
Diskrete Verteilungen - Uniform-Verteilung
Bei diskreten Verteilungen sind die möglichen Realisierungen der Zufallsvariable \(X\) stetig. Beispiele hierfür sind u.a. folgende Verteilungen
- Die Verteilung der Augenzahl beim Würfeln nach 60 Würfen (Uniform-Verteilung)
- Die Anzahl 6er nach 60 maligem Würfeln (Binomial-Verteilung)
- Die Anzahl Unfälle an einer Strassenkreuzung pro Jahr (Poisson-Verteilung)
- Die Anzahl richtig getippten Zahlen beim Euro-Millions (Hypergeometrische Verteilung)
Die Realisierungen einer Zufallsvariablen \(X\) werden mit \(x_i\) bezeichnet und die dazugehörige Wahrscheinlichkeit mit \(p_i\). Sind diese bekannt, so kann Erwartungswert und Streuung von \(X\) berechnet werden über:
\[E(X) = \sum p_i\cdot x_i\]
\[\sigma(X) = \sqrt{\sum p_i\cdot (x_i-E(X))^2}\]
Die Uniform-Verteilung
Bei einem fairen Würfel sind die Realisierung der Zufallsvariable \(X\): Augenzahl beim Würfeln, gleich verteilt. Das heisst, jede Zahl von 1 bis 6 hat die gleiche Wahrscheinlichkeit, zu erscheinen. Diese theoretischen Wahrscheinlichkeiten sind unten blau gefärbt aufgetragen.
Alle Verteilungen sind gewissermassen eine idealisierte Vorstellung der Realität. Zum Beispiel können Sie dem obigen Histogramm noch egene Würfelwürfe hinzufügen.
Der Erwartungswert errechnet sich für den Würfel somit zu \(\mu = 3.5\) und die Streuung zu \(\sigma = 1.7078\).
Wenn Sie sich Würfe simulieren möchten, so können Sie in untenstehendem Kasten ein Haken setzen und die Anzahl Würfe, die simuliert werden, verändern. Folgendes kann dabei beobachtet werden:
- Für kleine Anzahl simulierte Würfe \(n\) weichen die theoretischen Häufigkeiten (blau) teilweise stark von den simulierten (rot) ab. Umso höher die Fallzahl \(n\), desto geringer werden diese Abweichungen.
- Obiges gilt auch für die Genauigkeit der Verteilungsparameter. Je höher \(n\), desto eher sind Mittelwerte und Streuungen der simulierten Augenzahlen mit den theoretisch wahren identisch.
- Durch betätigen der Taste ‘Würfel neu werfen’ wird die Simulation erneuert. Im Mittel schwanken die Parameter der simulierten Verteilung um die ‘wahren’ Parameter.
Wobei für die Streuung der Stichprobe (simulierte Werte) die Standardabweichung \(s(X)\) für Stichproben genommen wird. Für grosse \(n\) sind die Unterschiede zu \(\sigma(X)\) aber klein. Man sieht, dass für grosse \(n\) die Werte mit den erwarteten Werten in der Population sehr gut übereinstimmen.
Diskrete Verteilungen - Binomial-Verteilung
Die Binomial-Verteilung errechnet die Wahrscheinlichkeit für die Anzahl Erfolge \(x\) bei \(n\)-maligem Wiederholen eines Zufallsexperimentes mit konstanter Erfolgswahrscheinlichkeit \(p\).
\[P(X=x)={n \choose x}\cdot p^x\cdot (1-p)^{n-x}\]
Übung 1
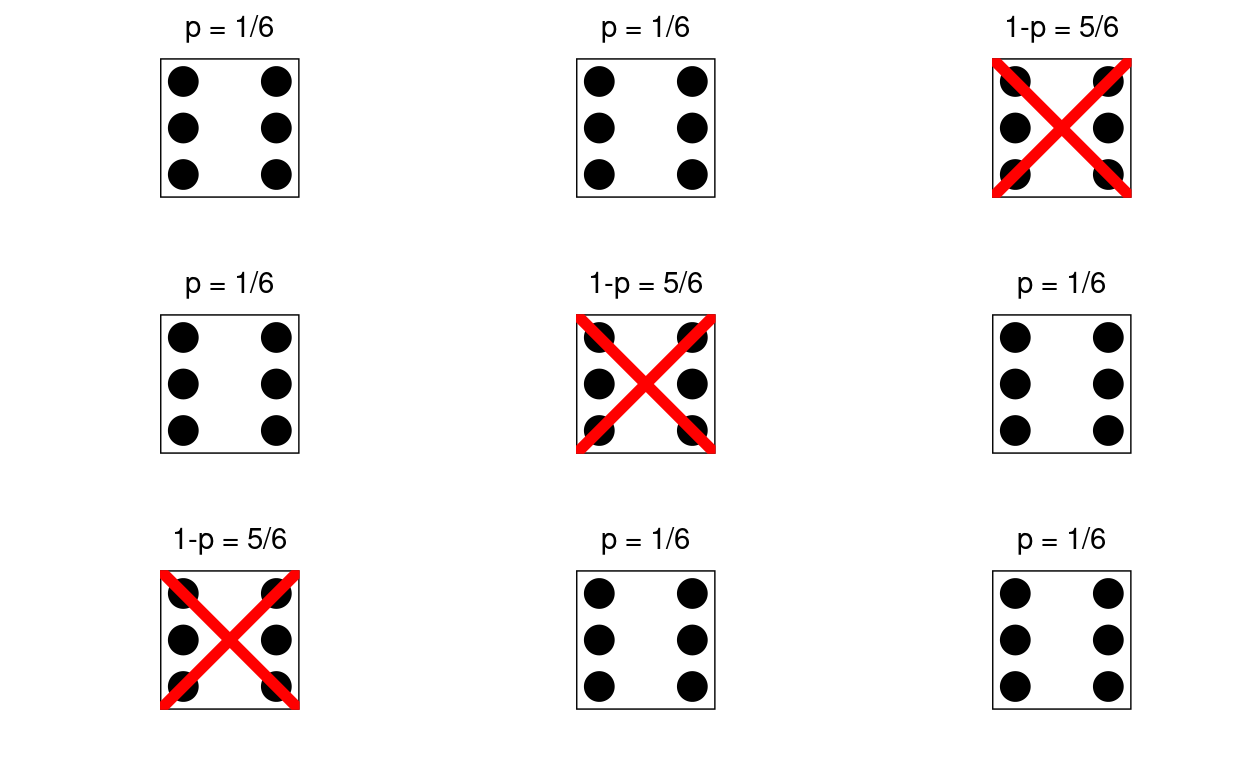
Ein Würfel wird \(n=3\) mal geworfen. Die Wahrscheinlichkeit, in einem Wurf eine ‘6’ zu sehen, ist \(p=\frac{1}{6}\). Die Wahrscheinlichkeit, in einem Wurfe keine ‘6’ zu sehen ist \(1-p=\frac{5}{6}\). Was ist nun die Wahrscheinlichkeit, genau \(x=2\) mal eine ‘6’ zu sehen?
Die Wahrscheinlichkeit, zuerst eine ‘6’ und dann eine ‘6’ und dann keine ‘6’ zu sehen ist: \(p\cdot p \cdot (1-p)=(\frac{1}{6})^2\cdot (\frac{5}{6})^{3-2}\). Damit hätten wir den Teil der Formel \(p^x\cdot(1-p)^{n-x}\) erklärt. Auf wieviele Arten man \(x=2\) ‘6’ in \(n=3\) Würfen sehen kann, sei unten dargestellt. Es gibt insgesamt \({n=3 \choose x=2}\) Möglichkeiten, dass dies passiert.
Die Wahrscheinlichkeit lautet somit:
\[P(X=2)={3 \choose 2}\cdot \left(\frac{1}{6}\right)^2 \cdot \left(\frac{5}{6}\right)^1 = 0.0694 = 6.94\%\]
Übung 2
In R berechnen wir die Wahrscheinlichkeiten von Realisierungen binomialverteilter Zufallsvariablen mit der Funktion dbinom(). Berechnen Sie nun die Wahrscheinlichkeit für oben beschriebenes Problem.
dbinom(x=2,size=3,prob=1/6)Übung 3
Berechnen Sie die Wahrscheinlichkeit, in \(n=3\) Würfen maximal \(x=3\) mal eine ‘6’ zu sehen.
dbinom(x=0,size=3,prob=1/6)+
dbinom(x=1,size=3,prob=1/6)+
dbinom(x=2,size=3,prob=1/6)+
dbinom(x=3,size=3,prob=1/6)
pbinom(q=3,size=3,prob=1/6)Maximal \(x=3\) mal eine ‘6’ zu sehen heisst entweder \(x=0\) mal oder \(x=1\) mal oder \(x=2\) mal oder \(x=3\) mal. Da hierfür alle Möglichkeiten der Ergebnisse abgedeckt werden, muss die Wahrscheinlichkeit \(1\) betragen.
Wir nennen die Notation \(P(X\leq 3)=P(X=0)+P(X=1)+P(X=2)+P(X=3)\) die kumulierte Verteilung. In R erhalten wir diese mit der Funktion pbinom().
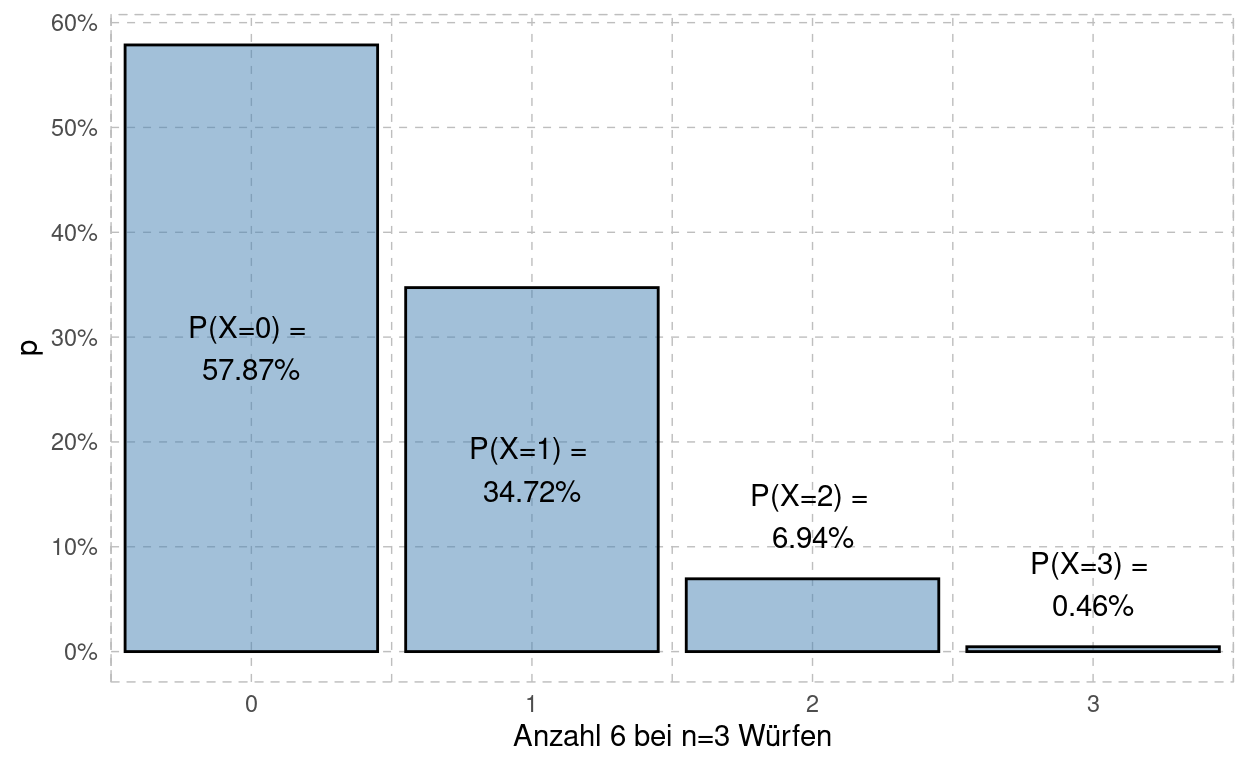
Sei \(X\) die Zufallsvariable: Anzahl ‘6’ \(x\) bei \(n=3\) Würfen. Untere Tabelle zeigt die Binomial-Verteilung von \(X\) mit der kumulierten Verteilung:
x | p | P |
|---|---|---|
0 | 0.57870370 | 0.5787037 |
1 | 0.34722222 | 0.9259259 |
2 | 0.06944444 | 0.9953704 |
3 | 0.00462963 | 1.0000000 |
Übung 4
Geben Sie die drei Quartile der Verteilung und das \(99\%\)-Quantil an.
Mit Hilfe der Tabelle würden wir suchen, bei welchem \(x\) die kumulierten Verteilungswahrscheinlichkeiten \(P\) die Quantilsgrenze, z.B. \(25\%\), das erste mal überschreiten. Somit müsste gelten \(x_{25\%}=0\), \(x_{50\%}=0\), \(x_{75\%}=1\) und \(x_{99\%}=2\).
qbinom(c(0.25,0.5,0.75,0.99),size=3,prob=1/6)Untenstehendes Histogramm zeigt Ihnen die Wahrscheinlichkeitsverteilung
Berechnen Sie nun noch die den Erwartungswert und die Streuung für die Anzahl ‘6’ bei \(n=3\) maligem Würfelwurf.
Wir erhalten: \(E(X) = \sum p_i\cdot x_i = 0.5787\cdot 1 + \dots + 0.00463\cdot 3 = 0.5\). Das Resultat überrascht nicht: Da im Mittel bei jedem sechsten Wurf eine ‘6’ zu erwarten wäre, müsste man im Mittel bei \(n=3\) Würfen \(0.5\) mal eine ‘6’ sehen.
Erwartungswert der Binomial-Verteilung \[E(X) = n\cdot p\ = 3\cdot \frac{1}{6}=0.5\]
Für die Varianz erhalten wir \(V(X)=\sum{p_i \cdot (x_i-E(X))^2} = 0.5787\cdot (1-0.5)^2+\dots + 0.00463\cdot (3-0.5)^2=0.4167\). Somit für die Streuung: \(\sigma(X)=\sqrt{0.4167}=0.645\).
Streuung der Binomial-Verteilung \[\sigma(X) = \sqrt{n\cdot p \cdot (1-p)} = \sqrt{3\cdot \frac{1}{6} \cdot \frac{5}{6}}=0.645\]
Übung 5 - APP zur Binomial-Verteilung
Benutzen Sie nun Die APP zur Binomial-Verteilung und bearbeiten hierfür das folgende Quiz. Gleichzeitig können Sie bitte versuchen, ob Sie mit untenstehendem Code-Fenster mit R die Antworten herausfinden.
dbinom(x=2,size=4,prob=0.5)
qbinom(0.25,size=4,prob=0.5)Diskrete Verteilungen - Poisson-Verteilung
Die Poisson-Verteilung berechnet die Wahrscheinlichkeit, dass in einem fixen Zeitintervall \(T\) genau \(x\) Ereignisse eintreten wenn bekannt ist, dass die mittlere Anzahl der auftretenden Ereignisse im Zeitintervall \(T\) gleich \(\lambda\) beträgt.
\[P(X=x)=\frac{\lambda^x}{x!}\cdot e^{-\lambda}\]
Übung 6
In einem Supermarkt kommt im Schnitt jede Minute ein Kunde zur Kasse. Da das Zeitintervall (1min) vorgegeben und der Erfahrungswert \(\lambda = 1\) bekannt ist, liegt eine Poisson-Verteilung vor.
Berechnen Sie die Wahrscheinlichkeit, dass in einer Minute kein Kunde zur Kasse kommt.
dpois(x=0,lambda=1)Die R-Funktion dpois() wertet also die obige Formel zur Poisson-Verteilung aus. Durch Einsetzen erhält man:
\[P(X=0)=\frac{1^0}{0!}\cdot e^{-1}=0.36787=36.8\%\]
Übung 7
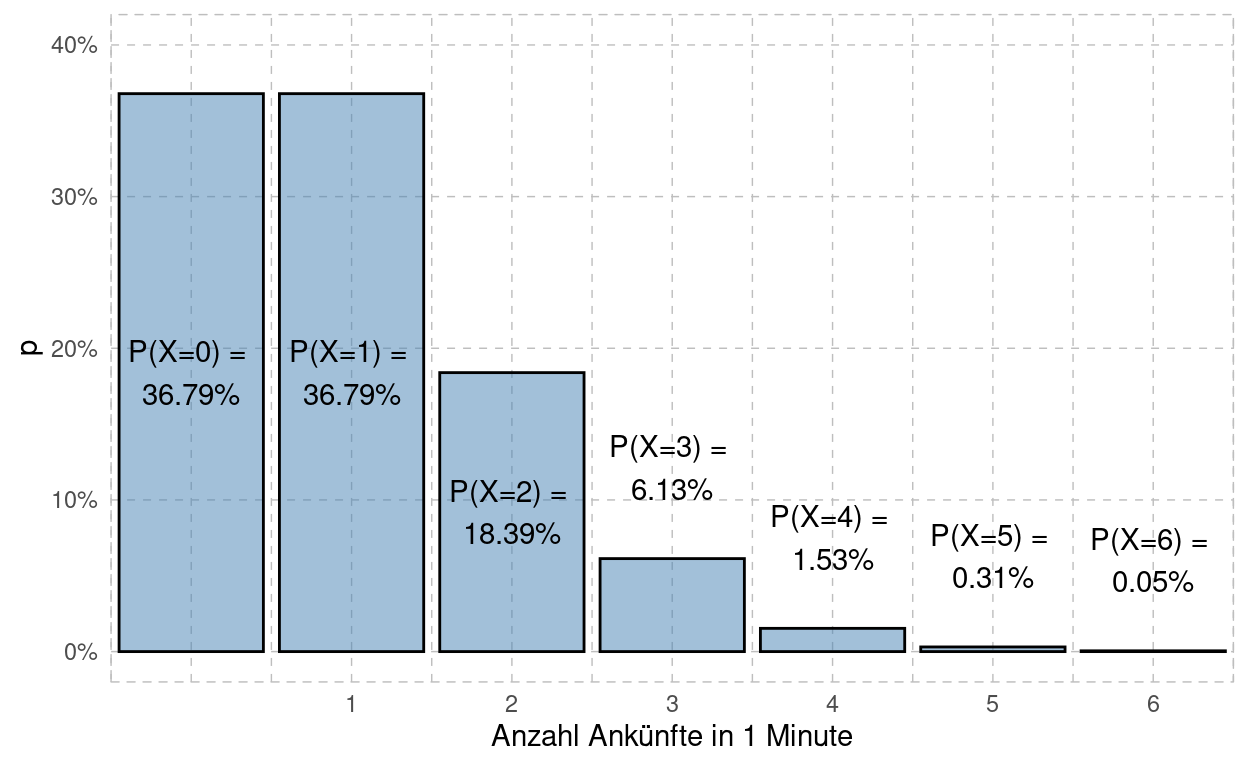
Berechnen Sie nun die Wahrscheinlichkeiten \(p\) und die kumulierten Wahrscheinlichkeiten \(P\), dass \(x=0, 1, 2, 3, \dots, 6\) Kunden an die Kasse kommen. Wieviele Kunden können (theoretisch) maximal ankommen?
df<-data.frame(x=0:6, p=dpois(x=0:6,lambda=1), P=ppois(q=0:6,lambda=1))
kable(df)x | p | P |
|---|---|---|
0 | 0.3678794412 | 0.3678794 |
1 | 0.3678794412 | 0.7357589 |
2 | 0.1839397206 | 0.9196986 |
3 | 0.0613132402 | 0.9810118 |
4 | 0.0153283100 | 0.9963402 |
5 | 0.0030656620 | 0.9994058 |
6 | 0.0005109437 | 0.9999168 |
Wir merken uns: Für die Wahrscheinlichkeiten \(P(X=x)\) bei der Poisson-Verteilung nehmen wir die R-Funktion dpois(), für die kumulierten Wahrscheinlichkeiten ppois() und für die Quantile qpois(). Theoretisch müssten wir die Tabelle bis \(x=\infty\) darstellen. Da im Mittel aber nur \(\lambda=1\) Kunden ankommen, sind pro Minute mehr als 6 Kunden, wie wir sehen, sehr unwahrscheinlich.
Übung 8
Berechnen Sie mit Hilfe der obigen Tabelle den Erwartungswert \(E(X)\) und die Standardabweichung \(\sigma(X)\) der pro Minute ankommenden Anzahl Leute.
df<-data.frame(x=0:6, p=dpois(x=0:6,lambda=1), P=ppois(q=0:6,lambda=1))
erwpois<-sum(df$x*df$p)
sigmapois<-sqrt(sum(df$p*(df$x-erwpois)^2))df<-data.frame(x=0:6, p=dpois(x=0:6,lambda=1), P=ppois(q=0:6,lambda=1))
ex<-sum(df$x*df$p)
sigma<-sqrt(sum(df$p*(df$x-ex)^2))
print(ex)
print(sigma)Wie sie sehen, wertet obiger Code die Formeln \(E(X)=\sum p_i\cdot x_i\) und \(\sigma(X)=\sqrt{\sum p_i\cdot \dots}\) aus. Wir erhalten \(E(X)=0.9994\) und \(\sigma(X)=0.9984\)
Ähnlich wie bei der Binomialverteilung kann man sich diese Rechnung aber abkürzen. Wir haben ja schon angegeben, was der Mittelwert \(E(X)\) oder \(\mu\) der ankommenden Kunden ist, nämlich
\[E(X)=\lambda=1\]
für die Streuung gilt:
\[\sigma(X)=\sqrt{\lambda}=1\]
Untenstehendes Diagramm zeigt Ihnen das Histogramm der Poisson-Verteilung zu \(\lambda=1\).
Beantworten Sie nun noch mit der Tabelle oder mit Hilfe einer R-Konsole (unten) folgende Quiz-Fragen:
qpois(0.5,lambda=1)Übung 10 - APP zur Poisson-Verteilung (Neu berechnen drücken)
Benutzen Sie nun Die APP zur Poisson-Verteilung und bearbeiten hierfür das folgende Quiz. Gleichzeitig können Sie bitte versuchen, ob Sie mit untenstehendem Code-Fenster mit R die Antworten herausfinden. Denken Sie daran, nach dem neuen Setzen der Parameter wie \(\lambda\) den Knopf Neu berechnen zu drücken.
Übung 11 - Limousinen-Vermietung
Ein Familienunternehmen vermietet Limousinen an Kunden. Bei erfolgreicher Vermietung ergeben sich Tagesumsätze von \(100\) Euro pro Limousine. Die Wartungskosten der Fahrzeuge betragen in jedem Fall \(30\) Euro pro Tag. Das Unternehmen schätzt aus den vergangenen Jahren, dass im Mittel \(\lambda = 1.5\) Kunden pro Tag ein Fahrzeug gemietet haben. Das Unternehmen will von Ihnen wissen, ob es sich für diese Ausgangslage eine dritte Limousine anschaffen oder bei nur zwei verbleiben sollte.
Ausgangslage
Erstellen Sie einen Datensatz df mit den Variablen kunden=c(0,1,2,3) und der Wahrscheinlichkeit p= ..., wobei für den Eintrag \(3\) bei Kunden die Wahrscheinlichkeit 3 oder mehr Kunden stehen sollte.
lambda<-1.5
df<-data.frame(kunden=c(0,1,2,3),
p=dpois(x=c(0,1,2,3),lambda=lambda))
df$p[df$kunden==3]<-1-ppois(2,lambda=lambda)
print(df)
sum(df$p)Wir haben nun einen Datensatz mit Anzahl Kunden (0, 1, 2, 3 oder mehr) und die dazugehörigen Wahrscheinlichkeiten. Erstellen Sie nun eine Variable umsatz_2 im dataframe df die den Umsatz berechnet, wenn die Firma \(2\) Limousinen besitzt. Wiederholen Sie das Prozedere für 3 Limousinen. Hinweis: Benutzen Sie die Funktion ifelse. Lassen Sie untenstehenden Code stehen (kopiert aus vorherigem Teil) und machen Sie in den Folgezeilen weiter.
Umsätze berechnen
lambda<-1.5
einkommen<-100
kosten<-30
df<-data.frame(kunden=c(0,1,2,3),
p=dpois(x=c(0,1,2,3),lambda=lambda))
df$p[df$kunden==3]<-1-ppois(2,lambda=lambda)
print(df)
sum(df$p)lambda<-1.5
einkommen<-100
kosten<-30
df<-data.frame(kunden=c(0,1,2,3),
p=dpois(x=c(0,1,2,3),lambda=lambda))
df$p[df$kunden==3]<-1-ppois(2,lambda=lambda)
print(df)
sum(df$p)
df$umsatz_2<-ifelse(df$kunden<=2,df$kunden*einkommen-2*kosten,2*(einkommen-kosten))
df$umsatz_3<-ifelse(df$kunden<=3,df$kunden*einkommen-3*kosten,3*(einkommen-kosten))
print(df)Beste Option wählen
Benutzen Sie nun untenstehenden R-Code, um das Quiz zu beantworten.
lambda<-1.5
einkommen<-100
kosten<-30
df<-data.frame(kunden=c(0,1,2,3),
p=dpois(x=c(0,1,2,3),lambda=lambda))
df$p[df$kunden==3]<-1-ppois(2,lambda=lambda)
print(df)
sum(df$p)
df$umsatz_2<-ifelse(df$kunden<=2,df$kunden*einkommen-2*kosten,2*(einkommen-kosten))
df$umsatz_3<-ifelse(df$kunden<=3,df$kunden*einkommen-3*kosten,3*(einkommen-kosten))
print(df)APP zu allen Verteilungen
Binomial-Verteilung
Poisson-Verteilung
Übungs-Generator für schriftliche Aufgaben
Hier können Sie sich Lehrkräfte und Studierende schriftliche Übungen nach Zufallsprinzip generieren lassen. Die Übungen werden in ein Word-Dokument mit Lösungen geschrieben und dieses kann dann zum Zweck eigener Formatierungen noch angepasst werden. Diese Übungen beinhalten (fast) keine R-basierten Aufgaben sondern nur solche, die im Rahmen einer schriftlichen Aufgabe lösbar sind. Die Aufgabensätze werden als Word-Dokument generiert und können nach eigenen Bedürfnissen formatiert werden.