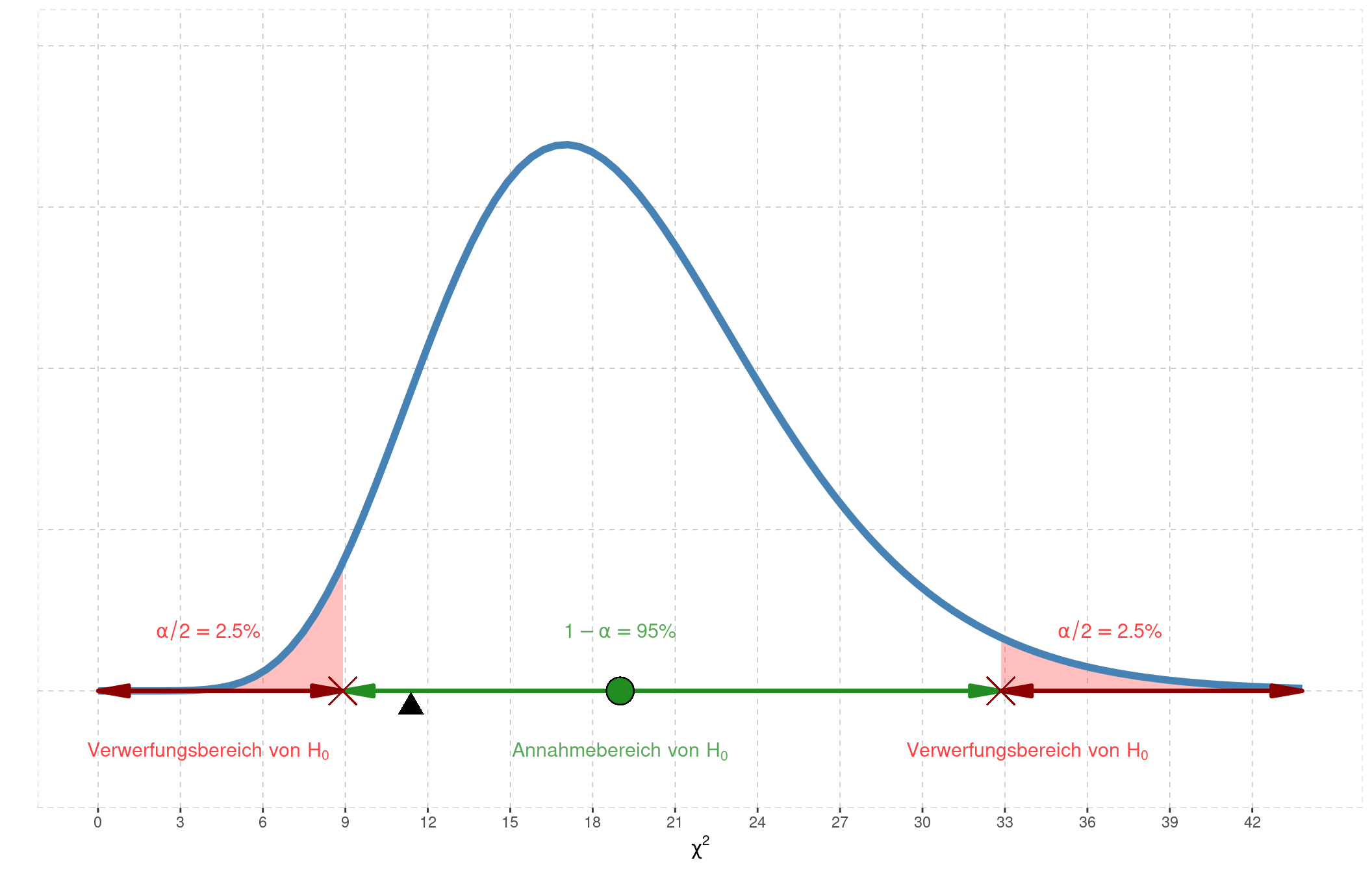
Beim beidseitigen Testen zum Niveau \(1-\alpha=95\%\) legen wir zur Konstruktion des Annahme- und Verwerfungsbereichs die 95% Masse in die Mitte, 2.5% ins untere und 2.5% ins obere Ende der Verteilung. Die Quantile, welche Annahme- von Verwerfungsbereich trennen, lauten:
\(\chi^2_{2.5\%,df=19} = 8.91\) und \(\chi^2_{97.5\%,df=19} = 32.85\).
Diese Quantile sind obenstehend mit roten Kreuzen markiert.
Schritt 5: Test-Entscheid
Unsere Test-Statistik \(\chi^2=11.387\), markiert mit dem schwarzen Dreieck, fällt offensichtlich nicht in den Verwerfungsbereich von \(H_0\). Das bedeutet nun, dass auf dem Signifikanz-Niveau \(1-\alpha=95\%\) die Nullhypothese \(\sigma=20\) mit der erhobenen Stichprobe vereinbar ist.
Der p-Wert kann mit Hilfe der Tabelle abgelesen werden: Das 10%-Quantil zu \(df=19\) lautet: 11.651. Somit ist die Fläche links von der schwarzen Test-Statistik kleiner als 10%, z.B. 9%. Die beidseitige Fläche approximieren wir somit zu \(2\cdot 9\% = 18%\). Da nun gilt \(p>\alpha=5\%\) behalten wir die Nullhypothese \(H_0\) bei.
Testen mit R
Im R-package EnvStats (das Sie allenfalls selbst noch mit dem Befehl install.packages('EnvStats') installieren und dieses nach Installation mit dem Befehl library(EnvStats) aufrufen) ist der Befehl varTest() installiert. Erzeugen Sie in untenstehendem R-Code eine Variable x mit den Gewichten anlegen und diese nachher auf eine Streuung von \(\sigma=20\) testen:
x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)
varTest(x,alternative="two.sided",conf.level=0.95,sigma.squared=20^2)Wie Sie sehen lautet die Test-Statistik 11.387, der p-Wert ist wie vorhin berechnet ca. 18%, das heisst die Nullhypothese \(\sigma=20\) wird beibehalten. Zusätzlich ist das Vertrauensintervall für \(\sigma^2\) berechnet. Da der Wert der Varianz unter \(H_0\) \(\sigma^2=20^2=400\) beträgt und dieser Wert im Vertrauensintervall beinhaltet ist, behalten wir \(H_0\) bei.
Überlegen wir uns kurz, wie die Schritte beim einseitigen Testen erfolgt wären?
Schritte 1 und 2: Formulieren der Hypothesen und Wahl des Signifikanzniveau \(1-\alpha\)
\[H_0:\sigma = 20, \texttt{ zu } 1-\alpha=95\%\]
\[H_A: \sigma < 20, \texttt{ zu } \alpha=5\%\]
Schritt 3: Berechnen der Test-Statistik
Die Test-Statistik heisst:
\[\chi^2 = \frac{(n-1)\cdot s^2}{\sigma^2} \texttt{ mit } df=n-1\]
Wie schon beim einseitigen Mittelwert-Testen bleibt die Test-Statistik natürlich gleich.
\[\chi^2 = \frac{(n-1)\cdot s^2}{\sigma^2} = \frac{19\cdot 15.48^2}{20^2} = 11.39\]
Wie erwähnt, falls der Stichprobenwert perfekt zum hypothetischen Wert unter \(H_0\) passen würde, müsste die Grösse \(df=n-1=19\) sein. Die Frage ist nun, ob der berechnete Test-Wert zu weit von diesem Wert entfernt ist.
Schritt 4: Konstruktion des Annahme- und Verwerfungs-Bereichs
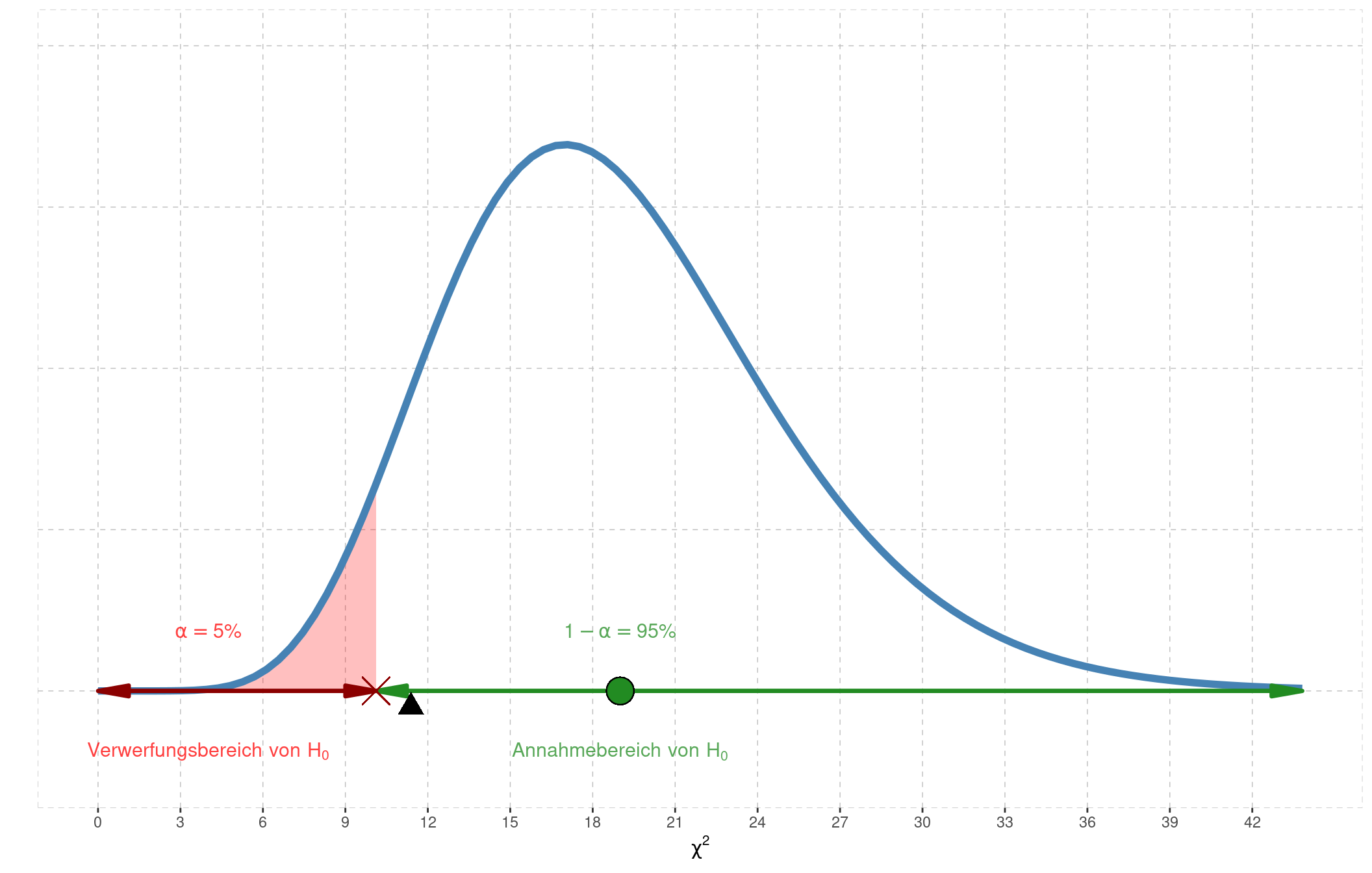
Beim einseitigen Testen zum Niveau \(1-\alpha=95\%\) legen wir zur Konstruktion des Annahme- und Verwerfungsbereichs die 95% Masse nach oben, 5% ins untere Ende. Das Quantil lautet:
\(\chi^2_{5\%,df=19} = 10.12\)
Das Quantil ist obenstehend mit einem roten Kreuz markiert.
Schritt 5: Test-Entscheid
Unsere Test-Statistik \(t=11.387\), markiert mit dem schwarzen Dreieck, fällt offensichtlich nicht in den Verwerfungsbereich von \(H_0\). Das bedeutet nun, dass auf dem Signifikanz-Niveau \(1-\alpha=95\%\) die Nullhypothese \(\sigma=20\) mit der erhobenen Stichprobe vereinbar ist.
Der p-Wert kann mit Hilfe der Tabelle abgelesen werden: Das 10%-Quantil zu \(df=19\) lautet: 11.651. Somit ist die Fläche links von der schwarzen Test-Statistik kleiner als 10%, z.B. 9%.
Testen mit R
Im R-package EnvStats (das Sie allenfalls selbst noch mit dem Befehl install.packages('EnvStats') installieren und dieses nach Installation mit dem Befehl library(EnvStats) aufrufen) ist der Befehl varTest() installiert. Erzeugen Sie in untenstehendem R-Code eine Variable x mit den Gewichten anlegen und diese nachher auf eine Streuung von \(\sigma=20\) testen:
x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)
varTest(x,alternative="less",conf.level=0.95,sigma.squared=20^2)Wie Sie sehen lautet die Test-Statistik 11.387, der p-Wert ist wie vorhin berechnet ca. 9%, das heisst die Nullhypothese \(\sigma=20\) wird beibehalten. Zusätzlich ist das Vertrauensintervall für \(\sigma^2\) berechnet. Da der Wert der Varianz unter \(H_0\) \(\sigma^2=20^2=400\) beträgt und dieser Wert im Vertrauensintervall beinhaltet ist, behalten wir \(H_0\) bei.
Auf Verteilungen testen - der Kolmogorov-Test
1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
34 | 44 | 45 | 47 | 50 | 50 | 53 | 56 | 56 | 58 |
11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
58 | 62 | 66 | 67 | 69 | 76 | 78 | 80 | 86 | 94 |
Wir wollen nun die oben dargestellten Daten auf eine Verteilungsform testen. So können wir unter Schritt 1 und 2 wiederum Hypothesen mit zugehörigem Signifikanzniveau aufstellen:
\(H_0\): Die Daten sind normal-verteilt mit \(\mu=60\) und \(\sigma=12\), zu \(1-\alpha=95\%\)
\(H_A\): Die Daten sind nicht normal-verteilt mit \(\mu=60\) und \(\sigma=12\), zu \(\alpha=5\%\)
Das Vorgehen beim Kolmogorov-Smirnov-Test (kurz KS-Test) ist wie folgt:
- Daten sortieren (aufsteigend, schon erledigt)
- kumulierte Verteilung der theoretischen Verteilung berechnen, \(\phi(x)\) oder \(F(x)\)
- empirische Perzentile \(f_i=\frac{i}{n}\) berechnen
- Absolute Distanzmasse \(d_i=|\phi(x)-f_i|\) berechnen
- Test-Statistik: \(KS=max(d_i)\) berechnen
Berechnen Sie aus dem untenstehenden Vektor x die erwähnten Schritte:
x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)
x<-sort(x)
phi<-pnorm(x,60,12)
fi<-(1:length(x))/length(x)
di<-abs(phi-fi)
ks<-max(di)
print(ks)i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
x | 34 | 44 | 45 | 47 | 50 | 50 | 53 | 56 | 56 | 58 |
phi | 0.015 | 0.091 | 0.106 | 0.139 | 0.202 | 0.202 | 0.28 | 0.369 | 0.369 | 0.434 |
fi | 0.05 | 0.1 | 0.15 | 0.2 | 0.25 | 0.3 | 0.35 | 0.4 | 0.45 | 0.5 |
di | 0.035 | 0.009 | 0.044 | 0.061 | 0.048 | 0.098 | 0.07 | 0.031 | 0.081 | 0.066 |
i | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
x | 58 | 62 | 66 | 67 | 69 | 76 | 78 | 80 | 86 | 94 |
phi | 0.434 | 0.566 | 0.691 | 0.72 | 0.773 | 0.909 | 0.933 | 0.952 | 0.985 | 0.998 |
fi | 0.55 | 0.6 | 0.65 | 0.7 | 0.75 | 0.8 | 0.85 | 0.9 | 0.95 | 1 |
di | 0.116 | 0.034 | 0.041 | 0.02 | 0.023 | 0.109 | 0.083 | 0.052 | 0.035 | 0.002 |
Wie wir sehen ist das Maximum der Differenz vom theoretischen zum empirischen Perzentil an der Stelle 11 mit \(d_i=0.116\).
Würde unsere empirische Verteilung perfekt einer \(N(\mu=60,\sigma=12)\)-Verteilung entsprechen, so wäre diese Differenz 0. Mit Hilfe der Tabelle entscheiden wir noch, wie gross die Differenz hätte werden müssen, um \(H_0\) zu verwerfen. Für \(n=20\) und \(\alpha=5\%\) lautet dieser Wert \(KS_{crit}=0.294\).
Da unsere Test-Statistik diesen Wert nicht überschreitet, verwerfen wir \(H_0\) nicht, die Gewichtsdaten können hinreichend als \(N(\mu=60,\sigma=12)\) verteilt angenommen werden. Testen Sie untenstehend mit der Funktion ks.test() die Gewichtsdaten. Die Funktion verlangt im Wesentlichen zwei Argumente:
- den zu testenden Vektor, zum Beispiel
x - die kumulierte hypothetische Verteilung - im Falle der Normalverteilung heisst die Funktion in
Rzum berechnen der kumulierte Verteilungpnorm - Zusätzlich müssen noch die Argumente für die Verteilung angegeben werden, also \(\mu=60\) und \(\sigma=12\).
x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)
ks.text(x,"pnorm",60,12)Es ist übrigens nicht oft der Fall, dass bei derart wenig Datenpunkten \(H_0\) nicht verworfen werden kann. Eine weitere Aufgabe könnte sein, dass Sie die Verteilung auf Uniform-Verteilung testen. Die erste Frage, welche sich nun stellt, ist welche Parameter \(a\) und \(b\) für die Verteilung anzusetzen wären.
Um weiterhin auf \(\mu=60\) und \(\sigma=12\), nun aber auf Uniform-Verteilung zu testen, nutzen wir den Fakt, dass bei der Uniform-Verteilung der Erwartungswert \(\frac{a+b}{2}\) lautet die Streuung \(\frac{b-a}{12}\). Wir stzen also gleich:
\[\frac{a+b}{2}=60\] \[\frac{b-a}{\sqrt{12}}=12\]
Auflösen nach \(a\) und \(b\) liefert:
\[a=60-\sqrt{3}\cdot 12=39.2\]
\[b=60+\sqrt{3}\cdot 12=80.8\]
Führen Sie nun den KS-Test mit R durch.
x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)x<-c(34,44,45,47,50,50,53,56,56,58,58,62,66,67,69,76,78,80,86,94)
a<-60-sqrt(3)*12
b<-60+sqrt(3)*12
ks.test(x,"punif",a,b)Wie zu sehen fällt der \(p\)-Wert auch hier nicht unter 5%. Es kann also auch eine hypothetische Uniform-Verteilung angenommen werden.
APP für 1-Stichproben-Tests
Der 1SP-t-Test für den Mittelwert \(\mu\)
Was wird mit den aktuellen Einstellungen getestet?
Schritte 1 und 2: Hypothesen und Signifikanzniveau
Schritt 3: Berechnen der Test-Statistik
Schritt 4: Konstruktion des Annahme- und Verwerfungsbereich von \(H_0\)
Schritt 5: Test-Entscheid
Dualität zu Vertrauensintervallen
Test-Resultat mit R
Der 1SP-\(\chi^2\)-Test für die Streuung \(\sigma\)
Was wird mit den aktuellen Einstellungen getestet?
Schritte 1 und 2: Hypothesen und Signifikanzniveau
Schritt 3: Berechnen der Test-Statistik
Schritt 4: Konstruktion des Annahme- und Verwerfungsbereich von \(H_0\)
Schritt 5: Test-Entscheid
Dualität zu Vertrauensintervallen
Test-Resultat mit R
Übungs-Generator für schriftliche Aufgaben
Hier können Sie sich Lehrkräfte und Studierende schriftliche Übungen nach Zufallsprinzip generieren lassen. Die Übungen werden in ein Word-Dokument mit Lösungen geschrieben und dieses kann dann zum Zweck eigener Formatierungen noch angepasst werden. Diese Übungen beinhalten (fast) keine R-basierten Aufgaben sondern nur solche, die im Rahmen einer schriftlichen Aufgabe lösbar sind. Die Aufgabensätze werden als Word-Dokument generiert und können nach eigenen Bedürfnissen formatiert werden.