
Kombinatorik
Zur Kombinatorik wird keine eigentliche APP bereitgestellt, es wird hingegen das berühmte ‘Geburtstags-Paradoxon’ aufgezeigt. Zuerst können Sie aber im nächsten Abschnitt wieder eigene schriftliche Übungen generieren, im übernächsten Abschnitt wird dann auf das genannte Paradoxon eingegangen. Dabei lernen Sie kurz, was eine sogenannte Monte-Carlo-Simulation ist.
Übungs-Generator für schriftliche Aufgaben Kombinatorik (3) und Wahrscheinlichkeit (4)
Hier können Sie sich Lehrkräfte und Studierende schriftliche Übungen nach Zufallsprinzip generieren lassen. Die Übungen werden in ein Word-Dokument mit Lösungen geschrieben und dieses kann dann zum Zweck eigener Formatierungen noch angepasst werden. Diese Übungen beinhalten (fast) keine R-basierten Aufgaben sondern nur solche, die im Rahmen einer schriftlichen Aufgabe lösbar sind. Die Aufgabensätze werden als Word-Dokument generiert und können nach eigenen Bedürfnissen formatiert werden.
Wahrscheinlichkeits-Rechnung Euro - Millions
Unter dem untenstehenden Link können die aktuellen Gewinnzahlen von Euro-Millions eingesehen werden. Beim Euro-Millions werden aus \(N=50\) Zahlen \(n=5\) Zahlen gezogen und aus \(Z=12\) Sternen werden \(z=2\) Sterne gezogen.
Die letzte Ziehung stammt vom 23.05.2026 und entspricht dem untenstehend abgebildeten Resultat. Dabei ist die Variable Anzahl die Anzahl der Gewinner in der jeweiligen Kategorie.
Richtige | Anzahl | Gewinn | Wahrscheinlichkeit |
|---|---|---|---|
0 | |||
0 + | |||
0 ++ | |||
1 | |||
1 + | |||
1 ++ | 195050 | 11.10 | |
2 | 1214'421 | 9.05 | |
2 + | 568167 | 12.00 | |
2 ++ | 35864 | 23.95 | |
3 | 81809 | 21.80 | |
3 + | 38001 | 25.25 | |
3 ++ | 2357 | 103.80 | |
4 | 1663 | 103.35 | |
4 + | 832 | 278.10 | |
4 ++ | 49 | 2563.60 | |
5 | 5 | 33728.45 | |
5 + | 5 | 144313.50 | |
5 ++ | 0 | 0.00 |
Berechnen Sie nun (mit R) die Wahrscheinlichkeit, dass Sie bei einem Tipp in der Kategorie “1+” landen (was soviel heisst, dass Sie eine Richtige auf dem Hauptschein und einen richtigen Stern getippt haben).
nn<-50; n<-5; zz<-12; z<-2nn<-50; n<-5; zz<-12; z<-2
rn<-1; rz<-1
p1<-choose(nn-n,n-rn)*choose(n,rn)/choose(nn,n)
p2<-choose(zz-z,z-rz)*choose(z,rz)/choose(zz,z)
p1*p2Die Rechnung für Zeile 5 kann wie folgt illustriert werden: Um aus \(n=5\) ‘richtigen’ Zahlen 1 zu ziehen gibt es \({5 \choose 1}\) Möglichkeit. Um Aus \(N-n=45\) ‘falschen’ Zahlen \(4\) zu ziehen gibt es \({45 \choose 4}\) Möglichkeiten. Insgesamt gibt es \({50 \choose 50}\) Möglichkeiten, den Hauptschein auszufüllen. Somit liegt die Wahrscheinlichkeit für 1 richtige Zahl auf dem Hauptschein bei:
\[p = \frac{{45 \choose 4}\cdot {5 \choose 1}}{{50 \choose 5}}\]
Um Aus \(Z-z=10\) ‘falschen’ Zahlen \(1\) zu ziehen gibt es \({10 \choose 1}\) Möglichkeiten. Insgesamt gibt es \({12 \choose 2}\) Möglichkeiten, den Nebenschein auszufüllen. Somit liegt die Wahrscheinlichkeit für 1 richtige Zahl auf dem Nebenschein bei:
\[p = \frac{{10 \choose 1}\cdot {2 \choose 1}}{{12 \choose 2}}\]
Die finale Wahrscheinlichkeit ist somit:
\[p = \frac{{45 \choose 4}\cdot {5 \choose 1}}{{50 \choose 5}} \cdot \frac{{10 \choose 1}\cdot {2 \choose 1}}{{12 \choose 2}} = 10.655\%\]
Ergänzen Sie nun den obigen Code so, dass Sie alle Wahrscheinlichkeiten ausrechnen können. Dazu legen Sie einen Vektor rn<-c(0,0,0,1,1,1,...,5,5,5) und einen Vektor rz<-c(0,1,2,0,1,2,...,0,1,2) an, welche die Kombinationen aller möglichen richtigen Zahlen auf dem Haupt- und Nebenschein umfassen.
nn<-50; n<-5; zz<-12; z<-2nn<-50; n<-5; zz<-12; z<-2
rn<-rep(0:5,each=3)
rz<-rep(0:2,6)
rn
rz
p1<-choose(nn-n,n-rn)*choose(n,rn)/choose(nn,n)
p2<-choose(zz-z,z-rz)*choose(z,rz)/choose(zz,z)
p1*p2
sum(p1*p2)Offensichtlich haben \(0.92\) Millionen Teilnehmer Gewinne erzielt. Die Lotto-Gesellschaft weist aber offensichtlich nicht die Anzahl aller Teilnehmenden aus. Die wollen wir nun abschätzen.
Wie gross ist die Wahrscheinlichkeit, dass bei total \(T=25\) Millionen Teilnehmenden, exakt 195050 Gewinner in die Gruppe 1 ++ fallen? Berechnen Sie den Logarithmus der Wahrscheinlichkeit mittels R.
Die Wahrscheinlichkeit, dass von \(T=25\) Millionen Teilnehmenden die ersten \(k=195050\) in die Gruppe mit Wahrscheinlichkeit \(p=0.0053\) fallen und die restlichen \(T-k=24804950\) nicht, beträgt \(p^k \cdot (1-p)^{(T-k)}\). Allerdings werden ja nicht nur die ersten \(k=195050\) Teilnehmenden gewinnen können, vielmehr gibt es insgesamt \({T \choose k}\) Möglichkeiten, dass es genau so viele Gewinner in dieser Klasse gibt.
Die Wahrscheinlichkeit lautet also:
\[{T \choose k}\cdot p^k \cdot (1-p)^{(T-k)}\]
Rechnen Sie mit R diese Wahrscheinlichkeit untenstehend aus. Setzen Sie hierfür:
T<-25*10^6
k<-195050
p<-0.0053274
T<-
k<-
p<-T<-
k<-
p<-
choose(T,k)*p^k*(1-p)^(n-k)Offensichtlich ist die Wahrscheinlichkeit zu klein, als diese noch durch R numerisch angegeben werden kann. Eine Möglichkeit ist daher, logarithmierte Wahrscheinlichkeiten zu nutzen. Interessanterweise ist obige Funktion, die wir berechnen wollten, in R unter der Funktion dbinom() implementiert. Die Funktion nimmt die Argumente dbinom(x, size, prob, log=FALSE). Dabei ist:
xdie Anzahl Personen in der gesuchten Gruppe, bei unsx = k = 195050
sizedie Anzahl an Personen, bei unssize = T = 25 Millionen
probdie Wahrscheinlichkeit, in die genannte Gruppe zu fallen und
logeine Option, ob die Wahrscheinlichkeit logarithmiert ausgegeben werden soll
Rechnen Sie mit R diese logarithmierte Wahrscheinlichkeit untenstehend aus. Setzen Sie hierfür:
T<-25*10^6
k<-195050
p<-0.0053274
T<-
k<-
p<-T<-
k<-
p<-
choose(T,k)*p^k*(1-p)^(n-k)
dbinom(x=k, size=T, prob=p, log=F)
dbinom(x=k, size=T, prob=p, log=T)Das bedeutet, dass die Wahrscheinlichkeit \(e^{-12633.8}\) beträgt. Allfällige Unterschiede zur obigen Ausgabe erklären sich mit Rundungsfehlern (zum Beispiel beim Setzen von p<-...)
Benutzen Sie nun den Datensatz euro, um die logarithmierten Wahrscheinlichkeiten in der Spalte LogL für \(T=25\) Millionen Nutzer zu berechnen. Bilden Sie anschliessend die Summe über LogL.
T<-
euroT<-
#euro
euro$LogL<-dbinom(x=euro$Anzahl,size=T,prob=euro$Wahrscheinlichkeit,log=T)
euro
sum(euro$LogL,na.rm=TRUE)‘Spielen’ Sie nun etwas mit dem Code. Die Summe über LogL gibt Ihnen nun die Plausibilität des Szenarios \(T=25\) Millionen abgegebene Tips an, oder welchen Wert Sie eben auch einstellen. Umso höher der Summenwert, umso plausibler ist das Szenario. In unterem Plot sehen Sie die Summe LogL Über unterschiedliche Sznearien von Anzahl Tipps.
Das plausibelste Szenario ist anscheinend jenes mit \(29.3\) Millionen eingegangenen Tipps.
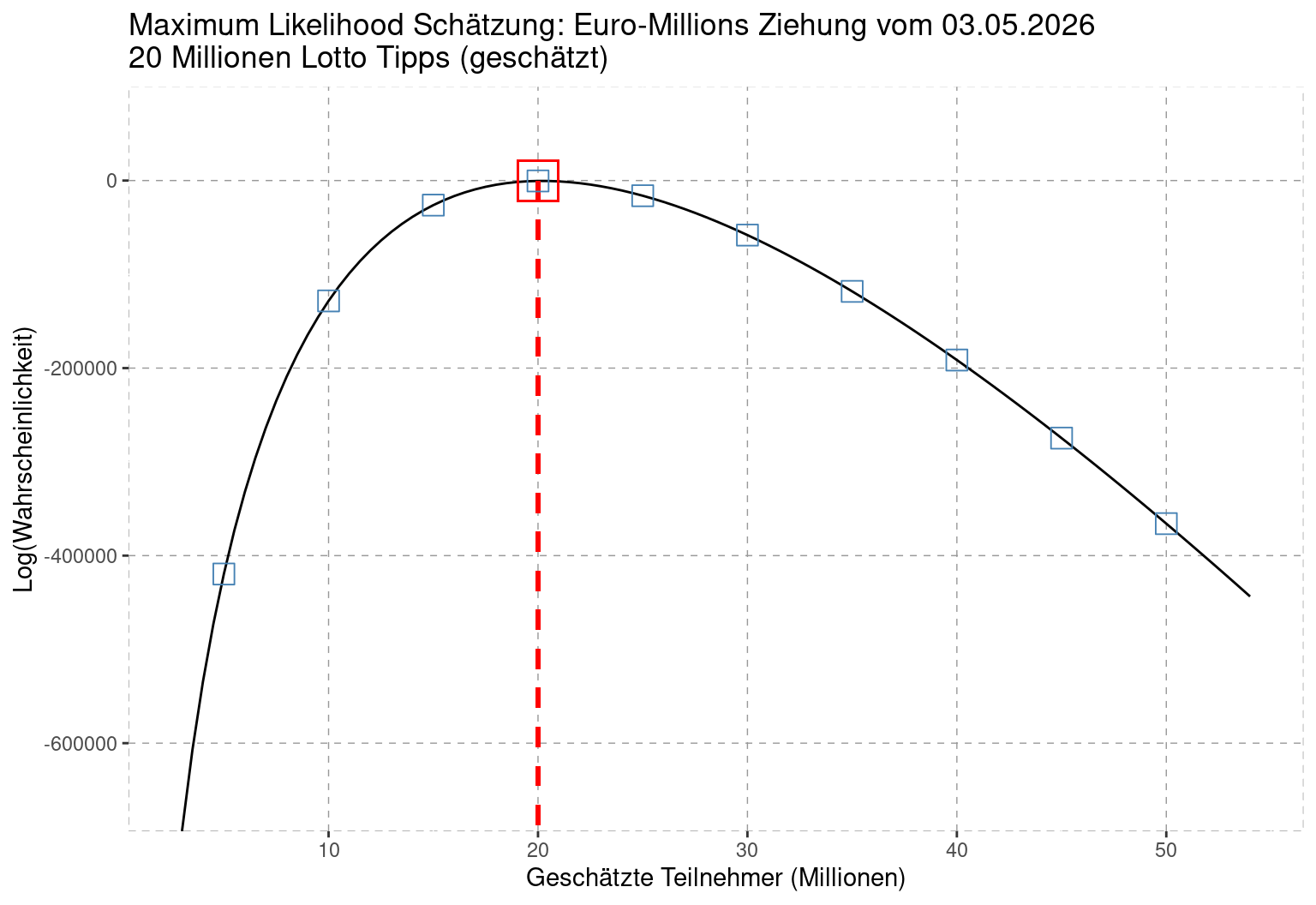
Ist dieses Resultat überraschend? Überlegen Sie sich, wie Sie diese Schätzung ohne dieses ‘komplizierte’ Vorgehen produziert hätte. Bilden Sie hierfür die Summe aller Gewinnwahrscheinlichkeiten auf dem Lottozettel euro, für welche die Anzahl Gewinner publiziert wurden.
which(!is.na(euro$Anzahl))
ps<-sum(euro$Wahrscheinlichkeit[which(!is.na(euro$Anzahl))],na.rm=TRUE)
anz<-sum(euro$Anzahl,na.rm=TRUE)
ps
anzOffensichtlich haben 2.1 Millionen Teilnehmer eine kumulierte Wahrscheinlichkeit von 0.0771 realisiert. Wenn wir diese Zahl nun auf 100% hochrechnen erhalten wir \(\frac{2.1}{0.0771} = 27.7\) Millionen Teilnehmer.
Zum Schluss produzieren wir noch die Schätzungen der Anzahl ‘Gewinner’ in den fehlenden Werten der obigen Tabelle.
Richtige | Anzahl | Wahrscheinlichkeit | Auszahlung | Umsatz |
|---|---|---|---|---|
0 | 11,511,805.2 | 0.3931627461 | 0.0 | 40,291,318.2 |
0 + | 5,116,357.9 | 0.1747389983 | 0.0 | 17,907,252.5 |
0 ++ | 255,817.9 | 0.0087369499 | 0.0 | 895,362.6 |
1 | 7,019,393.4 | 0.2397333818 | 0.0 | 24,567,877.0 |
1 + | 3,119,730.4 | 0.1065481697 | 0.0 | 10,919,056.4 |
1 ++ | 195,050.0 | 0.0053274085 | 2,165,055.0 | 682,675.0 |
2 | 1,214,421.0 | 0.0456635013 | 10,990,510.1 | 4,250,473.5 |
2 + | 568,167.0 | 0.0202948895 | 6,818,004.0 | 1,988,584.5 |
2 ++ | 35,864.0 | 0.0010147445 | 858,942.8 | 125,524.0 |
3 | 81,809.0 | 0.0031858257 | 1,783,436.2 | 286,331.5 |
3 + | 38,001.0 | 0.0014159225 | 959,525.2 | 133,003.5 |
3 ++ | 2,357.0 | 0.0000707961 | 244,656.6 | 8,249.5 |
4 | 1,663.0 | 0.0000724051 | 171,871.0 | 5,820.5 |
4 + | 832.0 | 0.0000321801 | 231,379.2 | 2,912.0 |
4 ++ | 49.0 | 0.0000016090 | 125,616.4 | 171.5 |
5 | 5.0 | 0.0000003218 | 168,642.2 | 17.5 |
5 + | 5.0 | 0.0000001430 | 721,567.5 | 17.5 |
5 ++ | 0.0 | 0.0000000072 | 0.0 | 0.0 |
Dabei wurden die Auszahlungen über die Gewinne pro Tipp-Kategorie und der Anzahl Gewinner aus der Tabelle am Seitenanfang berechnet. Der Umsatz wurde aus den geschätzten Teilnehmer-Zahlen (in rot) aus den total geschätzten Teilnahmezahlen mal der Erfolgswahrscheinlichkeit berechnet, wobei ein Tipp aktuell 3.50 EURO kostet.
Für die Lotterie-Gesellschaft gab es nun per 23.05.2026 folgendes finanzielles Ergebnis (geschätzt):
Stichtag | Teilnehmer | Auszahlungen | Umsatz | Gewinn |
|---|---|---|---|---|
23.05.2026 | 29,161,327 | 25,239,206 | 102,064,647 | 76,825,441 |
Pro abgegebenen Tipp hat die Gesellschaft am Ziehungstag 23.05.2026 einen Gewinn von 2.63 EURO erwirtschaftet.