
Einführung
In diesem Tutorial lernen wir wichtige theoretische und praktische Aspekte des Machine Learnings kennen. Das Hauptziel hier ist es, eine klassische ML-Pipeline ganz durchzuarbeiten und alle wichtigen theoretischen und praktischen Konzepte kennen zu lernen. Mit Pipeline meinen wir hier die Sequenz von Schritten, die mithilfe einer Programmiersprache (hier R) durchzuführen sind, damit wir ein sinnvolles ML-Modell erhalten. Gleichzeitig wollen wir uns hier das lineare Regressionsmodell aus einer Machine Learning Perspektive anschauen.
Wenn ich hier von einer klassischen ML-Pipeline spreche, dann meine ich ML-Projekte, bei denen es nicht um die Anwendung von grossen Sprachmodellen oder anderen modernen AI-Modellen geht. Solche klassischen Projekte sind aber immer noch weit verbreitet, vor allem in KMU, aber auch in grösseren Unternehmen. Es lohnt sich also nach wie vor diese Skills zu erlernen.
Weiterführende Ressourcen:
- Kapitel 2 und 4 in Géron (2022)
- Kapitel 2, 3 und 6 in James, Witten, Hastie und Tibshirani (2021)
- Kaggle Beispiel
- Get Started with tidymodels
- Dokumentation zum glmnet Package
1. Setup des Projekts
Bevor Sie überhaupt beginnen, mit R zu arbeiten, müssen Sie das Problem, das Sie lösen sollen, wirklich verstehen (“Big Picture”). Sprechen Sie dazu mit Fachexpertinnen und -experten (sog. Domain Experts). Sie sollten unter anderem folgende Fragen klären:
- Was sind die Business Ziele? Was ist das Problem?
- Gab es eine bisherige Lösung? Wenn ja, was war deren Performance?
- Was wäre der Vorteil einer ML-Lösung?
- Welche Daten sind verfügbar?
- Gibt es Metadaten (Dokumentation der Daten, Code Books, etc.)?
Wir werden die Schritte der ML-Pipeline anhand eines Beispiels erlernen. Beim Beispiel handelt es sich um eine Kaggle Challenge. Es geht darum, historische Daten von Taxi Trips in New York City zu verwenden, um die Dauer eines Taxi Trips in dieser Stadt vorherzusagen. Das Beispiel beruht zu einem grossen Teil auf folgendem (fantastischem!) Notebook. Herzlichen Dank an dieser Stellen an den/die Autor*in Heads or Tails.
Stellen Sie sich vor, Sie arbeiten bei einem Startup, das eine App anbietet, welche es Kundinnen und Kunden erlaubt Taxi Trips zu buchen. Die/der Chief Technology Officer (CTO) wendet sich an Sie und wünscht sich ein neues App Feature, nämlich eine Vorhersage der Trip Dauer. Sie besprechen das Problem und erfahren, dass im App bisher nur eine ganz grobe Abschätzung der Trip Dauer basierend auf der Distanz angegeben wird. Die/der CTO möchte ein genaueres Vorhersagemodell. Die Hoffnung ist, dass dieses Feature zu einer Erhöhung der Kundenzufriedenheit führt. Es steht Ihnen ein Datensatz aus dem ersten Halbjahr 2016 mit über einer Million Taxi Trips zur Verfügung. Weiter empfiehlt die/der CTO Ihnen, Wetterdaten in das Modell zu intergrieren.
Nun ist es an Ihnen, das ML-Problem genau zu definieren:
- Der Datensatz, der Ihnen zur Verfügung steht, enthält für jeden Trip die Dauer des Trips (die Output Variable). Es handelt sich hier also um ein Supervised Learning Problem.
- Die Trip Dauer ist ein numerischer Wert, den Sie vorhersagen sollen. Es handelt sich hierbei also um ein Regressionsproblem.
- Im Falle eines Klassifikationsproblems müssten Sie nun auch noch überprüfen, ob es sich um ein balanced oder imbalanced Problem handelt. Wenn Sie beispielsweise vorhersagen sollen, ob es sich um eine betrügerische Kreditkartentransaktion handelt oder nicht, haben Sie typischerweise viel mehr Beobachtungen zu nicht-betrügerischen Transaktionen und nur wenige betrügerische Transaktionen. Ein typischer Fall eines imbalanced Problems.
- Die/der CTO hat ausserdem Metadaten für Sie, nämlich die Erläuterungen zu den einzelnen Spalten im Datensatz:
id: Eindeutige ID eines Trips.vendor_id: Code des Taxi-Anbieters (1oder2).pickup_datetime: Datum und Zeit, wann der Taximeter zu laufen beginnt.dropoff_datetime: Datum und Zeit, wann der Taximeter stoppt.passenger_count: Anzahl Passagiere im Taxi.pickup_longitude: Längengrad am Ausgangspunkt des Trips.pickup_latitude: Breitengrad am Ausgangspunkt des Trips.dropoff_longitude: Längengrad am Endpunkt des Trips.dropoff_latitude: Breitengrad am Endpunkt des Trips.store_and_fwd_flag: Konnten die Tripdaten während der Reise an den Server geschickt werden oder nicht? (YoderN)trip_duration: Dauer des Trips.
Hier nun noch ein paar technische Vorbereitungen:
- Erstellen Sie in Ihrem File System einen Ordner, in dem wir das ML-Projekt durchführen werden. Erstellen Sie zwei Unterordner mit den Namen
datenundzwischenresultate. - Laden Sie die Daten von Moodle runter und speichern Sie die Daten im Unterordner
daten. - Öffnen Sie nun RStudio und erstellen Sie ein neues R-Projekt. Erstellen Sie das Projekt im vorher erstellten Ordner.
- Installieren Sie folgende R Packages (ich nehme an, dass Sie
tidyversebereits installiert haben):
# Installation der R Packages
install.packages(c("tidymodels", "glmnet", "leaflet", "geosphere", "corrplot", "vetiver"))2. Import und Preprocess
In einem ersten Schritt legen wir ein Skript an, um die Daten zu importieren und ein erstes Preprocessing vorzunehmen. Dieser Schritt ist nicht zu unterschätzen, da er oft viel Zeit in Anspruch nimmt. Es ist nicht untypisch, dass bis zu 80% des Zeitaufwands eines ML-Projekts auf das Preprocessing und Data Cleaning entfällt.
Wir beginnen damit die benötigten R Packages zu laden und eine kleine Funktion zu definieren, die Temperaturen von Fahrenheit in Celsius umrechnet:
# *****************************************************
# 1. Vorarbeiten --------------------------------------
# Workspace aufräumen
rm(list = ls())
# Lade Software aus R Packages
library(tidyverse)
library(tidymodels)
# Funktion, um Temp. in Fahrenheit in Celsius umzurechnen
fahrenheit_to_celsius <- function(fahr) {round((fahr - 32) * 5/9, 2)}Datenimport
Nun importieren wir die Daten mit read_csv() aus dem tidyverse und verschaffen uns einen ersten Überblick über die Spalten mit der Funktion glimpse(). Wir sehen, dass der Dataframe trips 1’458’644 Zeilen und 11 Spalten hat. Der Dataframe weather hat 366 Zeilen (das Jahr 2016 war ein Schaltjahr) und 7 Spalten. Dabei können wir gleich schon überprüfen, ob die Spalten den richtigen Datentyp haben.
# *****************************************************
# 2. Datenimport --------------------------------------
# Importiere CSV Datensätze
trips <- read_csv("daten/trips.csv")
weather <- read_csv("daten/weather.csv")
# Was für Spalten bzw. Datentypen haben wir in den Daten?
glimpse(trips)
glimpse(weather)Rows: 1,458,644
Columns: 11
$ id <chr> "id2875421", "id2377394", "id3858529", "id3504673", "id2181028", "id0801584"…
$ vendor_id <dbl> 2, 1, 2, 2, 2, 2, 1, 2, 1, 2, 2, 2, 2, 2, 2, 1, 2, 1, 1, 2, 1, 2, 1, 1, 2, 2…
$ pickup_datetime <dttm> 2016-03-14 17:24:55, 2016-06-12 00:43:35, 2016-01-19 11:35:24, 2016-04-06 1…
$ dropoff_datetime <dttm> 2016-03-14 17:32:30, 2016-06-12 00:54:38, 2016-01-19 12:10:48, 2016-04-06 1…
$ passenger_count <dbl> 1, 1, 1, 1, 1, 6, 4, 1, 1, 1, 1, 4, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ pickup_longitude <dbl> -73.98215, -73.98042, -73.97903, -74.01004, -73.97305, -73.98286, -73.96902,…
$ pickup_latitude <dbl> 40.76794, 40.73856, 40.76394, 40.71997, 40.79321, 40.74220, 40.75784, 40.797…
$ dropoff_longitude <dbl> -73.96463, -73.99948, -74.00533, -74.01227, -73.97292, -73.99208, -73.95741,…
$ dropoff_latitude <dbl> 40.76560, 40.73115, 40.71009, 40.70672, 40.78252, 40.74918, 40.76590, 40.760…
$ store_and_fwd_flag <chr> "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "…
$ trip_duration <dbl> 455, 663, 2124, 429, 435, 443, 341, 1551, 255, 1225, 1274, 1128, 1114, 260, …Rows: 366
Columns: 7
$ date <chr> "01-01-16", "02-01-16", "03-01-16", "04-01-16", "05-01-16", "06-01-16", "…
$ `maximum temerature` <dbl> 44, 40, 46, 35, 29, 41, 43, 46, 47, 60, 42, 44, 31, 36, 46, 52, 43, 30, 3…
$ `minimum temperature` <dbl> 34, 30, 33, 13, 10, 16, 20, 29, 37, 42, 26, 22, 24, 22, 30, 39, 28, 20, 1…
$ `average temperature` <dbl> 39.0, 35.0, 39.5, 24.0, 19.5, 28.5, 31.5, 37.5, 42.0, 51.0, 34.0, 33.0, 2…
$ precipitation <chr> "0", "0", "0", "0", "0", "0", "0", "0", "0", "1.23", "0", "0.01", "0", "T…
$ `snow fall` <chr> "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "T", "0", "0.1", "…
$ `snow depth` <chr> "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0"…Im Dataframe weather sehen wir gleich schon ein Problem: die letzten drei Variablen enthalten teilweise den Wert "T" (Trace), wodurch die ganze Spalte als Textspalte interpretiert wird. Das ist unschön, da es sich hier klar um numerische Information handelt (Niederschlagsmengen).
Als nächstes verwenden wir sapply(), um für jede Spalte zu zählen, wie viele fehlende Werte (Missing Values) es gibt. Wir haben Glück und es gibt in diesen beiden Dataframes keine fehlenden Werte.
# Zählen von fehlenden Werten pro Spalte
sapply(trips, function(x) sum(is.na(x)))
sapply(weather, function(x) sum(is.na(x))) id vendor_id pickup_datetime dropoff_datetime passenger_count
0 0 0 0 0
pickup_longitude pickup_latitude dropoff_longitude dropoff_latitude store_and_fwd_flag
0 0 0 0 0
trip_duration
0
date maximum temerature minimum temperature average temperature precipitation
0 0 0 0 0
snow fall snow depth
0 0 Fehlende Werte sind aber ein typisches Problem im Preprocessing. Es gibt drei Möglichkeiten mit dem Problem umzugehen:
- Entfernung aller Zeilen, welche fehlende Werte enthalten. Nur eine valable Option, wenn für eine Zeile viele Variablen (oder Zellen) fehlen. Wir wollen ja schliesslich nicht zu viele Beobachtungen verlieren.
- Entfernung einer Spalte, welche fehlende Werte enthält. Auch hier: nur eine valable Option, wenn in einer Spalte ganz viele Werte fehlen.
- Imputation von fehlenden Werten. Einfache Imputationsmethoden imputieren den Mittelwert oder Median für numerische Spalten oder den häufigsten Wert (Modus) für kategorische Spalten. Es gibt aber viel komplexere (bessere!) Imputationsverfahren.
Danach verschaffen wir uns noch kurz einen Überblick über einige der numerischen und kategorischen Spalten.
# Eindeutige qualitative Werte in 'trips'
sapply(trips %>% select(vendor_id, store_and_fwd_flag), unique)
# Quantitative Variablen in 'trips'
summary(trips %>% select(passenger_count, trip_duration)) vendor_id store_and_fwd_flag
[1,] "2" "N"
[2,] "1" "Y"
passenger_count trip_duration
Min. :0.000 Min. : 1
1st Qu.:1.000 1st Qu.: 397
Median :1.000 Median : 662
Mean :1.665 Mean : 959
3rd Qu.:2.000 3rd Qu.: 1075
Max. :9.000 Max. :3526282 Datenimport aus relationalen Datenbanken
In der Praxis kann es vorkommen, dass Sie die Daten direkt aus einer relationalen Datenbank bzw. einem Data Warehouse importieren, anstatt dass die Daten im CSV Format vorliegen. Das folgende Tutorial der Firma Posit (vormals RStudio) zeigt Ihnen, wie Sie direkt aus R Datenbankabfragen machen können: Tutorial.
Für die Abfrage von relationalen Datenbanken wird die sogenannte Structured Query Language (SQL) verwendet. SQL ist eine relativ einfach erlernbare Abfragesprache (Tutorial).
Ein simples Beispiel sieht folgendermassen aus:
SELECT id, address, balance
FROM Customers
WHERE age > 50;Mit dieser Abfrage erhalten wir eine Tabelle mit den Spalten id, address und balance aus einer Datenbanktabelle mit dem Name Customers und zwar nur für die Kunden, welche älter als 50 sind.
Preprocessing
In einem ersten Preprocessing Schritt bearbeiten wir nun die Daten im Dataframe weather. Wir führen unter anderem folgende Operationen durch:
- Wir transformieren die Textwerte in der Spalte
datein Datumswerte mit der Funktiondmy()aus demlubridatePackage. - Wir transformieren die Temperaturen von der Einheit Fahrenheit in die Einheit Celsius.
- Wir ersetzen den Wert
T(Trace) in den Spalten zu Niederschlag und Schnee mit0.01und definieren die entsprechenden Spalten anschliessend als numerische Spalten.
# *****************************************************
# 3. Preprocessing ------------------------------------
# Spaltennamen
colnames(weather) <- c("date", "max_temp", "min_temp",
"avg_temp", "precipitation",
"snowfall", "snowdepth")
# Datentypen weather
summary(weather) date max_temp min_temp avg_temp precipitation
Length:366 Min. :14.00 Min. :-6.00 Min. : 4.00 Length:366
Class :character 1st Qu.:49.25 1st Qu.:36.00 1st Qu.:42.50 Class :character
Mode :character Median :63.00 Median :47.00 Median :54.25 Mode :character
Mean :63.39 Mean :48.28 Mean :55.83
3rd Qu.:80.00 3rd Qu.:64.00 3rd Qu.:72.00
Max. :96.00 Max. :81.00 Max. :88.50
snowfall snowdepth
Length:366 Length:366
Class :character Class :character
Mode :character Mode :character# Datumswerte
weather$date <- lubridate::dmy(weather$date)
# Temperaturen: Fahrenheit -> Celsius
weather[ ,c("max_temp","min_temp","avg_temp")] <- sapply(
weather[ ,c("max_temp","min_temp","avg_temp")],
fahrenheit_to_celsius
)
# Plot Temperatur
weather %>%
ggplot(aes(x = date, y = avg_temp)) +
geom_line() +
theme_bw() +
labs(x = NULL, y = "Durchschnittstemperatur")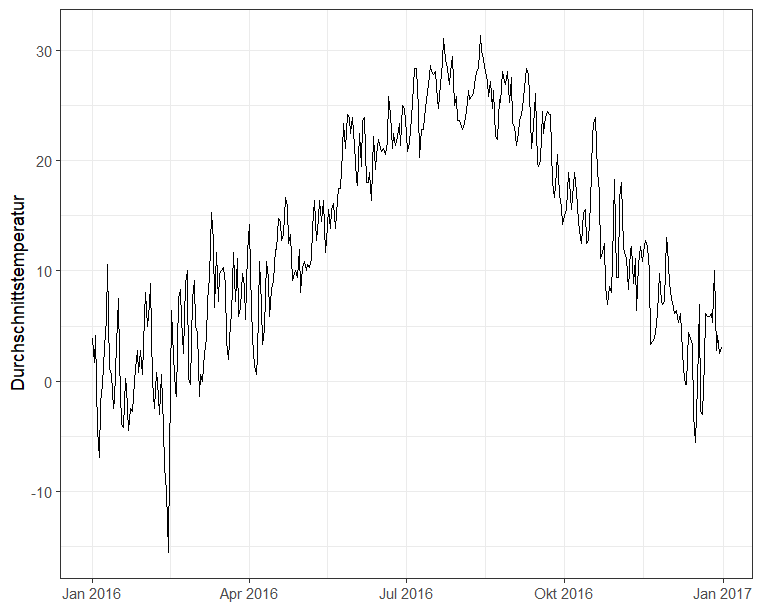
# Die Variablen 'precipitation', 'snowfall' und 'snowdepth'
# enthalten den Wert "T", der für "Trace" steht. Darum werden
# die drei Variablen als 'character' Daten importiert. Trace
# bedeutet, dass es nur ganz wenig Regen bzw. Schnee gegeben
# hat. Wir ersetzen "T" mit 0.01 und transformieren die Spalten
# in numerische Spalten.
weather <- weather %>%
mutate(
precipitation = as.numeric(ifelse(precipitation == "T", 0.01, precipitation)),
snowfall = as.numeric(ifelse(snowfall == "T", 0.01, snowfall)),
snowdepth = as.numeric(ifelse(snowdepth == "T", 0.01, snowdepth))
)In einem zweiten Preprocessing Schritt überprüfen wir, ob die Dataframes Duplikate enthalten. Wir sehen, dass der trips Dataframe 7 Duplikate enthält, während der weather Dataframe keine Duplikate aufweist. Wichtig: wir finden die Duplikate nur, indem wir die Variable id in der Funktion duplicated() ignorieren.
# Duplikate?
dpl_trips_idx <- duplicated(trips %>% select(-id))
dpl_weather_idx <- duplicated(weather)
sum(dpl_trips_idx)
sum(dpl_weather_idx)[1] 7
[1] 0Wir geben uns die Duplikate kurz in einem separaten Dataframe temp aus, um sie anzuschauen. Da es tatsächlich nach richtigen Duplikaten aussieht, entfernen wir sie aus trips.
# Wir wollen uns die Duplikate kurz anschauen:
temp <- trips %>%
group_by(vendor_id, pickup_datetime, dropoff_datetime, pickup_longitude) %>%
filter(n() > 1)
# Entferne 'temp' wieder aus Workspace
rm(temp)
# Duplikate entfernen
trips <- trips[!dpl_trips_idx, ]Am Schluss machen wir noch zwei kleine Konsistenzchecks:
# Konsistenzcheck 'duration'
# (Dropoff Zeit - Pickup Zeit) sollte der Spalte 'trip_duration' entsprechen.
all((trips$dropoff_datetime - trips$pickup_datetime) == trips$trip_duration)
# Wie viele Trips starten vor Mitternacht und enden danach?
sum(lubridate::as_date(trips$pickup_datetime) != lubridate::as_date(trips$dropoff_datetime))[1] TRUE
[1] 16510Die Resultate geben keinen Anlass, etwas zu unternehmen.
Nun wollen wir die Daten aus dem Dataframe weather dem Dataframe trips hinzufügen (via left_join()). Dazu verwenden wir eine tidyverse Pipeline, mit der Sie sicher bereits vertraut sind:
# *****************************************************
# 4. Join ---------------------------------------------
# Wir verwenden eine tidyverse Pipeline, um die beiden
# Dataframes zusammenzuführen. Wir matchen mit der
# Variable 'pickup_datetime'.
trips <- trips %>%
mutate(date = lubridate::as_date(pickup_datetime)) %>%
left_join(weather, by = "date") %>%
select(-date)Wir beenden diesen ersten Import / Preprocessing Schritt, indem wir die Zwischenresultate im entsprechenden Unterordner abspeichern. Ziel ist es, das Projekt modular aufzubauen, so dass wir nicht jedes Mal alles in R laufen lassen müssen.
# *****************************************************
# 5. Zwischenresultate speichern ----------------------
# Wir speichern trips in dem Ordner 'Zwischenresultate'
write_rds(trips, "zwischenresultate/trips.rds")Hier können Sie nun das vollständige R-Skript in Ihr lokales Projekt übernehmen:
3. Train-Test Split und Exploration
Im zweiten Skript erstellen wir den Train-Test Split und führen danach eine explorative Analyse der Trainingsdaten durch.
Wir beginnen damit, die benötigten R Packages zu laden. Ausserdem laden wir den Dataframe trips aus dem Ordner zwischenresultate:
# *****************************************************
# 1. Vorarbeiten --------------------------------------
# Workspace aufräumen
rm(list = ls())
# Lade Software aus R Packages
library(tidyverse)
library(tidymodels)
library(leaflet)
# Lade Zwischenresultate
trips <- read_rds("zwischenresultate/trips.rds")Train-Test Split
Warum machen wir einen Train-Test Split?
In einem ML-Problem legen wir uns in der Anfangsphase des Projekts einen Teil der Daten zur Seite (Testdaten). Wir werden die beiseite gelegten Daten ganz am Schluss verwenden, um die Performance unseres finalen Modells zu messen. Es ist ganz wichtig, dass wir diese Daten vor der finalen Performance-Messung nicht “anfassen”, auch nicht für explorative Analysen. Warum nicht? Die Performance auf den Testdaten soll uns als “unvoreingenommene” Schätzung des Fehlers dienen, der unser Modell in einem produktiven System machen wird. Wenn wir Einsichten aus dem Testdatensatz in unser Modell einfliessen lassen (Data Snooping), dann wird der Fehler auf dem Testset den tatsächlichen Fehler unterschätzen.
Die restlichen Daten (Trainingsdaten) verwenden wir, um verschiedene Modelle zu trainieren, um die Daten explorativ zu erforschen und um bessere Features zu entwickeln. Wir werden später sehen, dass wir den Trainingsdatensatz weiter aufspalten, um das Hyperparameter Tuning durchzuführen.
Wir führen nun also einen zufälligen Train-Test Split durch. Wichtig ist, dass wir vorher einen Seed setzen, so dass wir denselben zufälligen Split immer wieder reproduzieren können. Für den Split verwenden wir die Funktion initial_split() aus tidymodels. Mit dem Argument prop = 3/4 bestimmen wir, dass der Trainingsdatensatz 75% der Daten enthalten soll, während die restlichen 25% der Daten in den Testdatensatz fliessen. Der effektive Split wird dann mit den Funktionen training() und testing() vollzogen.
# *****************************************************
# 2. Train-Test Split ---------------------------------
# Seed, um den Train-Test Split reproduzierbar zu machen
set.seed(123)
# Split (75% Training, 25% Test)
train_test_split <- initial_split(trips, prop = 3/4)
train <- training(train_test_split)
test <- testing(train_test_split)
nrow(train) / nrow(trips)[1] 0.7499995Für den Fall eines Klassifikationsproblems enthält die Funktion initial_split() ein weiteres Argument strata, das uns erlaubt einen stratifizierten Split zu machen (mehr dazu später).
Explorative Analyse
Nun können wir die Trainingsdaten (die Testdaten fassen wir nicht an!) explorativ analysieren, was vor allem bedeutet, dass wir die Daten visualisieren. Sie haben das wichtigste Tool dafür bereits kennen gelernt: ggplot2. In einem ersten Schritt machen wir univariate Analysen, d.h. wir visualisieren die Verteilung jeweils einer Variable.
Doch bevor wir uns Verteilungen anschauen, wollen wir die Spalten mit geographischen Informationen visualisieren. Dazu können wir das Package leaflet verwenden. Es erstellt uns eine dynamische Karte mit Markern. Wichtig: wir visualisieren hier nur ein Sample von 10’000 Pickup Koordinaten, sonst dauert der Befehl etwas lange…
# *****************************************************
# 3. Explorative Analyse ------------------------------
# UNIVARIATE ANALYSE
# Wir plotten ein Sample von Pickup Locations
leaflet(data = sample_n(train, 1e04)) %>%
addTiles() %>%
setView(-73.935242, 40.730610, zoom = 10) %>%
addCircleMarkers(~ pickup_longitude,
~ pickup_latitude,
radius = 1,
color = "blue",
fillOpacity = 0.3)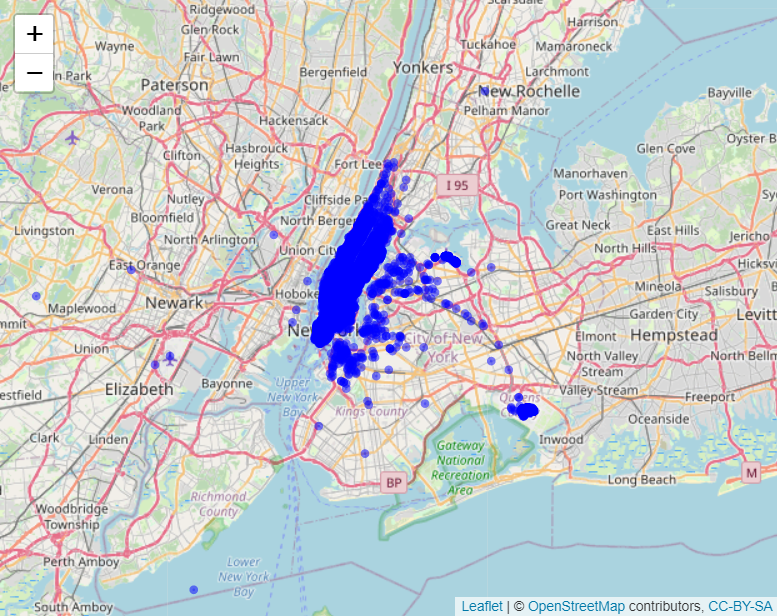
Als nächstes visualisieren wir Verteilungen (univariat):
- Für numerische Spalten verwenden wir grundsätzlich Histogramme.
- Für kategorische Spalten verwenden wir meist Barplots (Säulendiagramme), welche die (absoluten oder relativen) Häufigkeiten der verschiedenen Kategorien darstellen.
# Histogramm 'trip_duration'
train %>%
ggplot(aes(x = trip_duration)) +
geom_histogram(bins = 150, fill = "orchid1") +
scale_x_log10() +
scale_y_sqrt() +
theme_bw()
# Histogramm 'pickup_datetime'
train %>%
ggplot(aes(x = pickup_datetime)) +
geom_histogram(bins = 100, fill = "orchid1") +
labs(x = "Pickup Datum") +
theme_bw()
# Barplot 'vendor_id'
train %>%
mutate(vendor_id = factor(vendor_id)) %>%
ggplot(aes(x = vendor_id, fill = vendor_id)) +
geom_bar() +
theme_bw() +
theme(legend.position = "none")
# Barplot 'passenger_count'
train %>%
mutate(passenger_count = factor(passenger_count)) %>%
ggplot(aes(x = passenger_count, fill = passenger_count)) +
geom_bar() +
theme_bw() +
scale_y_sqrt() +
theme(legend.position = "none")
# Barplot 'store_and_fwd_flag'
train %>%
mutate(store_and_fwd_flag = factor(store_and_fwd_flag)) %>%
ggplot(aes(x = store_and_fwd_flag, fill = store_and_fwd_flag)) +
geom_bar() +
theme_bw() +
scale_y_log10() +
theme(legend.position = "none")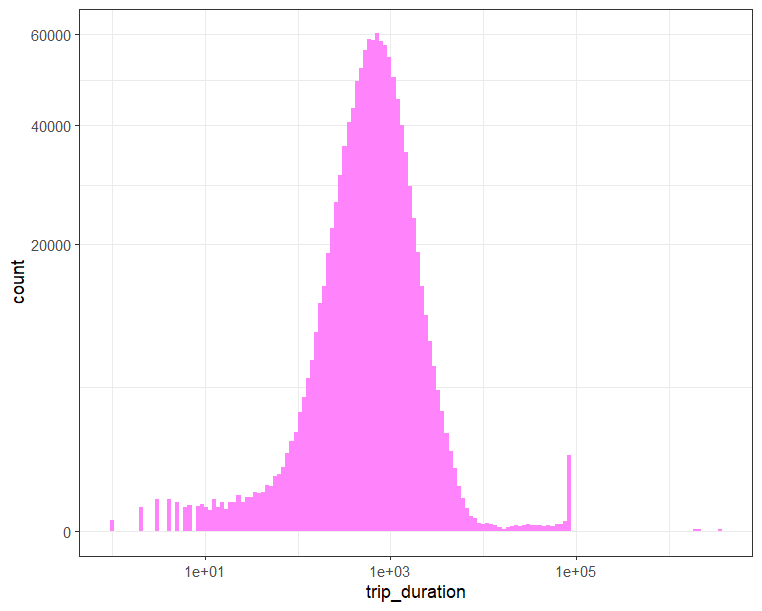
Wir schauen uns hier nur den ersten Plot, das Histogramm für die Trip Durations (unsere Output Variable), an. Sie sehen, dass wir Achsentransformationen durchgeführt haben. Warum wir das tun und wie das funktioniert, beschreibt die folgende Infobox.
Warum transformieren wir die Skalen der y- und/oder x-Achse von Plots?
Wir verwenden oft eine logarithmische Skala, um die Visualisierung von Variablen, die ganz kleine aber gleichzeitig auch ganz grosse Werte annehmen können, zu verdeutlichen. Bei einer linearen Skala ist der Abstand zwischen den ticks einer Achse konstant (z.B. immer 1). Bei einer logarithmischen Skala (zur Basis 10) entspricht der Abstand zwischen zwei ticks immer einer Multiplikation mit 10. Das ist vor allem dann nützlich, wenn Daten exponentiell verteilt sind.
Folgendes Beispiel zeigt, wie drei Werte einer Variable (10, 500 und 100’000) auf einer Log-Skala (zur Basis 10) dargestellt werden können:
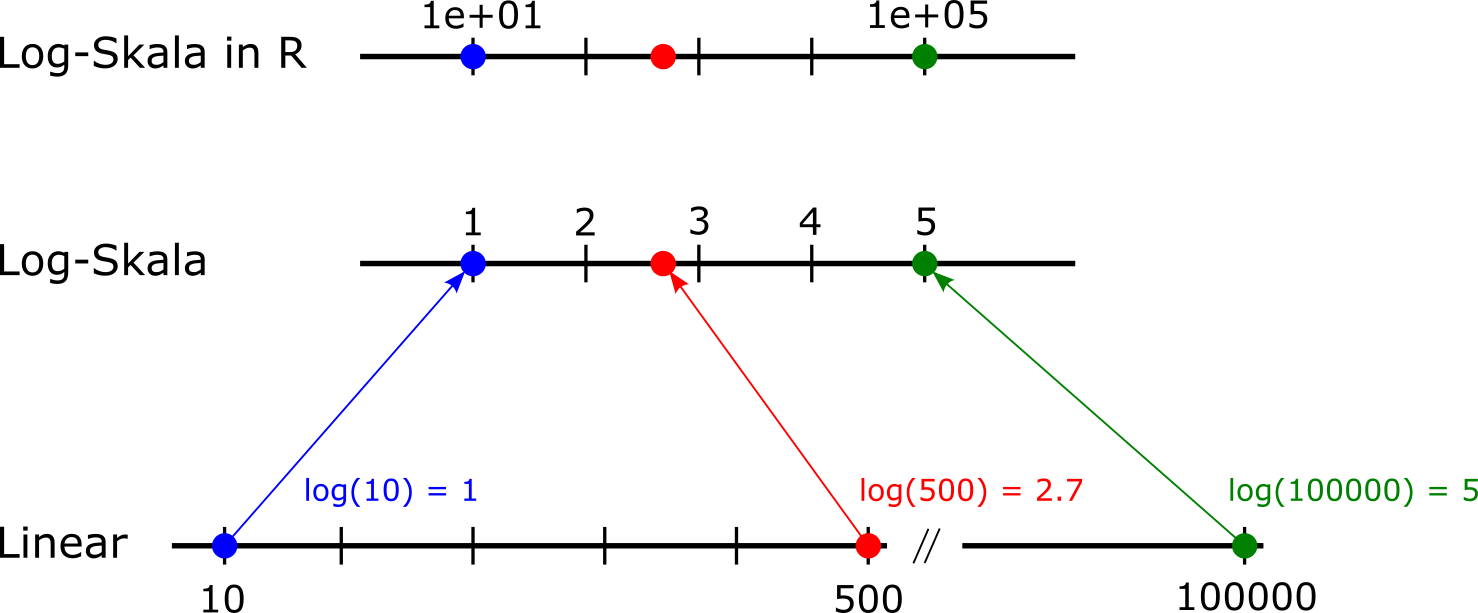
Eine weitere mögliche Transformation ist die Quadratwurzel Transformation. Indem wir die Quadratwurzel für kleine und ganz grosse Zahlen rechnen, können die Werte auf einen kleineren Wertebereich zurückgestutzt werden.
Für welche Transformation würden Sie sich für unsere Output-Variable trip_duration entscheiden?
Nun kommen wir zum interessanteren Teil: bivariate Analysen. ggplot2 bietet viele verschiedene Möglichkeiten, um Daten bivariat oder sogar multivariat zu visualisieren. In der Folge zeigen wir Ihnen eine (kleine) Auswahl von Möglichkeiten:
# BIVARIATE ANALYSE
# Wochentag vs. Tageszeit
train %>%
mutate(weekday = lubridate::wday(pickup_datetime,
label = TRUE,
abbr = FALSE,
week_start = 1),
hour = lubridate::hour(pickup_datetime)) %>%
ggplot(aes(x = hour)) +
geom_bar() +
facet_wrap(vars(weekday), nrow = 7) +
labs(x = NULL) +
theme_bw()
# Alternative
train %>%
mutate(weekday = lubridate::wday(pickup_datetime,
label = TRUE,
abbr = FALSE,
week_start = 1),
hour = lubridate::hour(pickup_datetime)) %>%
count(weekday, hour) %>%
ggplot(aes(x = hour, y = n, group = weekday, color = weekday)) +
geom_line(linewidth = 1.5) +
labs(x = NULL, y = "Anzahl") +
theme_bw() +
theme(legend.title = element_blank())
# Median Tripdauer (Zeitreihe)
train %>%
mutate(date = lubridate::as_date(pickup_datetime)) %>%
group_by(date) %>%
summarise(median_dur = median(trip_duration / 60)) %>%
ggplot(aes(x = date, y = median_dur)) +
geom_line(linewidth = 1, color = "orchid1") +
labs(x = NULL, y = "Median Tripdauer (Min.)") +
theme_bw() +
scale_x_date(date_breaks = "1 month", date_labels = "%b")
# Median Tripdauer (Min.) vs. Wochentage und 'vendor_id'
train %>%
mutate(weekday = lubridate::wday(pickup_datetime,
label = TRUE,
abbr = FALSE,
week_start = 1),
hour = lubridate::hour(pickup_datetime),
vendor_id = factor(vendor_id)) %>%
group_by(weekday, vendor_id) %>%
summarise(median_dur = median(trip_duration / 60)) %>%
ggplot(aes(x = weekday, y = median_dur, fill = vendor_id)) +
geom_bar(position = "dodge", stat = "identity") +
labs(x = NULL, y = "Median Duration (Min.)") +
theme_bw()
# Median Tripdauer (Min.) vs. Tagesstunden und 'vendor_id'
train %>%
mutate(weekday = lubridate::wday(pickup_datetime,
label = TRUE,
abbr = FALSE,
week_start = 1),
hour = lubridate::hour(pickup_datetime),
vendor_id = factor(vendor_id)) %>%
group_by(hour, vendor_id) %>%
summarise(median_dur = median(trip_duration / 60)) %>%
ggplot(aes(x = hour, y = median_dur, fill = vendor_id)) +
geom_bar(position = "dodge", stat = "identity") +
labs(x = NULL, y = "Median Duration (Min.)") +
theme_bw()
# Tripdauer vs. Anzahl Passagiere
train %>%
mutate(passenger_count = factor(passenger_count)) %>%
ggplot(aes(x = passenger_count, y = trip_duration)) +
geom_boxplot(fill = "orchid1") +
scale_y_log10() +
labs(x = "Anzahl Passagiere", y = "Tripdauer") +
theme_bw()
# Tripdauer vs. Tripinfo gespeichert oder direkt gesendet
train %>%
mutate(store_and_fwd_flag = factor(store_and_fwd_flag)) %>%
ggplot(aes(x = store_and_fwd_flag, y = trip_duration)) +
geom_boxplot(fill = "orchid1") +
scale_y_log10() +
labs(x = "Tripinfo gespeichert?", y = "Tripdauer") +
theme_bw()
# Streudiagramm Tripdauer vs. Durchschnittstemperatur
train %>%
sample_n(1e04) %>%
ggplot(aes(x = avg_temp, y = trip_duration)) +
geom_point(color = "orchid1", alpha = 0.5) +
geom_smooth(method = 'lm', formula = y ~ x, color = "black") +
scale_y_log10() +
theme_bw()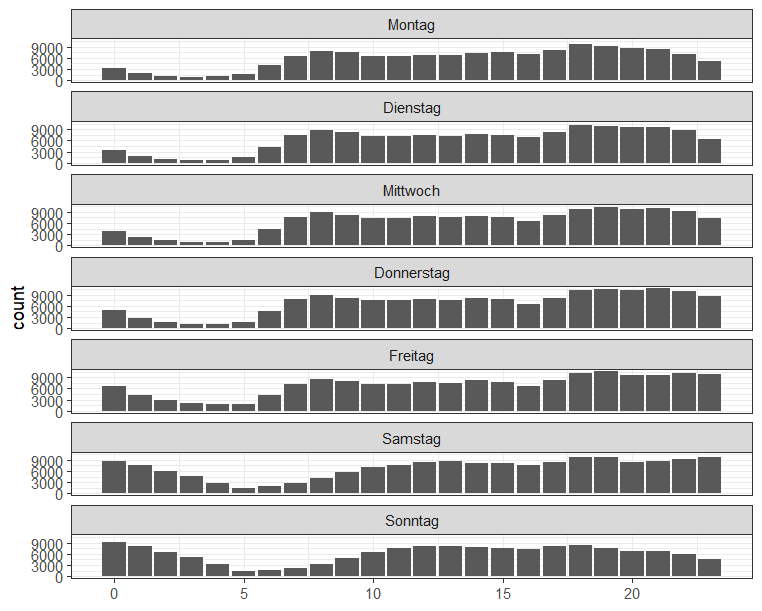
Sie sehen oben nur den ersten Plot. Schauen Sie sich alle anderen Plots genau an, wenn Sie die Plots lokal auf Ihrem Rechner generieren.
Nun haben wir bereits einige Erkenntnisse gewonnen. Zum Abschluss speichern wir auch hier die resultierenden Dataframes im Unterordner zwischenresultate.
# *****************************************************
# 4. Zwischenresultate speichern ----------------------
# Wir speichern 'train' und 'test' in dem Ordner 'Zwischenresultate'
write_rds(train, "zwischenresultate/train.rds")
write_rds(test, "zwischenresultate/test.rds")Hier können Sie nun das vollständige R-Skript in Ihr lokales Projekt übernehmen:
4. Feature Engineering und Data Cleaning
Im dritten Skript versuchen wir, bessere Features zu kreieren. Was heisst hier besser? Wir wollen die bestehenden Variablen modifizieren oder auf clevere Art und Weise kombinieren, so dass wir bessere Prädiktoren für die Vorhersage der Trip Dauer finden. Das ist eine anspruchsvolle Aufgabe, bei der unter anderem auch Ihre Kreativität gefragt ist.
Wir beginnen damit die benötigten R Packages zu laden. Ausserdem laden wir den Trainingsdatensatz aus dem Ordner zwischenresultate (den Testdatensatz benötigen wir in diesem Schritt nicht):
# *****************************************************
# 1. Vorarbeiten --------------------------------------
# Workspace aufräumen
rm(list = ls())
# Lade Software aus R Packages
library(tidyverse)
library(tidymodels)
library(leaflet)
library(geosphere)
library(corrplot)
# Lade Zwischenresultate
train1 <- read_rds("zwischenresultate/train.rds")Feature Engineering
Das erste Feature, das wir bilden, ist die direkte Distanz (in Meter) zwischen der Pickup Location und der Dropoff Location. Wir rechnen diese Distanz mit der Funktion distCosine() aus dem geosphere Package. Dies dürfte ein sehr wichtiges Feature werden, da die Distanz einen starken Einfluss auf die Dauer eines Trips haben sollte.
Mit diesem Feature ergeben sich allerdings auch zwei Probleme:
- Es handelt sich nicht um die effektive Distanz zwischen zwei Orten, da die Taxis ja nicht fliegen können. D.h. die effektive Distanz hängt von der Strasseninfrastruktur ab, wodurch die direkte Distanz im Normalfall kürzer als die effektive Distanz ist. Im optimalen Fall würden wir hier die effektiven Distanzen von einem Navigationsdienst wie GoogleMaps beziehen.
- Dieses Feature kann problematisch sein, wenn im produktiven System (unsere App, auf der man Taxi Fahrten kaufen kann) die Dropoff Location nicht gegeben ist, wenn die Vorhersage gemacht werden soll. Wir nehmen hier aber an, dass die Kundin oder der Kunde die Dropoff Location beim Kauf im App angibt.
Nachdem wir das Feature gebildet haben, schauen wir uns den Zusammenhang zwischen dem neuen Feature und der Dauer eines Trips als Streudiagramm an.
# *****************************************************
# 2. Feature Engineering ------------------------------
# Berechne die direkte Distanz (in Meter) zwischen Pickup und Dropoff
train1$dist <- distCosine(
train1[,c("pickup_longitude","pickup_latitude")],
train1[,c("dropoff_longitude","dropoff_latitude")]
)
# Streudiagramm
train1 %>%
sample_n(1e4) %>%
ggplot(aes(dist, trip_duration)) +
geom_point() +
scale_x_log10() +
scale_y_log10() +
geom_smooth(method = "lm") +
labs(x = "Distanz (m)", y = "Tripdauer (s)") +
theme_bw()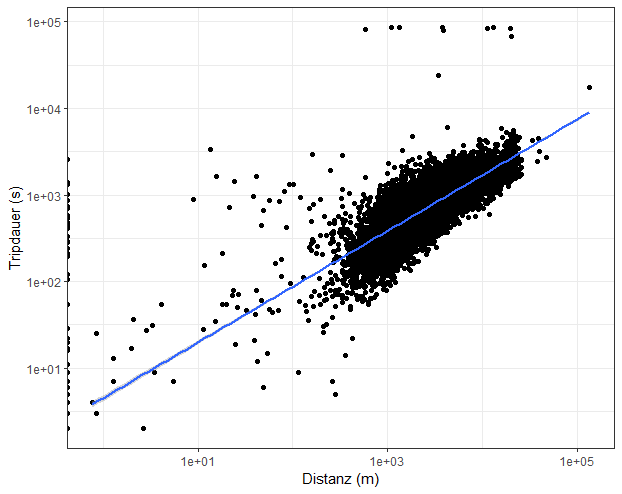
Sie sehen, dass wir hier beide Achsen mit dem Logarithmus zur Basis 10 transformiert haben. Wir haben also ein Log-Log Streudiagramm, doch mehr dazu in folgender Infobox.
Was Sie zu Log-Log Streudiagrammen wissen sollten
Nehmen wir an, dass der Zusammenhang zwischen \(y\) und \(x\) wie folgt ist: \(y = a \cdot x^{b}\) (Potenzgesetz). Nun logarithmieren wir beide Seiten der Gleichung und finden folgende Form: \(log(y) = log(a) + b \cdot log(x)\). Das Potenzgesetz führt also im Log-Log Streudiagramm zu einer Geraden!
Nehmen wir an, dass der Zusammenhang zwischen \(y\) und \(x\) wie folgt ist: \(y = a \cdot e^{bx}\) (Exponentialgesetz). Wenn wir hier beide Seiten logarithmieren, dann kriegen wir folgende Gleichung: \(log(y) = log(a) + bx \cdot log(e)\). Wir sehen also in diesem Fall eine Gerade nur dann, wenn lediglich die y-Achse logarithmiert wird!
Es dürfte sich in obiger Abbildung also um einen Zusammenhang zwischen der Trip Dauer und der (direkten) Distanz handeln, der grob einem Potenzgesetz folgt. Das macht irgendwie auch Sinn. Die Tripdauer steigt nicht linear mit zunehmender Distanz, sondern erhöht sich immer stärker je grösser die Distanz.
Quelle: Wikipedia
Als nächstes rechnen wir die Distanzen zwischen dem Start-/Endpunkt der Reise und den beiden grossen New Yorker Flughäfen (JFK und LaGuardia). Die Hypothese hier ist, dass Taxi Trips vom oder zum Flughafen eher längere Trips sind. Wir wollen also ein Feature, das für jeden Trip bestimmt, ob es sich um einen Flughafentrip handelt oder nicht. Wenn die Distanz zwischen Pickup/Dropoff und dem Flughafen JFK (analog für LaGuardia) kleiner als 2000 Meter ist, dann handelt es sich um einen Flughafen Trip.
# Koordinaten der beiden Flughäfen JFK und Laguardia
jfk_coord <- data.frame(lon = -73.778889, lat = 40.639722)
laguardia_coord <- data.frame(lon = -73.872611, lat = 40.77725)
# Berechne (direkte) Distanzen von Pickup/Dropoff zu JFK/Laguardia
train1$jfk_dist_pick <- distCosine(train1[,c("pickup_longitude","pickup_latitude")], jfk_coord)
train1$jfk_dist_drop <- distCosine(train1[,c("dropoff_longitude","dropoff_latitude")], jfk_coord)
train1$lg_dist_pick <- distCosine(train1[,c("pickup_longitude","pickup_latitude")], laguardia_coord)
train1$lg_dist_drop <- distCosine(train1[,c("dropoff_longitude","dropoff_latitude")], laguardia_coord)
# Wir definieren zwei neue Features: 'jfk_trip' und 'lg_trip'.
# Wenn die Pickup oder Dropoff Distanz zu JFK/Laguardia kleiner als 2000m
# ist, dann handelt es sich um einen JFK/Laguardia Trip.
train1 <- train1 %>%
mutate(
jfk_trip = factor((jfk_dist_pick < 2e3) | (jfk_dist_drop < 2e3), levels = c(TRUE, FALSE), labels = c("yes","no")),
lg_trip = factor((lg_dist_pick < 2e3) | (lg_dist_drop < 2e3), levels = c(TRUE, FALSE), labels = c("yes","no"))
)
# Boxplot
train1 %>%
ggplot(aes(x = jfk_trip, y = trip_duration)) +
geom_boxplot(fill = "orchid1") +
scale_y_log10() +
labs(x = "JFK Trip", y = "Tripdauer (s)") +
theme_bw()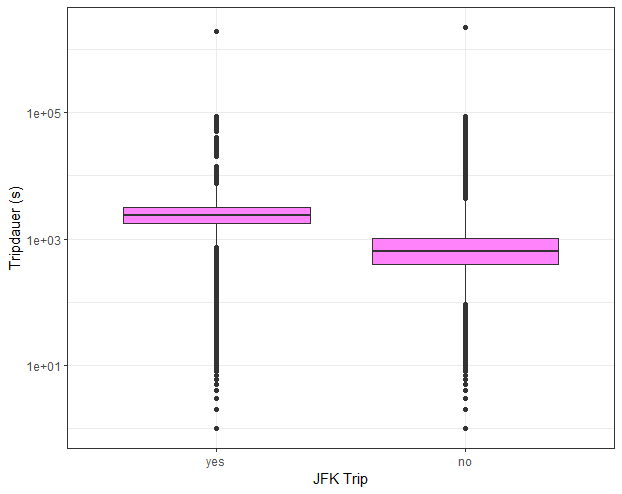
Datumswerte können nicht direkt in einen ML-Algorithmus gespiesen werden. Wir müssen numerische oder kategorische Features extrahieren. Es gibt unter anderem folgende Möglichkeiten:
- Tag (Faktor oder numerisch)
- Monat (typsicherweise als Faktor)
- Jahr (typischerweise als Faktor)
- Wochentag (Faktor)
- Stunde (Faktor oder numerisch)
In unten stehenden Block extrahieren wir Monat, Wochentag und Stunde aus der Variable pickup_datetime. Ausserdem bilden wir ein Feature work, das den Wert "yes" annimmt, falls ein Taxi Trip unter der Woche (Wochentag) zwischen 8.00 Uhr und 18.00 Uhr (Zeit) stattgefunden hat und sonst "no". Die Hypothese ist hier, dass das Verkehrsaufkommen durch den Berufsverkehr die Taxifahrten in der Tendenz verlängert.
# Features basierend auf Datumswerten
train1 <- train1 %>%
mutate(
month = factor(lubridate::month(pickup_datetime, label = TRUE), ordered = FALSE),
wday = factor(lubridate::wday(pickup_datetime, label = TRUE, abbr = FALSE, week_start = 1), ordered = FALSE),
hour = lubridate::hour(pickup_datetime),
work = factor((hour %in% seq(8,18)) & (wday %in% c("Montag","Dienstag","Mittwoch","Donnerstag","Freitag")),
levels = c(TRUE, FALSE),
labels = c("yes","no"))
)Wir wollen auch die Wetterdaten nützen, um zwei neue Features zu bilden. has_snow nimmt den Wert "yes" an, wenn entweder snowfall oder snowdepth (oder beide) grösser als 0 sind. has_rain kategorisiert die Angaben aus der Variable precipitation in "yes" und "no" Werte.
# Features basierend auf Wetter
train1 <- train1 %>%
mutate(
has_snow = factor((snowfall > 0) | (snowdepth > 0), levels = c(TRUE, FALSE), labels = c("yes","no")),
has_rain = factor(precipitation > 0, levels = c(TRUE, FALSE), labels = c("yes","no"))
)Wir haben oben bereits die Vermutung angestellt, dass das Feature dist sehr wichtig sein könnte. Darum bilden wir hier noch die Polynome bis zum vierten Grad. Da wir sehr viele Trainingsdaten haben, sollte dies nicht zu einem Overfitting führen. (Zu Polynomen bzw. polynomischer Regression später mehr.)
# Polynomials 'dist'
train1 <- train1 %>%
mutate(
dist2 = dist^2,
dist3 = dist^3,
dist4 = dist^4
)Weitere Ideen für das Feature Engineering finden Sie auf Kaggle, allerdings mit Implementationen in Python.
Data Cleaning
Wir haben im Schritt Import und Preprocessing ja bereits etwas Data Cleaning betrieben und Datentypen angepasst, Duplikate entfernt, etc. Hier machen wir nun das inhaltliche Data Cleaning basierend auf unseren Erkenntnissen aus dem explorativen Teil und dem Feature Engineering.
Sie haben vielleicht bereits in der einen oder anderen Visualisierung gesehen, dass wir Trips haben mit einer Distanz von 0 Metern. In einem ersten Schritt geben wir uns diese Beobachtungen als Tabelle aus. Es handelt sich um eine stattliche Zahl von 4’426 Trips, bei denen sich das Taxi offenbar nicht bewegt hat. Wir werden diese Beobachtungen rausschmeissen.
# *****************************************************
# 3. Cleaning Up ---------------------------------------
# Trips mit einer (direkten) Distanz von 0m
train1 %>%
filter(dist == 0) %>%
select(id, pickup_datetime, dropoff_datetime, trip_duration,
pickup_longitude, pickup_latitude, dropoff_longitude,
dropoff_latitude, dist)# A tibble: 4,426 × 9
id pickup_datetime dropoff_datetime trip_duration pickup_longitude pickup_latitude
<chr> <dttm> <dttm> <dbl> <dbl> <dbl>
1 id3085848 2016-06-08 20:17:20 2016-06-08 20:17:26 6 -74.0 40.8
2 id1084460 2016-01-09 23:40:42 2016-01-09 23:52:51 729 -74.0 40.8
3 id3245337 2016-05-07 17:07:22 2016-05-07 17:07:28 6 -74.0 40.8
4 id0463199 2016-03-18 11:03:05 2016-03-18 11:16:10 785 -74.0 40.8
5 id1582001 2016-03-24 19:21:24 2016-03-24 19:21:46 22 -74.0 40.8
6 id0753167 2016-05-18 13:38:53 2016-05-18 13:39:38 45 -73.9 40.8
7 id1277510 2016-03-16 01:13:55 2016-03-16 01:18:25 270 -74.0 40.7
8 id2155547 2016-04-13 11:29:56 2016-04-13 11:35:08 312 -74.0 40.7
9 id3974381 2016-06-06 14:06:10 2016-06-06 14:06:16 6 -73.9 40.7
10 id0741193 2016-05-22 12:58:09 2016-05-22 13:00:59 170 -74.0 40.8
# ℹ 4,416 more rows
# ℹ 3 more variables: dropoff_longitude <dbl>, dropoff_latitude <dbl>, dist <dbl>
# ℹ Use `print(n = ...)` to see more rowsAls nächstes verwenden wir nochmals das leaflet Package, um unrealistische Pickup oder Dropoff Locations auf der Karte anzuschauen. Wir werden Beobachtungen mit unrealistischen Koordinaten entfernen.
# Unrealistische Pickup Locations
leaflet(data = train1 %>% filter(jfk_dist_pick > 3e5)) %>%
addTiles() %>%
setView(-92.00, 41.0, zoom = 3) %>%
addMarkers(~ pickup_longitude, ~ pickup_latitude)
# Unrealistische Dropoff Locations
leaflet(data = train1 %>% filter(jfk_dist_drop > 3e5)) %>%
addTiles() %>%
setView(-92.00, 41.0, zoom = 3) %>%
addMarkers(~ dropoff_longitude, ~ dropoff_latitude)Als nächstes machen wir einen etwas heiklen Schritt, den wir in einem realen Projekt wohl eher nicht tun würden. Wir rechnen nämlich nun die durchschnittliche Geschwindigkeit des Taxis für jeden Trip aus. Um einen km/h Wert zu erhalten, stellen wir folgende Rechnung auf:
\[ \frac{m/1000}{s/3600}=\frac{m}{1000} \cdot \frac{3600}{s} = 3.6 \cdot \frac{m}{s} \]
Warum ist dieser Schritt heikel? Weil wir bei der Berechnung der durchschnittlichen Geschwindigkeit die Dauer des Trips verwenden und das ist ja unsere Output-Variable, die es in einem produktiven System vorherzusagen gilt. Um die Daten anständig zu putzen, verwenden wir diese Variable hier nun aber trotzdem, denn sie eignet sich gut, um unrealistische Trips zu entfernen. Wir lassen uns in unten stehendem Code Block unrealistisch schnelle und unrealistisch langsame Taxifahren ausgeben.
# Wir berechnen die durchschnittliche Geschwindigkeit (km/h).
# Achtung: gefährlich, da wir die Geschwindigkeit für
# richtige Vorhersagen nicht werden rechnen können (da
# trip_duration nicht bekannt).
train1$kmh <- 3.6 * train1$dist / train1$trip_duration
# Sehr schnelle Trips
train1 %>%
select(id, pickup_datetime, dropoff_datetime, trip_duration, dist, kmh) %>%
arrange(desc(kmh)) %>%
print(n = 20)
# Sehr langsame Trips
train1 %>%
filter(dist > 0) %>%
select(id, pickup_datetime, dropoff_datetime, trip_duration, dist, kmh) %>%
arrange(kmh) %>%
print(n = 20)# A tibble: 1,089,551 × 6
id pickup_datetime dropoff_datetime trip_duration dist kmh
<chr> <dttm> <dttm> <dbl> <dbl> <dbl>
1 id0759846 2016-06-22 08:56:20 2016-06-23 08:55:02 86322 0.645 0.0000269
2 id0385849 2016-04-04 13:03:06 2016-04-05 12:03:23 82817 1.28 0.0000554
3 id3917283 2016-06-06 16:39:09 2016-06-07 16:30:50 85901 1.43 0.0000599
4 id2180713 2016-01-16 03:46:48 2016-01-17 00:00:00 72792 2.88 0.000142
5 id2191163 2016-06-08 20:09:16 2016-06-09 17:48:05 77929 4.58 0.000212
6 id0228147 2016-03-19 21:30:05 2016-03-20 21:29:03 86338 7.47 0.000312
7 id0529553 2016-05-25 07:17:56 2016-05-26 07:17:17 86361 8.61 0.000359
8 id0994588 2016-03-14 19:33:11 2016-03-15 19:27:47 86076 18.8 0.000784
9 id3558644 2016-06-03 07:43:56 2016-06-04 07:42:02 86286 26.3 0.00110
10 id3228966 2016-01-21 18:09:26 2016-01-21 18:41:49 1943 0.645 0.00119 (Obiger Output zeigt nur die langsamen Trips.)
Ihnen ist vielleicht auch bereits aufgefallen, dass einige Trips genau um Mitternacht enden. Es wäre ein grosser Zufall, wenn die Trips wirklich haargenau um Mitternacht enden. Das Phänomen deutet eher auf ein Systemverhalten hin. Der Taximeter scheint gewisse Enddaten einfach auf Mitternacht zu setzen. Es dürfte eine gute Idee sein, solche Trips zu entfernen. Aber schauen wir uns die 165 Trips zuerst an. Viele dieser 165 Beobachtungen sind sehr lange und wahrscheinlich unplausible Fahrten. Es dürfte eine gute Idee sein, diese zu entfernen.
# Zeit aus 'dropoff_datetime' extrahieren
train1$dropoff_time <- format(train1$dropoff_datetime, format = "%H:%M:%S")
# Trips, wo die Endzeit genau Mitternacht ist
train1 %>%
select(id, pickup_datetime, dropoff_datetime, dropoff_time, trip_duration, dist, kmh) %>%
filter(dropoff_time == "00:00:00") %>%
print(n = 200)# A tibble: 165 × 7
id pickup_datetime dropoff_datetime dropoff_time trip_duration dist kmh
<chr> <dttm> <dttm> <chr> <dbl> <dbl> <dbl>
1 id1642190 2016-04-25 17:17:25 2016-04-26 00:00:00 00:00:00 24155 9870. 1.47
2 id1441883 2016-04-24 18:21:18 2016-04-25 00:00:00 00:00:00 20322 20400. 3.61
3 id1807351 2016-03-12 23:52:17 2016-03-13 00:00:00 00:00:00 463 4118. 32.0
4 id3491590 2016-02-04 06:39:19 2016-02-05 00:00:00 00:00:00 62441 2148. 0.124
5 id3152653 2016-04-17 22:01:17 2016-04-18 00:00:00 00:00:00 7123 23962. 12.1
6 id2642330 2016-04-29 22:22:41 2016-04-30 00:00:00 00:00:00 5839 7364. 4.54
7 id1407337 2016-03-15 20:34:47 2016-03-16 00:00:00 00:00:00 12313 3450. 1.01
8 id2328083 2016-05-14 23:52:25 2016-05-15 00:00:00 00:00:00 455 1188. 9.40
9 id0232891 2016-03-05 15:35:09 2016-03-06 00:00:00 00:00:00 30291 2255. 0.268
10 id0138001 2016-06-25 10:11:49 2016-06-26 00:00:00 00:00:00 49691 989. 0.0717 Vielleicht ist Ihnen auch bereits aufgefallen, dass viele Trips sehr kurz sind mit einer trip_duration von weniger als einer Minute. Wir zählen zuerst kurz, wie viele Trips tatsächlich weniger als eine Minute dauern.
# Wie viele Trips haben eine Duration von weniger als einer Minute?
sum(train1$trip_duration < 60)[1] 6492Ob diese sehr kurzen Trips wirklich aus dem Datensatz entfernt werden sollen oder nicht, darüber kann debattiert werden. Wenn es sich tatsächlich um richtige Taxi Trips handelt, dann sollten wir sie im Trainingsdatensatz drin lassen. Wenn wir jedoch das Gefühl haben, dass es sich um falsche Eingaben handelt, dann sollten wir sie entfernen. Wir werden hier annehmen, dass es sich um falsche Eingaben handelt und sie dementsprechend unten entfernen. Selbstverständlich ist die Grenze von einer Minute auch sehr willkürlich gewählt.
Das effektive Data Cleaning kann dann ganz einfach mit einer tidyverse Pipeline und der Funktion filter() vollzogen werden:
# DATA CLEANING
train1 <- train1 %>%
filter(dist > 0,
jfk_dist_pick < 3e5 & jfk_dist_drop < 3e5,
kmh >= 2.0 & kmh < 200,
dropoff_time != "00:00:00",
trip_duration >= 60)Korrelationsanalyse
Wir wollen nun eine Korrelationsmatrix aller Variablen (inkl. der Output-Variable) erstellen. Das machen wir in drei Schritten:
- Wir entfernen nicht-relevante Variablen mit
select(). - Wir wandeln alle Faktoren in numerische Werte um, denn Korrelationen können nur für numerische Features berechnet werden. Hier können wir die Faktoren ganz einfach mit
as.integer()in numerische Werte umwandeln. - Wir berechnen die Korrelationen mit der Funktion
cor(). Und zwar berechnen wir den Spearman Korrelationskoeffizienten, der etwas robuster ist als der Pearson Korrelationskoeffizient, den Sie sicher bereits kennen. Mit der Funktioncorrplot()aus dem gleichnamigenRPackage können wir die Matrix visualisieren.
# *****************************************************
# 4. Korrelationen ------------------------------------
# Nun wollen wir eine Korrelationsmatrix rechnen. Dazu entfernen wir
# in einem ersten Schritt alle nicht-relevanten Features.
# Danach müssen wir alle nicht-numerischen Features in numerische umwandeln.
# Dazu verwenden wir as.integer(). Danach rechnen wir die Spearman Rank Korrelation
# für alle möglichen Kombinationen und plotten das Resultat als Matrix.
train1 %>%
select(-id, -pickup_datetime, -dropoff_datetime, -dropoff_time, -jfk_dist_pick,
-jfk_dist_drop, -lg_dist_pick, -lg_dist_drop, -min_temp, -max_temp, -kmh) %>%
mutate(passenger_count = as.integer(passenger_count),
vendor_id = as.integer(vendor_id),
store_and_fwd_flag = as.integer(as.factor(store_and_fwd_flag)),
jfk_trip = as.integer(jfk_trip),
wday = as.integer(wday),
month = as.integer(month),
work = as.integer(work),
lg_trip = as.integer(lg_trip),
has_snow = as.integer(has_snow),
has_rain = as.integer(has_rain)) %>%
select(trip_duration, everything()) %>%
cor(use = "complete.obs", method = "spearman") %>%
corrplot(type = "lower", diag = FALSE, tl.col = "black", tl.cex = 0.7)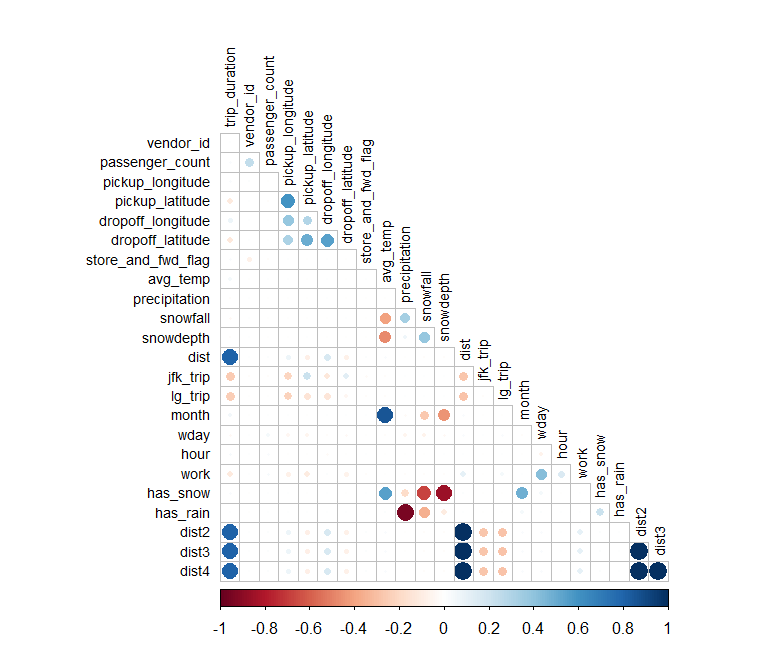
Die erste Spalte der Matrix zeigt, welche Features besonders stark mit der Output-Variable trip_duration korrelieren. Es zeigt sich bereits hier, dass ein Modell wohl sehr stark auf das Distanz Feature fokussieren wird.
Folgende Abbildung (Quelle Bild: Wikipedia) zeigt die Schwäche von Korrelationskoeffizienten auf. Das Problem ist, dass nicht-lineare Zusammenhänge insbesondere vom Pearson Korrelationskoeffizienten nicht erkannt werden (siehe dritte Zeile in Abbildung).
{kind=link}
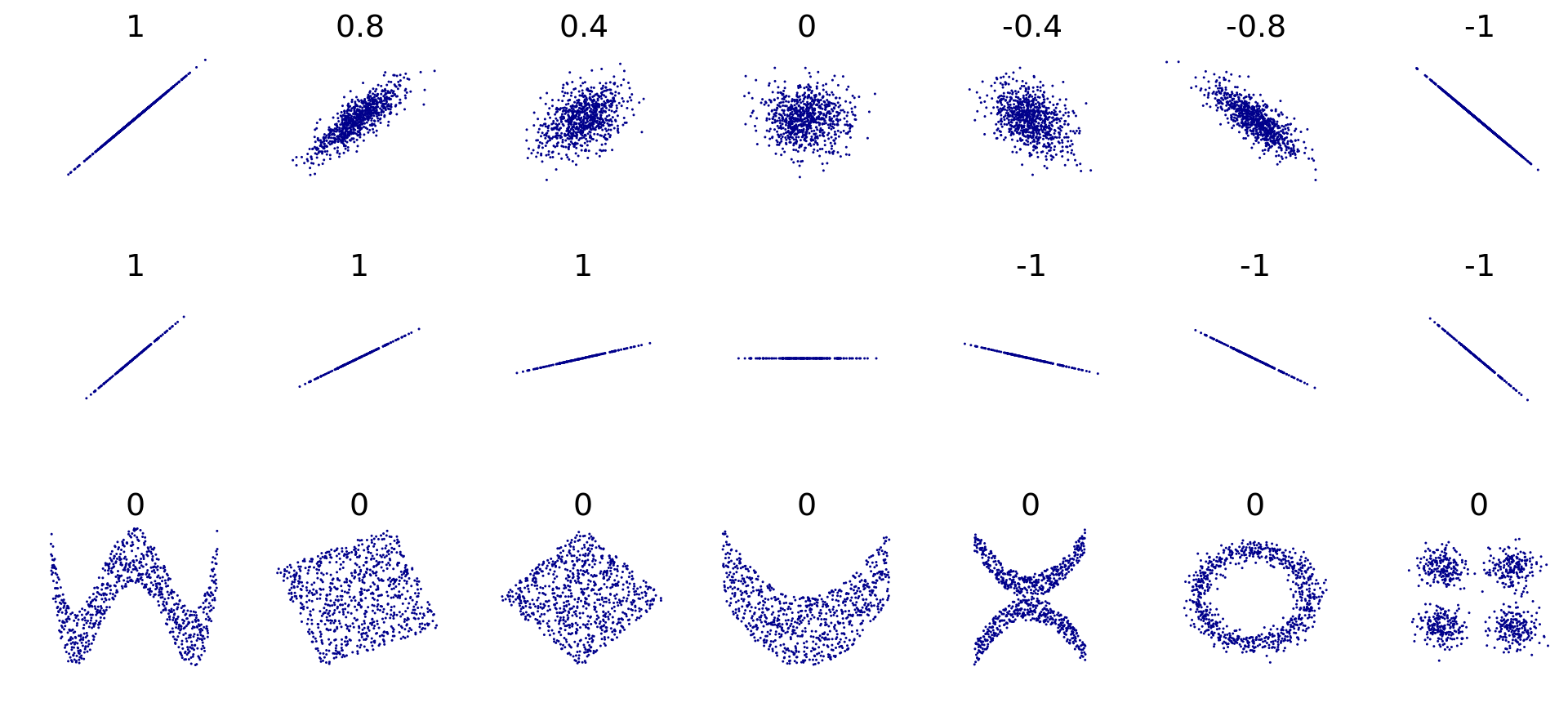
Zum Schluss speichern wir den überarbeitete Dataframe train1 im Unterordner zwischenresultate.
# *****************************************************
# 5. Zwischenresultate speichern ----------------------
# Wir speichern 'train1' in dem Ordner 'Zwischenresultate'.
write_rds(train1, "zwischenresultate/train1.rds")Hier können Sie nun das vollständige R-Skript in Ihr lokales Projekt übernehmen:
5. Modelling
Im vierten und letzten Skript werden wir nun ein ML-Modell rechnen. Dazu gehören viele Komponenten: z.B. machen wir uns Gedanken, wie wir die Modellgüte evaluieren können ohne bereits auf den Testdatensatz zuzugreifen (Cross-Validation) oder wie wir die Hyperparameter eines Modells optimieren können. Ganz zum Schluss werden wir die Vorhersagegüte unseres Modells auf dem Testset messen.
Wir beginnen damit die benötigten R Packages zu laden. Ausserdem laden wir den Trainings- und Testdatensatz aus dem Ordner zwischenresultate. Wir definieren auch gleich eine Funktion multi_metric(), so dass wir immer gleich zwei Gütemasse, nämlich den Root Mean Squared Error (RMSE) und den Mean Absolute Error (MAE), gleichzeitig messen können. metric_set() ist eine Funktion aus tidymodels, die es uns erlaubt mehrere Gütemasse zu kombinieren.
# *****************************************************
# 1. Vorarbeiten --------------------------------------
# Workspace aufräumen
rm(list = ls())
# Lade Software aus R Packages
library(tidyverse)
library(tidymodels)
library(leaflet)
library(geosphere)
library(corrplot)
library(vetiver) # Um das finale Modell zu exportieren.
# Lade Zwischenresultate
train2 <- read_rds("zwischenresultate/train1.rds")
test2 <- read_rds("zwischenresultate/test.rds")
# Helper um mehrere Gütemasse gleichzeitig zu rechnen
multi_metric <- metric_set(rmse, mae)Testset vorbereiten
Als erstes müssen wir alle Feature Engineering und Data Cleaning Schritte, die wir im vorangehenden Teil für den Trainingsdatensatz gemacht haben, nun auch auf dem Testdatensatz vollziehen. Der folgende (lange) Code Block macht genau das. Wir gehen hier nicht weiter ins Detail, da der Code grösstenteils identisch ist (mit der Ausnahme, dass überall, wo vorher train1 stand nun test2 steht).
# Berechne die direkte Distanz (in Meter) zwischen Pickup und Dropoff
test2$dist <- distCosine(
test2[,c("pickup_longitude","pickup_latitude")],
test2[,c("dropoff_longitude","dropoff_latitude")]
)
# Koordinaten der beiden Flughäfen JFK und Laguardia
jfk_coord <- data.frame(lon = -73.778889, lat = 40.639722)
laguardia_coord <- data.frame(lon = -73.872611, lat = 40.77725)
# Berechne (direkte) Distanzen von Pickup/Dropoff zu JFK/Laguardia
test2$jfk_dist_pick <- distCosine(test2[,c("pickup_longitude","pickup_latitude")], jfk_coord)
test2$jfk_dist_drop <- distCosine(test2[,c("dropoff_longitude","dropoff_latitude")], jfk_coord)
test2$lg_dist_pick <- distCosine(test2[,c("pickup_longitude","pickup_latitude")], laguardia_coord)
test2$lg_dist_drop <- distCosine(test2[,c("dropoff_longitude","dropoff_latitude")], laguardia_coord)
# Feature Engineering für Testset
test2 <- test2 %>%
mutate(
jfk_trip = factor((jfk_dist_pick < 2e3) | (jfk_dist_drop < 2e3), levels = c(TRUE, FALSE), labels = c("yes","no")),
lg_trip = factor((lg_dist_pick < 2e3) | (lg_dist_drop < 2e3), levels = c(TRUE, FALSE), labels = c("yes","no")),
month = factor(lubridate::month(pickup_datetime, label = TRUE), ordered = FALSE),
wday = factor(lubridate::wday(pickup_datetime, label = TRUE, abbr = FALSE, week_start = 1), ordered = FALSE),
hour = lubridate::hour(pickup_datetime),
work = factor((hour %in% seq(8,18)) & (wday %in% c("Montag","Dienstag","Mittwoch","Donnerstag","Freitag")),
levels = c(TRUE, FALSE), labels = c("yes","no")),
has_snow = factor((snowfall > 0) | (snowdepth > 0), levels = c(TRUE, FALSE), labels = c("yes","no")),
has_rain = factor(precipitation > 0, levels = c(TRUE, FALSE), labels = c("yes","no")),
dist2 = dist^2,
dist3 = dist^3,
dist4 = dist^4
)
# DATA CLEANING Testset
test2 <- test2 %>%
mutate(
kmh = 3.6 * dist / trip_duration,
dropoff_time = format(dropoff_datetime, format = "%H:%M:%S")
) %>%
filter(dist > 0,
jfk_dist_pick < 3e5 & jfk_dist_drop < 3e5,
kmh >= 2.0 & kmh < 200,
dropoff_time != "00:00:00",
trip_duration >= 60)Nach diesem Code Block sollten die beiden Dataframes, train2 und test2, genau 35 Spalten bzw. Variablen haben. Bitte überprüfen Sie das kurz.
Train- und Testset vergleichen
Hier machen wir einen ganz kurzen Vergleich zwischen Trainings- und Testdatensatz. Warum machen wir das? Wenn die Testdaten völlig anders verteilt sind als die Trainingsdaten, dann wird die Messung der Vorhersagegüte auf dem Testset nicht sehr aussagekräftig sein. Bei so grossen Datensätzen wie hier ist das typischerweise kein Problem. Bei kleineren Datensätzen kann es aber vorkommen, dass Trainings- und Testdaten unterschiedliche Verteilungen (insbesondere für die Ouput-Variable) aufweisen.
# *****************************************************
# 3. Vergleich Train- und Testset ---------------------
# Verteilung Tripdauer in train und test
train2 %>%
select(trip_duration) %>%
mutate(id = "train") %>%
bind_rows(test2 %>% select(trip_duration) %>% mutate(id = "test")) %>%
ggplot(aes(x = trip_duration, fill = id)) +
geom_density(alpha = 0.7) +
scale_x_log10() +
theme_bw() +
theme(legend.title = element_blank())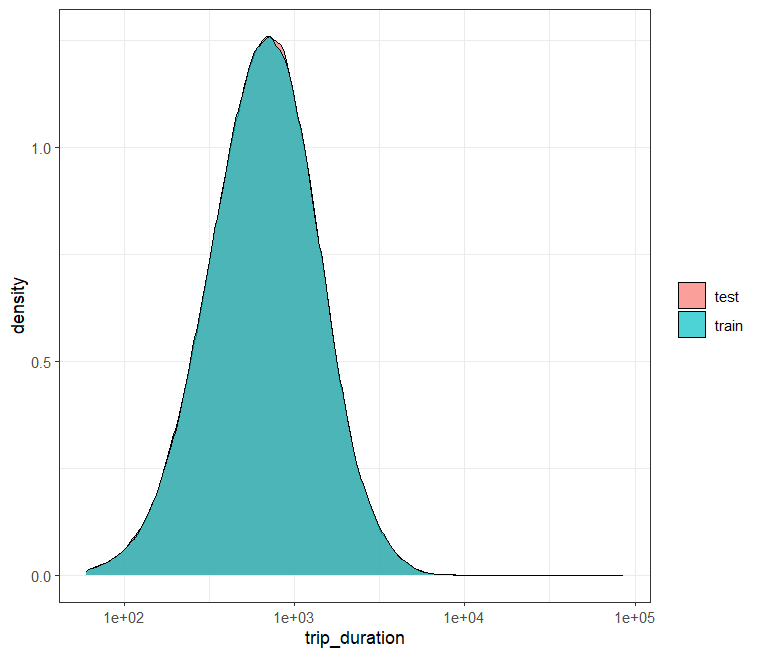
Wie bereits vermutet, sind die Verteilungen der Output-Variable trip_duration hier beinahe identisch.
# Anzahl Trips (Zeitreihe)
train2 %>%
select(pickup_datetime) %>%
mutate(id = "train", date = lubridate::date(pickup_datetime)) %>%
bind_rows(test2 %>% select(pickup_datetime) %>% mutate(id = "test", date = lubridate::date(pickup_datetime))) %>%
count(id, date) %>%
ggplot(aes(x = date, y = n, color = id)) +
geom_line(linewidth = 1.3) +
theme_bw() +
labs(x = NULL, y = "Anzahl Trips") +
theme(legend.title = element_blank())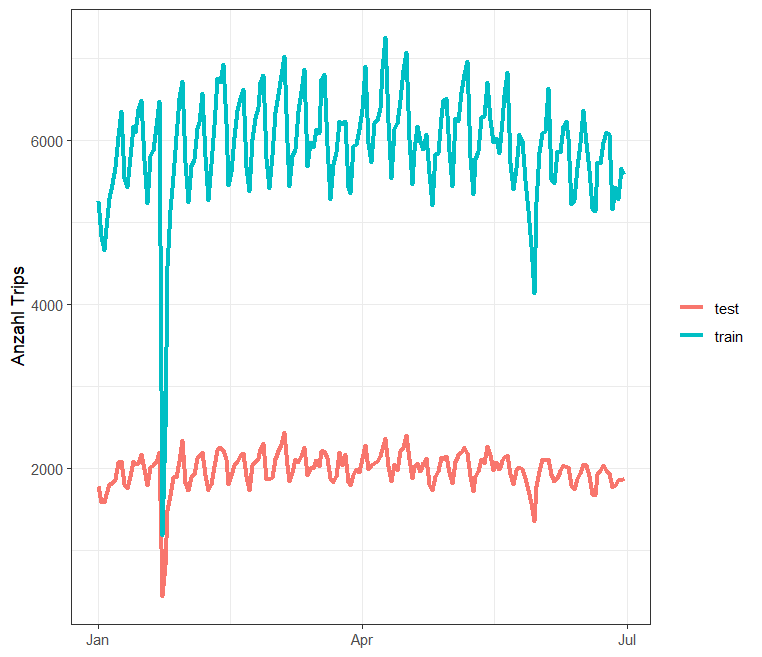
Auch die Häufigkeit der Trips über die 6 Monate sehen in beiden Datensätzen relativ ähnlich aus. Der Drop Ende Januar hatte mit einem grossen Wintersturm in New York zu tun.
Log-Transformation der Output Variable
Wir haben während der explorativen Analysen bereits gesehen, dass für fast alle Plots, welche die Output Variable trip_duration enthielten, eine Log-Transformation der entsprechenden Achsen Sinn machte. Die Plots haben gezeigt, dass die Log-Transformationen zu einer gewissen Linearisierung der Zusammenhänge führte.
Wir wollen diesen Sachverhalt auch für das Modellieren nutzen, denn wir werden weiter unten ein lineares Regressionsmodell schätzen, welches womöglich von dieser Linearisierung durch die Log-Transformation profitieren kann. Ausserdem reduziert die Log-Transformation den Einfluss von Ausreissern.
Im folgende Code Block führen wir die Log-Transformation (natürlicher Logarithmus, d.h. zur Basis \(e\)) für den Trainingsdatensatz durch.
# *****************************************************
# 4. Modelling ----------------------------------------
# Wir wenden eine Log-Transformation für die Output Variable an.
train2 <- train2 %>%
mutate(trip_duration = log(trip_duration))Wichtig: wir haben im Data Cleaning alle Beobachtungen mit einer trip_duration von 0 entfernt. Falls wir diesen Schritt nicht gemacht hätten, dann müssten wir die Outputvariable wie folgt transformieren: log(trip_duration + 1) (also überall eine Sekunde addieren). Warum? Wenn die trip_duration = 0 ist, dann wäre die Transformation log(0) mathematisch nicht definiert.
Recipes
Nun steigen wir so richtig in tidymodels ein. Wir haben zwar schon viel Preprocessing gemacht, doch bevor wir Modelle rechnen können, gibt es noch immer einige wichtige (kleinere) Preprocessing Schritte. Diese sind nicht für jedes Modell gleich, darum führen wir diese Schritte erst hier durch und passen sie spezifisch auf das zu rechnende Modell an. tidymodels erlaubt uns, diese Preprocessing Schritte in einem sogenannten recipe (dt. Rezept) zu definieren. Viele dieser letzten Preprocessing Schritte hängen mit den Datentypen der Variablen zusammen. Darum macht es Sinn, uns die Datentypen der Variablen nochmal zu vergegenwärtigen, z.B. mit der Funktion glimpse():
# Als erstes schauen wir uns nochmal die Datentypen der Spalten genau an.
glimpse(train2)Rows: 1,077,318
Columns: 35
$ id <chr> "id1134554", "id0486626", "id0774292", "id3925513", "id1684322", "id2172244"…
$ vendor_id <dbl> 2, 1, 2, 2, 2, 2, 1, 2, 1, 2, 2, 1, 1, 2, 2, 2, 2, 2, 2, 1, 2, 2, 1, 2, 2, 1…
$ pickup_datetime <dttm> 2016-06-20 22:56:10, 2016-04-04 13:25:16, 2016-03-04 01:03:49, 2016-04-11 1…
$ dropoff_datetime <dttm> 2016-06-20 23:08:53, 2016-04-04 13:32:18, 2016-03-04 01:14:50, 2016-04-11 1…
$ passenger_count <dbl> 1, 4, 1, 1, 2, 1, 1, 2, 1, 1, 2, 1, 1, 1, 1, 5, 1, 2, 1, 1, 5, 3, 1, 5, 1, 1…
$ pickup_longitude <dbl> -73.98231, -73.98820, -74.00070, -73.97545, -73.96726, -73.98531, -73.99786,…
$ pickup_latitude <dbl> 40.76826, 40.74594, 40.72970, 40.75371, 40.76026, 40.74969, 40.73615, 40.739…
$ dropoff_longitude <dbl> -73.98355, -74.00010, -73.98056, -73.97767, -73.96152, -73.99151, -73.98635,…
$ dropoff_latitude <dbl> 40.73889, 40.73305, 40.72719, 40.77701, 40.77625, 40.75221, 40.74336, 40.737…
$ store_and_fwd_flag <chr> "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "N", "…
$ trip_duration <dbl> 6.637258, 6.045005, 6.493754, 7.325149, 6.061457, 6.426488, 6.700731, 5.5721…
$ max_temp <dbl> 26.11, 4.44, 3.33, 14.44, 20.00, 19.44, 28.89, 12.78, 15.56, 16.11, 21.67, 1…
$ min_temp <dbl> 17.22, -1.67, -2.22, 7.22, 6.67, 16.11, 21.11, 0.00, 5.00, 3.89, 11.67, 5.00…
$ avg_temp <dbl> 21.67, 1.39, 0.56, 10.83, 13.33, 17.78, 25.00, 6.39, 10.28, 10.00, 16.67, 10…
$ precipitation <dbl> 0.00, 0.53, 0.01, 0.02, 0.00, 0.09, 0.01, 0.31, 0.01, 0.27, 0.01, 0.01, 1.05…
$ snowfall <dbl> 0.00, 0.10, 0.30, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00, 0.00…
$ snowdepth <dbl> 0.00, 0.00, 0.01, 0.00, 0.00, 0.00, 0.00, 0.01, 0.00, 0.00, 0.00, 0.00, 0.00…
$ dist <dbl> 3271.0630, 1751.1668, 1721.9489, 2600.5088, 1844.0294, 592.8638, 1259.5185, …
$ jfk_dist_pick <dbl> 22347.98, 21259.14, 21234.84, 20886.08, 20803.67, 21293.32, 21374.76, 20767.…
$ jfk_dist_drop <dbl> 20501.33, 21368.55, 19611.97, 22692.19, 21644.19, 21882.12, 20969.79, 21646.…
$ lg_dist_pick <dbl> 9301.706, 10350.810, 12028.896, 9057.738, 8200.885, 9985.418, 11509.993, 105…
$ lg_dist_drop <dbl> 10283.108, 11822.888, 10673.610, 8856.128, 7495.444, 10404.972, 10305.809, 1…
$ jfk_trip <fct> no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, …
$ lg_trip <fct> no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, no, …
$ month <fct> Jun, Apr, Mär, Apr, Apr, Jun, Jun, Feb, Mär, Feb, Apr, Mär, Feb, Jun, Mai, M…
$ wday <fct> Montag, Montag, Freitag, Montag, Donnerstag, Freitag, Mittwoch, Dienstag, Do…
$ hour <int> 22, 13, 1, 17, 8, 11, 13, 23, 21, 21, 20, 17, 12, 11, 4, 23, 9, 14, 19, 5, 1…
$ work <fct> no, yes, no, yes, yes, yes, yes, no, no, no, no, yes, yes, yes, no, no, no, …
$ has_snow <fct> no, yes, yes, no, no, no, no, yes, no, no, no, no, no, no, no, no, no, no, n…
$ has_rain <fct> no, yes, yes, yes, no, yes, yes, yes, yes, yes, yes, yes, yes, no, yes, yes,…
$ dist2 <dbl> 10699853.2, 3066585.3, 2965108.0, 6762646.0, 3400444.4, 351487.5, 1586386.8,…
$ dist3 <dbl> 3.499989e+10, 5.370103e+09, 5.105764e+09, 1.758632e+10, 6.270520e+09, 2.0838…
$ dist4 <dbl> 1.144869e+14, 9.403946e+12, 8.791866e+12, 4.573338e+13, 1.156302e+13, 1.2354…
$ kmh <dbl> 15.433587, 14.938864, 9.378239, 6.167215, 15.474373, 3.453576, 5.577204, 15.…
$ dropoff_time <chr> "23:08:53", "13:32:18", "01:14:50", "18:13:40", "09:00:18", "11:37:43", "13:…Basierend auf dem Überblick über die Variablen bzw. deren Datentypen ergibt sich folgender Preprocessing-Bedarf:
- Gewisse Variablen wollen wir nicht in das Modell nehmen, weil sie i) keine Information enthalten (
id) oder ii) nicht als Feature taugen, da falscher Datentyp (pickup_datetime) oder iii) in einem produktiven System gar nicht zur Verfügung stehen würden (dropoff_datetime). Wenn wir diese Variablen trotzdem behalten möchten, dann können wir ihnen mit der Funktionupdate_role()die Rolle als"ID"Variablen zuweisen. - Wenn wir Variablen ganz entfernen wollen, dann können wir das mit der Funktion
step_rm()tun. Wir entfernen z.B. die Variablekmh, da sie in einem produktiven System nicht zur Verfügung steht. - Die Variable
vendor_idist aktuell numerisch kodiert (dbl). Eigentlich handelt es sich aber um einen Faktor, da es hier ja nur zwei Möglichkeiten gibt,1oder2. Mit der Funktionstep_num2factor()können wir die Variable in einen Faktor transformieren. - Wir werden später ein lineares Modell mit Regularisierung (LASSO) rechnen. Dieses erfordert, dass alle Variablen numerisch sind. Darum müssen wir in einem nächsten Schritt ein One-Hot-Encoding durchführen (siehe Infobox unten). Mit
tidymodelsgeht das ganz einfach. Sie verwenden die Funktionstep_dummy()und selektieren mitall_nominal_predictors()alle Variablen, die entweder den Datentypfct(Faktor) oderchraufweisen. - Bei kleineren Datensätzen kommt es manchmal vor, dass ein Faktorlevel im Trainingsdatensatz nicht existiert. Durch das One-Hot-Encoding kann es dadurch zu Dummy Variablen kommen, die immer den Wert 0 annehmen. Solche Variablen haben eine Varianz von 0 (zero-variance) und sollten vor der Modellierung entfernt werden. Dazu können wir die Funktion
step_zv()auf alle Variablen anwenden. Im Beispiel hier tritt dieses Problem nicht auf, wir behalten den Schritt trotzdem imrecipe. - Ganz zum Schluss standardisieren bzw. normalisieren wir alle numerischen Variablen mit
step_normalize()(siehe übernächste Infobox unten).
One-Hot Encoding
Beim One-Hot Encoding geht es darum eine kategorische Variable in numerische Werte zu überführen, die ein Modell verstehen kann. Dazu wird für jede mögliche Kategorie einer kategorischen Variable eine Dummy Variable gebildet, die nur dann den Wert 1 annimmt, falls die Beobachtung der gegebenen Kategorie angehört und sonst den Wert 0 annimmt.
Beispiel: Die Variable wday hat 7 mögliche Kategorien (die Wochentage). D.h. ein One-Hot Encoding dieser Variable erfordert 7 Dummy-Variablen. Stellen Sie sich vor, wir haben drei Taxi-Trip Beobachtungen, zwei an einem Montag und eine an einem Donnerstag. Wie sehen diese drei Beobachtungen one-hot-encoded aus?
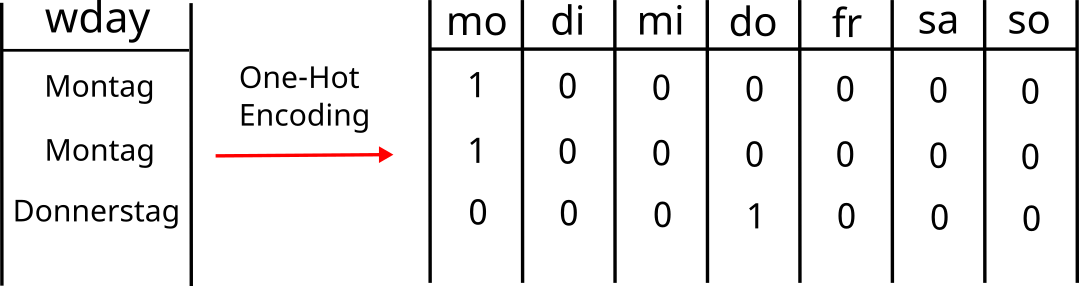
Sie werden weiter unten im Code sehen, dass wir one_hot = TRUE setzen in der step_dummy() Funktion. Damit stellen wir sicher, dass für jedes mögliche Level eine Dummy Variable gebildet wird. Mit one_hot = FALSE wird für ein Referenlevel jeweils keine Dummy Variable gebildet. Wer bei mir EMBA hatte, erinnert sich vielleicht noch an diese Konzepte. Wichtig: für das lineare Regressionsmodell, das wir hier anwenden werden, benötigen wir kein Referenzlevel!
Warum standardisieren wir numerische Variablen?
Der Wertebereich von numerischen Variablen kann stark unterschiedlich sein. Der Wertebereich für die Variable passenger_count reicht beispielsweise von 0 bis 6, während der Wertebereich für die Variable dist (Distanz in Meter) von 0.64 bis 173’000 reicht. Die meisten ML-Modelle bzw. deren Training funktioniert besser, wenn die Wertebereiche der numerischen Variablen ähnlich sind. Bei der regularisierten Regression ist dieser Schritt besonders wichtig, da wir die Parameter des Modells regularisieren. Wenn wir die Variablen nicht standardisieren, dann nehmen die geschätzten Parameter des Modells stark unterschiedliche Werte an und die Regularisierung funktioniert nicht korrekt.
Wir standardisieren die numerischen Variablen so, dass der Mittelwert jeweils 0 ist und die Standardabweichung 1. Die entsprechende Berechnung haben Sie bereits in Statistik 1/2 kennen gelernt (z-Werte oder z-Scores):
\[ x' = \frac{x - \bar{x}}{\sigma_x} \]
Wir nehmen also die ursprünglichen Werte, ziehen den Mittelwert ab und dividieren durch die Standardabweichung. Es gibt andere Normalisierungsmethoden wie z.B. Min-Max-Normalisierung, welche alle Werte einer Variable in den Bereich \([0,1]\) “drückt”.
Nun erstellen wir das recipe. Der erste Schritt definiert die Modellformel, die wir dem Modell übergeben werden. trip_duration ~ . legt die Output-Variable fest und definiert, dass alle anderen Variablen (ausser die, welche im recipe entfernt oder mit einer neuen Rolle versehen werden) als Features verwendet werden sollen.
# Nun schreiben wir ein so genanntes 'recipe', um die Daten vorzubereiten.
trips_rec <-
# Modellformel (trip_duration ist unsere Outputvariable)
recipe(trip_duration ~ ., data = train2) %>%
# 'id', 'pickup_datetime' und 'dropoff_datetime' sollen nicht als Features
# verwendet werden. Wir behalten sie aber als ID Variablen.
update_role(id, pickup_datetime, dropoff_datetime, new_role = "ID") %>%
# Die Distanzen zu den Flughäfen werden entfernt.
step_rm(jfk_dist_pick, jfk_dist_drop, lg_dist_pick, lg_dist_drop, kmh, dropoff_time) %>%
# 'vendor_id' ist aktuell noch numerisch, doch wir wollen die Variable als Faktor behandeln.
step_num2factor(vendor_id, levels = c("V1", "V2")) %>%
# Alle 'character', 'factor' oder 'logical' Spalten werden one-hot-encoded.
step_dummy(all_nominal_predictors(), one_hot = TRUE) %>%
# Entfernt 'zero-variance' Variablen.
step_zv(all_predictors()) %>%
# Standardisiert alle numerischen Variablen.
step_normalize(all_predictors())Nun haben wir das recipe definiert. Wir können uns kurz eine Zusammenfassung des recipe ausgeben lassen:
# Zusammenfassung des 'recipe'
summary(trips_rec) %>%
print(n = 40)# A tibble: 35 × 4
variable type role source
<chr> <list> <chr> <chr>
1 id <chr [3]> ID original
2 vendor_id <chr [2]> predictor original
3 pickup_datetime <chr [1]> ID original
4 dropoff_datetime <chr [1]> ID original
5 passenger_count <chr [2]> predictor original
6 pickup_longitude <chr [2]> predictor original
7 pickup_latitude <chr [2]> predictor original
8 dropoff_longitude <chr [2]> predictor original
9 dropoff_latitude <chr [2]> predictor original
10 store_and_fwd_flag <chr [3]> predictor original
11 max_temp <chr [2]> predictor original
12 min_temp <chr [2]> predictor original
13 avg_temp <chr [2]> predictor original
14 precipitation <chr [2]> predictor original
15 snowfall <chr [2]> predictor original
16 snowdepth <chr [2]> predictor original
17 dist <chr [2]> predictor original
18 jfk_dist_pick <chr [2]> predictor original
19 jfk_dist_drop <chr [2]> predictor original
20 lg_dist_pick <chr [2]> predictor original
21 lg_dist_drop <chr [2]> predictor original
22 jfk_trip <chr [3]> predictor original
23 lg_trip <chr [3]> predictor original
24 month <chr [3]> predictor original
25 wday <chr [3]> predictor original
26 hour <chr [2]> predictor original
27 work <chr [3]> predictor original
28 has_snow <chr [3]> predictor original
29 has_rain <chr [3]> predictor original
30 dist2 <chr [2]> predictor original
31 dist3 <chr [2]> predictor original
32 dist4 <chr [2]> predictor original
33 kmh <chr [2]> predictor original
34 dropoff_time <chr [3]> predictor original
35 trip_duration <chr [2]> outcome originalDer einzige interessante Aspekt an obigem Output ist die Spalte role, mit welcher Sie überprüfen können, ob alle Variable die korrekte Rolle haben.
Wichtig: gerechnet wurde bisher noch nichts. Das recipe wird in einem ersten Schritt (weiter unten) auf dem Trainingsdatensatz angewendet. Dabei werden auch gewisse Grössen abgespeichert, z.B. die Mittelwerte und Standardabweichungen, welche für die Standardisierung der numerischen Variablen verwendet werden. Später werden wir das recipe auch auf dem Testdatensatz anwenden. Dabei werden für die Standardisierung der numerischen Variablen im Testdatensatz die gespeicherten Grössen aus dem Trainingsdatensatz verwendet. Das ist wichtig, denn auch für die Standardisierung von Variablen wollen wir nicht gelernte Grössen aus dem Testdatensatz verwenden.
Das oben definierte recipe wurde spezifisch erstellt für das lineare Regressionsmodell, das wir später rechnen werden. Falls wir zum Beispiel einen Entscheidungsbaum (Details dazu in einer späteren Lektion) rechnen würden, dann würde das recipe anders aussehen. Das One-Hot-Encoding wäre zum Beispiel in diesem Fall nicht nötig, da Entscheidungsbäume mit Faktorvariablen umgehen können.
Resampling und Validation Set
Das Thema Resampling ist enorm wichtig im Machine Learning. Wir verwenden Resampling Methoden für zwei Aspekte während der Modellierung.
Einerseits erlaubt uns das Resampling die optimalen Hyperparameter eines Modells zu finden. Wir werden unten ein regularisiertes Regressionsmodell (LASSO) rechnen, für welches der optimale Hyperparameter \(\lambda\) gefunden werden muss.
Andererseits können wir mithilfe des Resamplings zwischen verschiedenen Modellen entscheiden. Wenn wir zum Beispiel ein lineares Regressionsmodell und einen Entscheidungsbaum trainiert haben, dann können wir schauen, welches der beiden Modelle die bessere Resampling-Performance hat, ohne dass wir bereits auf das Testset zurückgreifen müssen.
Wir können aber auch verschiedene Preprocessing Varianten ausprobieren und schauen, welche Variante zu einer besseren Resampling-Performance führt. Wir könnten beispielsweise überprüfen, ob es besser ist die numerischen Variablen zu standardisieren oder die Min-Max-Normalisierung anzuwenden.
Was sind Hyperparameter?
Ein Hyperparameter ist kein eigentlicher Modellparameter, denn er wird nicht während der Trainingsphase (Fitting) gelernt, sondern muss vor der Trainingsphase gesetzt werden. Mit Resampling-Methoden wie etwa K-Fold Cross Validation versuchen wir, einen möglichst optimalen Wert für den Hyperparameter zu finden.
Beispiel: Bei der regularisierten Regression (Ridge und LASSO) haben wir die Modellparameter \(w_0, w_1, w_2, \dots\). Zusätzlich haben wir einen Hyperparameter \(\lambda\), der bestimmt, wie stark regularisiert wird. Während \(\lambda\) vor dem Training des Modells gesetzt werden muss, werden die Modellparameter während des Trainings gelernt bzw. optimiert.
Die bekannteste Resampling-Methode ist K-Fold Cross-Validation. Wie funktioniert diese Methode:
- Wir teilen den Trainingsdatensatz in \(K\) (z.B. \(K=5\)) gleich grosse Teile (Folds) auf.
- Wir legen den ersten Fold zur Seite und trainieren das Modell auf den restlichen 4 Folds.
- Dann verwenden wir das in Schritt 2 trainierte Modell, um Vorhersagen für die Beobachtungen im ersten (Test-) Fold zu rechnen, der ja nicht für das Training verwendet wurde. Wir vergleichen die Vorhersagen mit den wahren Werten mithilfe eines Modellgütemasses (z.B. RMSE) und speichern den entsprechenden RMSE Wert.
- Wir wiederholen die Schritte 2. und 3. und legen jeweils einen anderen Fold zur Seite für die Evaluation des Modells.
- Wir haben am Schluss \(K\) RMSE-Werte. Diese \(K\) Werte können wir mitteln, um die Vorhersagegüte eines Modells zu schätzen. Mit den \(K\) RMSE-Werten können wir auch eine Varianz schätzen, um die Unsicherheit unserer Schätzung zu beziffern.
Folgende Abbildung stellt 5-Fold Cross Validation grafisch dar:

Sie sehen vielleicht jetzt auch, warum wir von Resampling sprechen. Wir samplen nämlich mehrere kleine Validierungsdatensätze (Folds) aus dem Trainingsdatensatz, um eine Schätzung für die Modellgüte zu erhalten.
Wie können wir nun damit den optimalen Hyperparameter (z.B. \(\lambda\)) finden? Wir führen für jeden möglichen Wert, den der Hyperparameter annehmen kann, die K-Fold Cross-Validation durch und kriegen dementsprechend für jeden möglichen Hyperparameterwert eine Schätzung der Modellgüte. Am Schluss wählen wir ganz einfach den Hyperparameterwert, der zur besten (geschätzten) Modellgüte führt! Wenn wir den optimalen Hyperparameterwert gefunden haben, dann trainieren wir das Modell ein letztes Mal auf dem ganzen Trainingsdatensatz, d.h. ohne Cross-Validation (mit dem optimalen Hyperparameterwert).
Wenn wir einen besonders grossen Datensatz haben (was hier der Fall ist), dann können wir auch einfach ein Validation Set bilden anstatt K-Fold Cross-Validation durchzuführen. D.h. wir splitten den Trainingsdatensatz in ein Validation Set und in einen kleineren Trainingsdatensatz. Der Vorteil von einem Validation Set im Vergleich zu K-Fold Cross-Validation ist, dass es weniger rechenintensiv ist. Warum? Wenn wir 5 mögliche Hyperparameterwerte haben, dann müssen wir im Falle eines Validation Sets nur 5 Mal ein Modell rechnen und evaluieren. Wie sieht es im Falle der 5-Fold Cross-Validation aus?
Gehen wir nun zurück zu unserem Beispiel. Wir verwenden hier die Validation Set Methode und splitten darum den Trainingsdatensatz nochmals auf. 20% für das Validation Set, die restlichen 80% für das Trainieren der Modelle. Um den Split reproduzierbar zu machen, setzen wir einen Seed.
# Seed für Reproduzierbarkeit des Validationsets
set.seed(123)
# Training- vs. Validationset
val_set <- validation_split(train2, prop = 0.80)
# Wie sieht Split aus?
val_set# Validation Set Split (0.8/0.2)
# A tibble: 1 × 2
splits id
<list> <chr>
1 <split [861854/215464]> validationWichtiges Takeaway: wir evaluieren ein Modell nie einfach nur auf dem Trainingsdatensatz. Wir wenden immer eine Form von Resampling an, um die Modellgüte zu schätzen und/oder um die Hyperparameter zu optimieren.
Modell rechnen und Hyperparameter Tuning
In einem ersten Schritt spezifizieren wir hier nun das Modell, das wir rechnen wollen. Wir haben uns für ein relativ simples lineares Regressionsmodell entschieden. Wir spezifizieren dieses Modell mit der Funktion linear_reg(). Weil wir sehr viele (potenziell stark korrelierte) Variablen haben, wollen wir aber ein regularisiertes Modell rechnen. Dies legen wir mithilfe von set_engine("glmnet") fest (so wird im Hintergrund das glmnet Package verwendet). Wichtig sind im folgenden Code Block die Argumente penalty = tune() und mixture = tune(). Diese legen fest, dass wir die beiden Hyperparameter penalty (entspricht \(\lambda\)) und mixture (bestimmt, ob wir ein Ridge oder LASSO Modell wählen) tunen wollen.
# Modellspezifikation für lineares Modell mit Regularisierung
lm_mod <-
linear_reg(penalty = tune(), mixture = tune()) %>%
set_engine("glmnet")Nun setzen wir einen tidymodels-Worklow auf und fügen das oben spezifizierte Modell mit add_model(lm_mod) dem Workflow hinzu. Mit add_recipe(trips_rec) fügen wir das weiter oben definierte recipe ebenfalls dem Workflow hinzu:
# Workflow aufsetzen
lm_wflow <-
workflow() %>%
add_model(lm_mod) %>%
add_recipe(trips_rec)Nun wird es spannend! Wir tunen unsere zwei Hyperparameter. Mit expand.grid() erstellen wir einen Grid von möglichen Werten für penalty und mixture. Für penalty testen wir die Werte \({0.00001, 0.0001, 0.001, 0.01, 0.1, 1, 10, 100, 1000}\) und für mixture die Werte 0 (entspricht Ridge) und 1 (entspricht LASSO).
Die Funktion tune_grid() führt das Tuning durch. Wir übergeben der Funktion das Objekt val_set, das den Validation Set Split definiert sowie den Grid mit möglichen Hyperparameterwerten. Mit control = control_grid(save_pred = TRUE) sagen wir der Funktion, dass alle Resampling-Resultate (d.h. die Vorhersagen auf dem Validierungsdatensatz) gespeichert werden sollen. Schliesslich definieren wir die zu verwendenden Modellgütemasse, nämlich den RMSE und den MAE. Die Ausführung des Codes in folgendem Code Block dauert ein paar Minuten.
# Grid mit möglichen Hyperparameter Werten
lm_reg_grid <- expand.grid(penalty = 10^seq(-5, 3, by = 1), mixture = c(0, 1))
# Tuning / Fitting
lm_res <-
lm_wflow %>%
tune_grid(val_set,
grid = lm_reg_grid,
control = control_grid(save_pred = TRUE),
metrics = metric_set(rmse, mae))Folgender Code erlaubt uns, die Resultate des Tunings anzuschauen:
# Resultate des Tunings
lm_res %>%
collect_metrics() %>%
filter(.metric == "rmse") %>%
arrange(mean)# A tibble: 18 × 8
penalty mixture .metric .estimator mean n std_err .config
<dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
1 0.001 1 rmse standard 0.435 1 NA Preprocessor1_Model12
2 0.0001 1 rmse standard 0.444 1 NA Preprocessor1_Model11
3 0.00001 1 rmse standard 0.444 1 NA Preprocessor1_Model10
4 0.01 1 rmse standard 0.463 1 NA Preprocessor1_Model13
5 0.00001 0 rmse standard 0.482 1 NA Preprocessor1_Model01
6 0.0001 0 rmse standard 0.482 1 NA Preprocessor1_Model02
7 0.001 0 rmse standard 0.482 1 NA Preprocessor1_Model03
8 0.01 0 rmse standard 0.482 1 NA Preprocessor1_Model04
9 0.1 0 rmse standard 0.502 1 NA Preprocessor1_Model05
10 0.1 1 rmse standard 0.550 1 NA Preprocessor1_Model14
11 1 0 rmse standard 0.591 1 NA Preprocessor1_Model06
12 10 0 rmse standard 0.684 1 NA Preprocessor1_Model07
13 100 0 rmse standard 0.722 1 NA Preprocessor1_Model08
14 1000 0 rmse standard 0.727 1 NA Preprocessor1_Model09
15 1 1 rmse standard 0.727 1 NA Preprocessor1_Model15
16 10 1 rmse standard 0.727 1 NA Preprocessor1_Model16
17 100 1 rmse standard 0.727 1 NA Preprocessor1_Model17
18 1000 1 rmse standard 0.727 1 NA Preprocessor1_Model18Frage: Warum haben wir im obigen Output keinen Standardfehler sondern nur NA Werte?
Am besten plotten wir die Resultate doch gleich:
# Plot der Resultate
lm_res %>%
collect_metrics() %>%
ggplot(aes(x = penalty, y = mean, color = .metric, linetype = factor(mixture))) +
geom_point() +
geom_line() +
labs(x = "Penalty", y = "Modellgüte") +
scale_x_log10() +
theme_bw()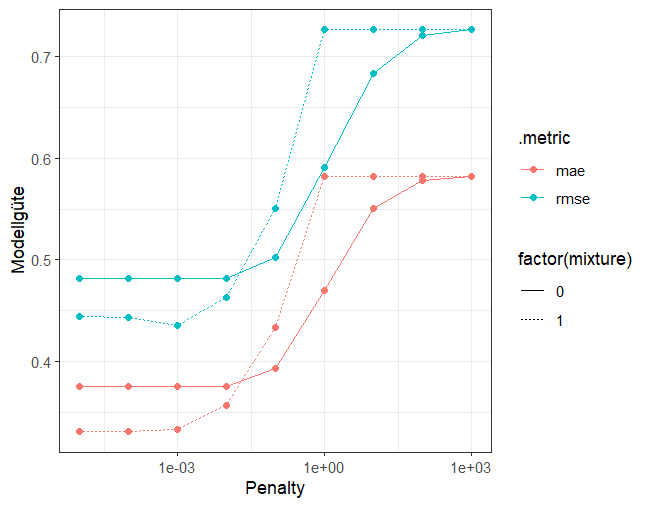
Wenn wir uns nur die blauen Kurven (RMSE) anschauen, dann sehen wir, dass der kleinste Fehler mit mixture = 1 (also LASSO) und penalty = 0.001 erreicht wird. Das sind also die optimalen Hyperparameterwerte.
Mit der Funktion select_best() können wir nun automatisch das beste Modell aus den Tuning Resultaten auswählen.
# Wir wählen das beste Modell
lm_best <-
lm_res %>%
select_best(metric = "rmse")
lm_best# A tibble: 1 × 3
penalty mixture .config
<dbl> <dbl> <chr>
1 0.001 1 Preprocessor1_Model12Nun macht es Sinn, noch kurz die wahren Output Werte gegen die Vorhersagen zu plotten (in einem Streudiagramm). Dazu holen wir uns mit collect_predictions(parameters = lm_best) die Vorhersagen unseres optimalen Modells auf dem Validierungsdatensatz.
# Plot: Vorhersage vs. effektive Dauer des Trips
lm_res %>%
collect_predictions(parameters = lm_best) %>%
sample_n(1e4) %>%
ggplot(aes(x = trip_duration, y = .pred)) +
geom_point(color = "orchid1", alpha = 0.3) +
geom_abline(intercept = 0, slope = 1) +
theme_bw()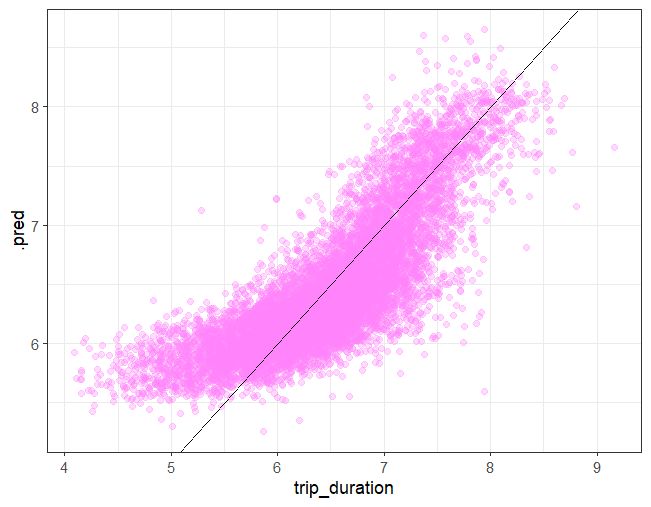
Gut wäre es, wenn die Punkte im Streudiagramm etwas um die schwarze Gerade (45 Grad) streuen würden. Das ist leider im unteren Teil des Diagramms mit kleineren log(trip_duration) Werten von 4 bis etwa 6 nicht der Fall (6 entspricht einer trip_duration von \(exp(6) = 403s\) oder knapp 7 Minuten). Dort scheint das Modell die Durations systematisch zu überschätzen (d.h. die Vorhersagen sind systematisch über den wahren Werten).
Nun macht es Sinn, auch noch kurz die Residuen (Fehler) gegen die Vorhersagen zu plotten (klassischer Residuenplot).
# Analyse der Residuen
lm_res %>%
collect_predictions(parameters = lm_best) %>%
mutate(resid = trip_duration - .pred) %>%
sample_n(1e4) %>%
ggplot(aes(x = .pred, y = resid)) +
geom_point(color = "orchid1", alpha = 0.3) +
theme_bw()
Auch hier sieht es leider nicht genau so aus, wie es sollte, nämlich eine zufällige Streuung der Punkte um die Horizontale auf der Höhe von 0.
Ich würde mir an dieser Stelle nun die Beobachtungen im Trainingsdatensatz mit besonders grossen (absoluten) Residuen sowie besonders kurze Trips mal genauer anschauen. Vielleicht ergeben sich so Ideen für ein weiteres Feature Engineering.
Last Fit
Nun wollen wir das Modell noch ein letztes Mal rechnen, und zwar auf dem ganzen Trainingsdatensatz und mit den gewählten optimalen Werten für die Hyperparameter. Als erstes spezifizieren wir das Modell. Wir setzen nun anstelle von tune() die optimalen Werte ein:
# Last Fit Spezifikation (optimale Hyperparameter Werte)
last_lm_mod <-
linear_reg(penalty = 0.001, mixture = 1.0) %>%
set_engine("glmnet")Dann aktualisieren wir den Workflow mit update_model():
# Workflow anpassen (optimales Modell)
last_lm_wflow <-
lm_wflow %>%
update_model(last_lm_mod)Und nun machen wir den Last Fit:
# Last Fit (auf ganzem Trainingsdatensatz)
last_lm_fit <-
last_lm_wflow %>%
fit(data = train2)Schauen wir uns doch noch kurz die geschätzten Parameter an:
# Parameter Last Fit
last_lm_fit %>%
extract_fit_parsnip() %>%
tidy() %>%
print(n = 50)# A tibble: 44 × 3
term estimate penalty
<chr> <dbl> <dbl>
1 (Intercept) 6.48e+ 0 0.001
2 passenger_count 4.67e- 3 0.001
3 pickup_longitude -3.45e- 2 0.001
4 pickup_latitude -9.95e- 3 0.001
5 dropoff_longitude -4.29e- 2 0.001
6 dropoff_latitude -2.83e- 2 0.001
7 max_temp 0 0.001
8 min_temp 7.98e- 3 0.001
9 avg_temp 6.22e- 4 0.001
10 precipitation 0 0.001
11 snowfall -2.98e- 3 0.001
12 snowdepth 1.80e- 2 0.001
13 dist 1.36e+ 0 0.001
14 hour 5.50e- 2 0.001
15 dist2 -1.40e+ 0 0.001
16 dist3 1.62e+ 0 0.001
17 dist4 -9.20e- 1 0.001
18 vendor_id_V1 0 0.001
19 vendor_id_V2 0 0.001
20 store_and_fwd_flag_N -3.09e- 5 0.001
21 store_and_fwd_flag_Y 0 0.001
22 jfk_trip_yes -4.60e- 4 0.001
23 jfk_trip_no 3.87e-10 0.001
24 lg_trip_yes -3.57e- 2 0.001
25 lg_trip_no 0 0.001
26 month_Jan -1.96e- 2 0.001
27 month_Feb -1.89e- 2 0.001
28 month_Mär -1.24e- 2 0.001
29 month_Apr 0 0.001
30 month_Mai 3.76e- 3 0.001
31 month_Jun 2.86e- 3 0.001
32 wday_Montag -3.60e- 2 0.001
33 wday_Dienstag -7.25e- 3 0.001
34 wday_Mittwoch 7.63e- 4 0.001
35 wday_Donnerstag 4.12e- 3 0.001
36 wday_Freitag 0 0.001
37 wday_Samstag 2.66e- 2 0.001
38 wday_Sonntag -1.15e- 3 0.001
39 work_yes 1.60e- 1 0.001
40 work_no 0 0.001
41 has_snow_yes 3.06e- 3 0.001
42 has_snow_no -5.83e-12 0.001
43 has_rain_yes -1.37e- 3 0.001
44 has_rain_no 1.62e-12 0.001Wir sehen in obigem Output, dass wie erwartet einige Parameter im LASSO Modell auf 0 gesetzt werden, weil die entsprechenden Variablen (z.B. max_temp) keinen substantiellen Beitrag zur Modellgüte liefern.
Variable Importance
Nun möchten wir ja noch wissen, welche Features (bzw. Variablen) wichtig sind für die Vorhersagen. Das ist bei linearen Regressionsproblemen ziemlich einfach. Wir schauen uns einfach die geschätzten Parameter an. Bei anderen ML-Methoden werden wir andere Methoden zur Messung der Variable Importance kennen lernen.
Plotten wir doch alle Parameter, die relevant sind als Barplot:
# *****************************************************
# 5. Variable Importance ------------------------------
# Barplot der Parameter
last_lm_fit %>%
extract_fit_parsnip() %>%
tidy() %>%
filter(abs(estimate) > 1e-3 & term != "(Intercept)") %>%
mutate(pos = estimate >= 0) %>%
arrange(desc(estimate)) %>%
ggplot(aes(x = reorder(term, estimate, sort), y = estimate, fill = pos)) +
geom_bar(stat = "identity") +
coord_flip() +
labs(x = NULL, y = "Stärke des Koeffizienten") +
guides(fill = "none") +
theme_bw()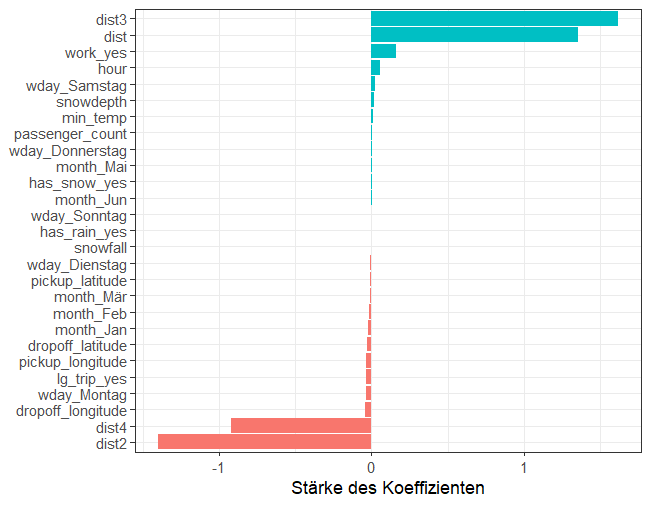
Die Variable dist und die polynomischen Features davon haben ganz klar den stärksten Effekt auf die Vorhersagen. Wichtig: die negativen Koeffizienten für dist2 und dist4 sind nicht als negativer Effekt von dist auf trip_duration zu deuten. Das Modell hat hier eine komplexe, aber insgesamt positive Beziehung zwischen der Distanz und der Tripdauer geschätzt.
Testset Performance
Wir haben nun unser finales Modell. Jetzt interessiert uns natürlich, wie gut das Modell auf dem bisher nicht angefassten Testdatensatz abschneidet. Das wird auch eine Schätzung sein darüber, wie gut das Modell “in the wild” performt, also in einem produktiven System.
# *****************************************************
# 6. Testset Performance ------------------------------
# Vorhersagegüte Lineares Modell (Train)
train2 %>%
select(trip_duration) %>%
bind_cols(predict(last_lm_fit, train2)) %>%
multi_metric(trip_duration, .pred)
# Vorhersagegüte Lineares Modell (Test)
test2 %>%
select(trip_duration) %>%
# Achtung: hier müssen wir zuerst noch die Output Variable im Testset logarithmieren.
mutate(trip_duration = log(trip_duration)) %>%
bind_cols(predict(last_lm_fit, test2)) %>%
multi_metric(trip_duration, .pred)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.433
2 mae standard 0.334
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.433
2 mae standard 0.335Wie Sie oben sehen, rechnen wir der Vollständigkeit halber auch den RMSE und MAE auf dem Traingsdatensatz. Wie oben erwähnt sind die Fehler auf dem Trainingsdatensatz aber nicht wirklich aussagekräftig.
Auf dem Testdatensatz finden wir einen RMSE von 0.433. Auf dem Trainingsdatensatz finden wir interessanterweise genau den gleichen Wert. Das ist untypisch, aber hier ist das so, weil die Datensätze so gross sind. Die wichtigste Nachricht hier ist aber folgende: weil die Werte auf Trainings- und Testdatensatz gleich (oder für den MAE sehr ähnlich) sind, haben wir kein Overfitting betrieben.
Falls der RMSE auf dem Trainingsdatensatz substanziell kleiner wäre als auf dem Testdatensatz, dann wäre das ein klares Indiz für Overfitting. Neben der eigentlichen Regularisierung hat hier die schiere Grösse des Trainingsdatensatzes einen stark regulierenden Einfluss.
Die grosse Frage ist jetzt aber: ist ein RMSE von 0.433 gut oder nicht? Dafür wäre es natürlich gut, wenn wir eine Benchmark Performance hätten, z.B. die Performance einer Vorgänger-Lösung für das Vorhersageproblem. Ein guter Benchmark kann auch das simple Modell sein, das für jeden Trip den Durchschnitt der Output Variable, gemessen auf dem Trainingsdatensatz, vorhersagt. Rechnen wir doch die Performance dieses einfachen Modells:
# Vorhersagegüte Baseline (Train)
train2 %>%
select(trip_duration) %>%
mutate(.pred = mean(train2$trip_duration)) %>%
multi_metric(trip_duration, .pred)
# Vorhersagegüte Baseline (Test)
test2 %>%
select(trip_duration) %>%
# Auch hier logarithmieren wir die Output Variable im Testset "on the fly".
mutate(trip_duration = log(trip_duration),
.pred = mean(train2$trip_duration)) %>%
multi_metric(trip_duration, .pred)# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.728
2 mae standard 0.582
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 rmse standard 0.728
2 mae standard 0.582Der Benchmark hat auf dem Testdatensatz einen Fehler (RMSE) von 0.728. Wow! Unser regularisiertes lineares Modell kann den Fehler im Vergleich zum Benchmark um rund 40% reduzieren (\((0.433 - 0.728) / 0.728=-0.41\)).
Finales Modell speichern
Schlussendlich speichern wir das finale Modell in einer Form, die uns ein Deployment des Modells erlaubt. Dazu verwenden wir das R-Package vetiver (Link). Wie man ein Modell deployen kann, werden wir uns zu einem späteren Zeitpunkt anschauen.
# *****************************************************
# 6. Modell speichern ---------------------------------
# Mit dem R-Package vetiver können wir unser finales Modell
# in einer Form speichern, so dass es parat ist für das Deployment.
final_model <- vetiver_model(last_lm_fit, "last_lm_fit")
# Was für ein Objekt ist es?
final_model
# Wir speichern das Objekt anschliessend als RDS File.
# Das braucht VIEL Speicherplatz!
# write_rds(final_model, "zwischenresultate/final_model.rds")── last_lm_fit ─ <bundled_workflow> model for deployment
A glmnet regression modeling workflow using 31 featuresHier können Sie nun das vollständige R-Skript in Ihr lokales Projekt übernehmen:
What now?
Wir haben uns nun bereits intensiv mit dem Problem und den Daten auseinander gesetzt. Ausserdem haben wir ein Modell gerechnet, das den Fehler beinahe halbieren kann im Vergleich zur Baseline (Durchschnitt aus dem Trainingsdatensatz als Vorhersage). Was nun? Sind wir nun fertig? Nein, leider nicht. In diesem Abschnitt schauen wir uns an, was als nächstes gemacht würde.
Was tun, wenn wir ein schlechtes Modell haben?
Schlechte Vorhersagen eines ML-Modells können auf zwei Gründe zurück geführt werden: entweder wurde ein schlechtes Modell gewählt oder die Trainingsdaten sind schlecht (siehe auch Seiten 27 - 33 in Géron (2022)). Wir gehen in den folgenden Abschnitten etwas genauer auf diese beiden Gründe ein.
Schlechte Daten
Für den Erfolg eines ML-Projekts ist es äusserst wichtig, dass Sie eine ausreichende Anzahl an Trainingsdaten zur Verfügung haben. Einfach gesagt: je mehr Daten, umso besser. Mit einem grossen Trainingsdatensatz wird insbesondere auch das Overfitting-Problem abgeschwächt, da selbst komplexe Modelle mit vielen Trainingsdaten nicht zu Overfitting führen.
Trainingsdaten können aber auch einfach von schlechter Qualität sein. Zum Beispiel kann es sein, dass ganz viele Werte fehlen (missing values). Oder es kann vorkommen, dass Spalten viele falsche bzw. unrealistische oder unplausible Werte enthalten.
Ein weiteres Problem ergibt sich, wenn der Trainingsdatensatz nicht repräsentativ ist für die Fälle, die es dann in der Praxis vorherzusagen gilt. Es kommt hier zum Generalisierungsproblem: das gelernte Modell ist nicht generell genug, um für neue Datenpunkte gute Vorhersagen zu machen. Dieses Problem ergibt sich häufig durch den Faktor Zeit. Ein Modell wurde z.B. mit Daten aus dem Jahr 2021 trainiert. Nun macht es schlechte Vorhersagen im Jahr 2026. Das Problem ist womöglich, dass sich die Ausgangslage verändert hat und das Modell mit neueren Daten rekalibriert werden sollte. “Models tend to ‘rot’ as data evolves over time” (Géron (2022), Seite 99).
Schlechtes Modell
Wie bereits mehrfach erwähnt, ist es eminent wichtig, dass Sie ein Modell wählen, das für Ihr gegebenes Problem einen guten Tradeoff zwischen Bias (Underfitting) und Varianz (Overvitting) macht.
- Wenn Ihr Modell sowohl auf dem Trainings- als auch auf dem Validierungsdatensatz bzw. mit Cross-Validation einen hohen Fehler aufweist und nicht viel besser ist als die Baseline, dann haben wir es mit Underfitting zu tun. Versuchen Sie ein komplexeres Modell zu verwenden und / oder versuchen Sie, im Feature Engineering bessere Features zu entwickeln.
- Wenn Ihr Modell auf dem Traingsdatensatz gut performt, aber auf dem Validierungsdatensatz verhältnismässig schlecht abschneidet, dann haben wir es mit Overfitting zu tun. Probieren Sie einfachere Modelle aus oder reduzieren Sie die Komplexität Ihres aktuellen Modells. Auch gut: mehr Trainingsdaten, falls vorhanden.
Modell weiterentwickeln
Ein ML-Projekt ist leider nie wirklich fertig. Wie oben erwähnt, kann es vorkommen, dass sich die Vorhersagequalität über die Zeit verschlechtert, da sich die Ausgangslage und damit die Daten verändern. Darum ist es wichtig, dass Sie die Performance Ihres Modells bzw. Ihres ganzen produktiven Systems konstant monitoren. Sehr wahrscheinlich werden Sie Ihr Modell in regelmässigen Abständen rekalibrieren müssen.
Deployment
Alle Schritte und Tools, die mit dem Deployment von Modellen in produktive Systeme zu tun haben, nennt man MLOps. R bzw. RStudio bietet mit dem R-Package vetiver ein Tool, um wichtige Aspekte von MLOps abzudecken. Mit vetiver können die folgenden drei wichtigen Aufgaben gelöst werden:
- Versionierung von Modellen (wichtig, wenn Sie das Modell weiterentwickeln)
- Deployment von Modellen (REST API, Docker, etc.)
- Monitoring der Performance
Insbesondere das Deployment ist zentral. Nehmen wir an, dass Sie mit Ihrem Modell zufrieden sind. Nun gilt es, das Modell zu deployen. Das heisst, wir wollen es nun in bestehende Geschäftsprozesse bzw. -systeme einbauen, so dass die Vorhersagen des Modells direkt in Prozesse eingegliedert sind. Eine andere Möglichkeit des Deployments ist via eine Shiny App.
Ein letzter Punkt: Um Ihre Arbeitsweise als Data Scientist:in noch ein Stück weiter zu professionalisieren, können Sie die Tools Git und GitHub nutzen. Git ist ein sogenanntes Version Control System. Es erlaubt Ihnen Ihre Änderungen im R-Projekt bzw. im Code zu managen und rückverfolgbar zu machen. GitHub ist ein von Microsoft aufgekauftes Unternehmen, das die Code Repositories online hostet. Die Kombination von Git und GitHub erlaubt Ihnen wie erwähnt den Code zu versionieren und inbesondere professionell mit anderen Entwickler:innen zusammen zu arbeiten.