
Einführung Machine Learning
Lernziele
- Die Studierenden können für ein vorliegendes Problem bestimmen, ob es sich um ein Regressions- oder Klassifikationsproblem handelt.
- Die Studierenden kennen den Unterschied zwischen Supervised und Unsupervised ML.
- Die Studierenden verstehen die mathematischen Grundlagen des ML (Modell, Kostenfunktion, Notation, etc.).
- Die Studierenden wissen, was ein Modellparameter ist und können zwischen parametrischen und nicht-parametrischen Modellen unterscheiden.
- Die Studierenden verstehen das K-Nearest-Neighbors Modell.
- Die Studierenden verstehen, wie
tidymodelsfunktioniert und können bereits ein einfaches Modell rechnen. - Die Studierenden wissen, wo sie ML-Datensätze beziehen können.
Was ist Machine Learning?
Um zu verstehen, was Machine Learning (ML) ist, starten wir mit ein paar Definitionen:
“Machine Learning is the science (and art) of programming computers so they can learn from data.” Aurélien Géron in HOML, p. 4
Eine etwas ältere Definition stammt von Arthur Samuel, einem Pionier im Bereich Künstliche Intelligenz (KI):
“[Machine Learning is the] field of study that gives computers the ability to learn without being explicitly programmed.” Arthur Samuel, 1959
Wir werden also in diesem Modul vor allem damit beschäftigt sein, R-Code zu schreiben, der es unseren Computern erlaubt aus Daten automatisch Muster zu erkennen und zu lernen.
Beispiel: Spam Filter (Quelle: HOML)
Stellen Sie sich vor, wir haben einen Datensatz mit 300 Spam Emails und 700 “Ham” Emails (kein Spam). Ohne Machine Learning müssten wir nun von Hand die 300 Spam Emails mit den 700 Ham Emails vergleichen und versuchen, Muster zu finden, die es uns erlauben Regeln aufzustellen, um die Spam Emails korrekt zu klassifizieren (z.B. Spam enthält tendenziell eher Geldbeträge oder Preise als Ham). Danach könnten wir die Regeln mit R implementieren. Dann stellt sich aber auch noch die Frage, wie die verschiedenen Regeln miteinander kombiniert werden, um eine Klassifikation zu machen. Dieses Vorgehen würde sehr viel zu tun geben und es würde gezwungenermassen zu willkürlichen Entscheidungen führen.
Machine Learning führt zu i) weniger Aufwand und ii) besseren Lösungen, indem wir in einem R-Skript ein Modell (z.B. logistische Regression) aufsetzen und dann dem Modell die Daten in geeigneter Form füttern. Danach lernt der Computer selbständig, wie er die Emails bestmöglich in Spam und Ham klassifiziert.
Wann ist es sinnvoll ML einzusetzen?
- Falls der Arbeitsaufwand sehr gross ist, wenn das Problem “von Hand” gelöst werden soll. Das funktioniert insbesondere bei klar strukturierten Problemen gut, z.B. kann die Post die von Hand geschriebenen PLZ problemlos mittels Computer “lesen”.
- Komplexe Probleme, in denen ein Mensch keinen Überblick hat, weil so viele Daten vorhanden sind.
- Wenn sich das Problem dynamisch verändert. ML erlaubt es uns, ein Modell effizient mit neuen Daten zu rechnen und so an das veränderte Problem anzupassen.
Supervised vs. Unsupervised Learning
Beim Supervised Learning geht es um ML Probleme, in denen sowohl Input-Daten als auch ein Output vorhanden ist. Für die Input-Daten gibt es ganz viele verschiedene Begriffe, die synonym verwendet werden: z.B. Features, unabhängige Variablen, Attribute, Prädiktoren. Dasselbe gilt für den Output, hier gibt es folgende Synonyme: Zielvariable, abhängige Variable, Label, oder auch einfach \(y\).
Ziel ist es, ein Modell zu lernen, das basierend auf den Input-Daten möglichst gute Vorhersagen für den Output macht. Es geht also hier um Vorhersageprobleme. In einem gewissen Sinn ist der Output der Supervisor, der den Lernprozess des Modells überwacht.
Beim Unsupervised Learning verfügen wir nur über Input-Daten und keinen Output. Das Problem ist in diesem Fall weniger klar definiert. Folgende Probleme werden als Unsupervised Learning Probleme zusammengefasst:
- Clustering: zum Beispiel das Clustern von Kundinnen und Kunden in Kundensegmente.
- Dimensionsreduktion: eine Dimensionsreduktion wird häufig verwendet, um einen hochdimensionalen Datensatz zu visualisieren. Hochdimensionale Datensätze sind Datensätze mit vielen Variablen (oder Spalten in einem
Data Frame). Wenn wir den Datensatz auf 2 Dimensionen reduzieren, dann können wir die Datenpunkte in einem einfachen Streudiagramm visualisieren. - Anomalien erkennen: hier geht es darum ein statistisches Modell aus den Daten zu schätzen, damit für neue Beobachtungen eingeschätzt werden kann, wie wahrscheinlich diese Beobachtung ist. Sehr unwahrscheinliche Beobachtungen werden als Anomalie geflaggt. Dies kann zum Beispiel hilfreich sein, um betrügerische Kreditkartentransaktionen zu erkennen.
- Assoziationen lernen: zum Beispiel können die grossen Detailhändler lernen, welche Produkte von Kunden oft zusammen gekauft werden. So kann die Anordnung von Produkten in den Läden optimiert werden.
Beispiel: Dimensionsreduktion
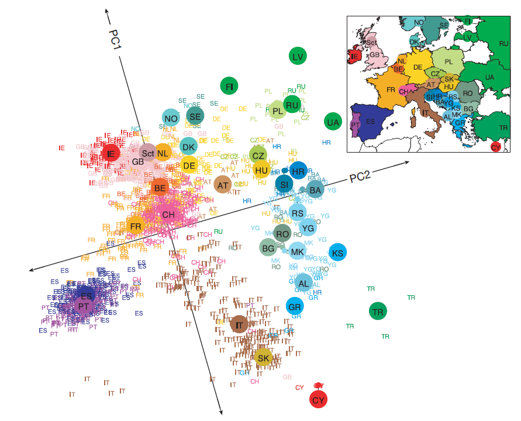
Quelle: Novembre et al. (2008)
Hier wird eine Technik mit dem Namen Principal Components Analysis verwendet, um einen hochdimensionalen Datensatz (~ 200K Variablen), der die genetischen Informationen von Menschen enthält, auf 2 Dimensionen zu reduzieren. So können die Daten in einem simplen Streudiagramm dargestellt werden.
Neben dem Supervised und dem Unsupervised Learning gibt es noch eine dritte erwähnenswerte ML Kategorie, nämlich Reinforcement Learning (RL). Dieser Kategorie gehören Modelle an, die sogenannte (virtuelle) Agenten so trainieren, dass sie langfristig möglichst optimal handeln. Das bekannteste Beispiel aus dem RL ist Googles AlphaGo Agent, welcher den menschlichen Go Weltmeister im Jahr 2017 schlug.
Regression vs. Klassifikation
Im Bereich des Supervised Learnings unterscheiden wir zwischen Regressions- und Klassifikationsproblemen.
Im Regressionsproblem ist der Output bzw. die Zielvariable eine stetige Variable (Intervall- oder Verhältnisskalierung), d.h. die Variable enthält numerische Werte.
Im Klassifikationsproblem ist der Output bzw. die Zielvariable eine kategorische Variable (Nominal- oder Ordinalskalierung).
Mathematische Grundlagen
Wir erarbeiten in diesem Abschnitt die mathematischen Grundlagen für das Supervised Learning, da das Supervised Learning unser Fokus in diesem Modul bilden wird.
Notation
Im Supervised Learning haben wir einerseits Input-Daten und andererseits einen Output. Die Input-Daten für eine Beobachtung \(i\) bezeichnen wir mit
\[\mathbf{x}_i=\begin{pmatrix} x_{i1} \\ x_{i2} \\ \vdots \\ x_{ip} \end{pmatrix},\]
wobei \(p\) die Anzahl Input-Variablen bezeichnet. Ausserdem sagen wir, dass \(i=1,\ldots,n\), das heisst, \(n\) bezeichnet die Anzahl Beobachtungen im Datensatz. Mit der Notation \(\mathbf{x}_i\) können wir die verschiedenen Attributswerte für die \(i\)-te Beobachtung kompakt (als Spaltenvektor) darstellen. Den entsprechenden Output für die Beobachtung \(i\) bezeichnen wir mit \(y_i\).
Beispiel: Betrügerische Kreditkartentransaktionen
Stellen Sie sich vor, wir versuchen mithilfe eines Datensatzes von 5000 vergangenen Kreditkartentransaktionen ein Klassifikationsmodell zu schätzen, das vorhersagt, ob es sich bei einer bestimmten Transaktion um eine betrügerische Transaktion handelt oder nicht. Jede Transaktion in Ihrem Datensatz entspricht einer Beobachtung \(i\). Der Output \(y_i\) in diesem Beispiel ist eine kategorische Variable, die wir als \(y_i\in\{\text{Betrug},\;\text{kein Betrug}\}\) darstellen können. Ausserdem haben Sie folgende Input-Daten:
\[ \mathbf{x}_i=\begin{pmatrix} \text{Transaktionsbetrag} \\ \text{Land des Zahlungsempfaengers} \\ \text{Zeitstempel der Transaktion} \end{pmatrix} \] Welche Werte nehmen in diesem Beispiel \(n\) und \(p\) an?
ML-Modelle im Allgemeinen
Bei einem ML-Problem gehen wir davon aus, dass es zwischen dem Input \(\mathbf{x}_i\) und dem Output \(y_i\) einen Zusammenhang gibt, der durch eine mathematische Funktion \(f()\) ausgedrückt werden kann:
\[ y_i = f(\mathbf{x}_i) + \epsilon \]
\(f(\mathbf{x}_i)\) ist die systematische Information, die wir aus \(\mathbf{x}_i\) im Hinblick auf \(y_i\) lernen können. \(\epsilon\) ist ein Fehlerterm, der die Differenz zwischen \(y_i\) und \(f(\mathbf{x}_i)\) abbildet, also den nicht-lernbaren (unsystematischen) Teil. Der Fehlerterm beinhaltet einerseits den Effekt von Variablen, die uns nicht zur Verfügung stehen, aber einen Einfluss auf den Output \(y_i\) haben und andererseits nicht-messbare Variation, oft auch einfach “Noise” genannt. Grob gesagt: alles nicht-messbare. Der Output \(y_i\) ergibt sich also aus der Addition des systematischen Teils \(f(\mathbf{x}_i)\) sowie des Fehlerterms \(\epsilon\).
Wichtig: Ziel des Machine Learnings ist es, eine Funktion \(\hat{f}(\mathbf{x}_i)\) zu schätzen, die der wahren aber unbekannten Funktion \(f(\mathbf{x}_i)\) so nahe wie möglich kommt. Im (unrealistischen) Idealfall ist unser geschätztes Modell gleich der wahren Funktion, also \(\hat{f}(\mathbf{x}_i) = f(\mathbf{x}_i)\) und wir haben die systematische Information perfekt gelernt. Jedes ML-Modell, das wir uns in diesem Modul anschauen werden, kann als eine mathematische Funktion \(\hat{f}(\mathbf{x}_i)\) der Input-Variablen \(\mathbf{x}_i\) aufgeschrieben werden.
Das einfachste ML-Modell haben Sie bereits vor einiger Zeit kennen gelernt: die (multiple) lineare Regression. Auch die entsprechende Funktion sollte Ihnen noch bekannt vorkommen:
\[ f(\mathbf{x}_i) = b_0 + b_1 \cdot x_{i1} + b_2 \cdot x_{i2} + \ldots + b_p \cdot x_{ip} \] Wir verzichten hier bewusst darauf, den Hut für \(f\) zu schreiben, da es sich lediglich um eine allgemein gültige Funktion handelt und noch nichts geschätzt wurde. Dieses Modell bzw. diese Funktion hat sogenannte Parameter, die es zu schätzen gilt. Hier sind dies die Parameter \(b_0,\; b_1,\; \ldots,\; b_p\). Diese Parameter sind die Schlüsselzutat in einem ML-Modell. Wir wollen sie optimieren, so dass die geschätzte Funktion der wahren möglichst nahe kommt.
Optional: Lineare Regression in Vektorform
Wir haben oben gesehen, dass die Input-Variablen als Spaltenvektor geschrieben werden können. Wir modifizieren diesen Spaltenvektor in einem ersten Schritt, indem wir an erster Stelle eine 1 einfügen, also:
\[\mathbf{x}_i=\begin{pmatrix} 1\\ x_{i1} \\ x_{i2} \\ \vdots \\ x_{ip} \end{pmatrix}\]
Nun stecken wir die Parameter des Modells ebenfalls in einen Spaltenvektor:
\[\mathbf{b}=\begin{pmatrix} b_0 \\ b_1 \\ b_2 \\ \vdots \\ b_p \end{pmatrix}\]
Wir können nun das lineare Regressionsmodell als Skalarprodukt dieser beiden Vektoren aufschreiben:
\[\mathbf{b}' \mathbf{x_i} = \begin{pmatrix} b_0 & b_1 & b_2 & \dots & b_p \end{pmatrix} \begin{pmatrix} 1\\ x_{i1} \\ x_{i2} \\ \vdots \\ x_{ip} \end{pmatrix} = b_0 \cdot 1 + b_1 \cdot x_{i1} + b_2 \cdot x_{i2} + \dots + b_p \cdot x_{ip}\]
Das Apostroph beim Spaltenvektor \(\mathbf{b}\) bedeutet, dass wir den Spaltenvektor transponieren, so dass aus ihm ein Zeilenvektor wird (wie nach dem ersten Gleichzeichen gesehen werden kann). Nur so ist das Skalarprodukt korrekt spezifiziert.
Wir werden in diesem Modul sehr einfache, aber auch sehr komplexe Funktionen kennen lernen. Je komplexer die Funktionen sind, desto mehr haben wir es mit einer Blackbox zu tun und desto schwieriger wird es, das Modell zu interpretieren. Relativ unflexible Modelle wie z.B. die lineare Regression sind einfach interpretierbar. Die geschätzten Koeffizienten \(\hat{b}_1,\; \hat{b}_2,\; \ldots\) erlauben uns direkt zu quantifizieren, was der Effekt der verschiedenen Input-Variablen ist. Im Gegensatz dazu führen komplexe Modelle (mit vielen zu optimierenden Parameter) oft zu einer sehr guten Vorhersagegüte, weil komplexe Modelle flexibel sind und darum komplexe Zusammenhänge zwischen \(\mathbf{x}_i\) und \(y_i\) modellieren können.
Wie rechnen wir ein ML-Modell?
Grob gesagt rechnen wir ein ML-Modell in zwei Schritten. In einem ersten Schritt entscheiden wir uns für die funktionale Form unseres Modells \(\hat{f}(\mathbf{x}_i)\). Man nennt dies in der Fachsprache Model Selection. Wir betrachten hier nur mal den vereinfachten Fall, in dem wir nur eine \(x_i\)-Variable pro Beobachtung als Input haben. Folgende Funktionen bzw. Modelle sind mögliche Kandidaten:
- \(f(x_i) = b_0 + b_1 \cdot x_i\) (einfache lineare Regression)
- \(f(x_i) = b_0 + b_1 \cdot x_i + b_2 \cdot x_i^2\) (polynomische Regression)
- \(f(x_i) = \begin{cases} \bar{y}_1, & \text{falls}\; x_i > x^*\\ \bar{y}_2, & \text{sonst} \end{cases}\)
Wir werden mit unserer Wahl der Funktion nie genau die wahre aber unbekannte Funktion \(f(\mathbf{x}_i)\) treffen, aber wir versuchen möglichst nahe daran zu kommen.
“No Free Lunch” Theorem
Das No Free Lunch Theorem besagt, dass es kein universal bestes Modell gibt. Das heisst, dass es je nach Problem und Datensatz andere Modelle bzw. Funktionen braucht, um gute Vorhersagen zu machen. Das ist der Hauptgrund, warum wir Ihnen möglichst viele verschiedene Tools mit auf den Weg geben wollen.
In einem zweiten Schritt geht es darum, die Parameter des im ersten Schritt gewählten Modells zu schätzen. Man nennt dies in der Fachsprache Model Fitting / Training, weil wir versuchen, das Modell so gut wie möglich an die Daten zu fitten. Sie haben bereits eine Methode kennen gelernt, wie die Parameter eines Modells geschätzt werden können:
- Kleinstquadratemethode oder auf English “Least squares” (Modul EMBA)
Die Grundidee beim Model Fitting ist, eine Kostenfunktion (engl. Loss Function) aufzustellen, die von den Parameterwerten der Funktion \(\hat{f}(\mathbf{x}_i)\) abhängt. Und nun der Schlüsselschritt:
Während des Trainings verändern wir die Parameterwerte so lange, bis die Kostenfunktion ein Minimum erreicht.
Nun haben wir die optimalen Parameterwerte und darum auch das optimale Modell \(\hat{f}(\mathbf{x}_i)\) gefunden. Für das Regressionsproblem haben Sie bereits eine mögliche Kostenfunktion (Stichwort Summe der quadrierten Residuen) kennen gelernt:
\[ J(\text{Modellparameter}) = \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{f}(\mathbf{x}_i) \right)^2 \]
Im Vergleich zur Summer der quadrierten Residuen haben wir hier noch den Faktor \(\frac{1}{2n}\) drin. Dieser Faktor macht daraus eine Art Mittelwert und darum wird diese Kostenfunktion typischerweise Mean Squared Error (MSE) genannt.
Sie wundern sich nun vielleicht, wie diese Kostenfunktion von den Modellparameter abhängt, da diese in obiger Formel ja gar nicht ersichtlich sind. Schreiben wir die Kostenfunktion doch mal etwas um (unter der Annahme, dass es nur eine Input-Variable \(x_i\) gibt und wir ein einfaches lineares Regressionsmodell anwenden wollen):
\[ \begin{align} J(\hat{b}_0, \hat{b}_1) &= \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{f}(x_i) \right)^2 \\ &= \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - (\hat{b}_0 + \hat{b}_1 \cdot x_i) \right)^2 \\ &= \frac{1}{2n} \sum_{i=1}^{n} \left(y_i - \hat{b}_0 - \hat{b}_1 \cdot x_i \right)^2 \\ \end{align} \]
Nun ist offensichtlich, wie die Kostenfunktion \(J\) von den Modellparameter \(\hat{b}_0\) und \(\hat{b}_1\) abhängt. Im ML gibt es nun viele verschiedene Arten, wie man für die beiden Modellparameter die optimalen Werte findet. Hier ist die Lösung zum Glück einfach, denn es gibt eine sogenannte analytische Lösung, die man mit der oben erwähnten Kleinstquadratemethode findet. Wie Sie diese analytische Lösung finden, haben Sie bei Thomas Heimsch in Aufgabe 5 der Übungsserie 2 gelernt (zwar mit anderer Notation, aber vom Prinzip her gleich).
Für andere Modelle gibt es oft leider keine analytische Lösung für die optimalen Parameterwerte. In diesem Fall werden wir iterative Optimierungsverfahren anwenden, mit denen wir uns langsam den optimalen Parameterwerten annähern (dazu später mehr).
Grundsätzlich gilt: je besser die Modellparameter geschätzt werden können, desto kleiner sind die quadrierten Differenzen, \(\left(y_i - \hat{f}(x_i) \right)^2\), und desto kleiner der Wert der Kostenfunktion.
Da wir der Einfachheit halber für die Beispielsfunktionen oben nur eine Input-Variable angenommen haben, können wir uns nun anschauen, wie die verschiedenen Beispielsfunktionen für einen gegebenen Datensatz grafisch aussehen:
Optional: Zerlegung des Vorhersagefehlers
Wir wollen hier kurz anschauen, wie der Erwartungswert des quadrierten Fehlers, \(\left(y_i - \hat{f}(\mathbf{x}_i)\right)^2\), in zwei Komponenten zerlegt werden kann.
Dazu gilt folgendes:
- Von oben wissen wir, dass \(y_i = f(\mathbf{x}_i) + \epsilon\) gilt.
- Wir nehmen an, dass der Erwartungswert des unsystematischen Teils \(\epsilon\) Null ist, also \(\text{E}(\epsilon)=0\).
- Allgemeine Regel zur Varianz einer Zufallsvariable: \(\text{Var}(\epsilon) = \text{E}(\epsilon^2) - \text{E}(\epsilon)^2 = \text{E}(\epsilon^2) - 0^2 = \text{E}(\epsilon^2)\).
- \(\hat{f}\) und \(\mathbf{x}_i\) sind fix und gegeben (keine Zufallsvariablen) und darum gilt \(\text{E}\left(\hat{f}(\mathbf{x}_i)\right)=\hat{f}(\mathbf{x}_i)\).
Nun können wir den Erwartungswert des quadrierten Fehlers rechnen:
\[ \begin{align} \text{E}\,\left[\left(y_i - \hat{f}(\mathbf{x}_i)\right)^2\right] &= \text{E}\,\left[\left(f(\mathbf{x}_i) + \epsilon - \hat{f}(\mathbf{x}_i)\right)^2\right] \\ &= \text{E}\,\left[f(\mathbf{x}_i)^2 - 2 \cdot f(\mathbf{x}_i) \cdot \hat{f}(\mathbf{x}_i) + \hat{f}(\mathbf{x}_i)^2 + 2 \cdot \epsilon \cdot f(\mathbf{x}_i) - 2 \cdot \epsilon \cdot \hat{f}(\mathbf{x}_i) + \epsilon^2 \right] \\ &= f(\mathbf{x}_i)^2 - 2 \cdot f(\mathbf{x}_i) \cdot \hat{f}(\mathbf{x}_i) + \hat{f}(\mathbf{x}_i)^2 + 2 \cdot \text{E}(\epsilon) \cdot f(\mathbf{x}_i) - 2 \cdot \text{E}(\epsilon) \cdot \hat{f}(\mathbf{x}_i) + \text{E}(\epsilon^2) \\ &= f(\mathbf{x}_i)^2 - 2 \cdot f(\mathbf{x}_i) \cdot \hat{f}(\mathbf{x}_i) + \hat{f}(\mathbf{x}_i)^2 + 2 \cdot 0 \cdot f(\mathbf{x}_i) - 2 \cdot 0 \cdot \hat{f}(\mathbf{x}_i) + \text{Var}(\epsilon) \\ &= f(\mathbf{x}_i)^2 - 2 \cdot f(\mathbf{x}_i) \cdot \hat{f}(\mathbf{x}_i) + \hat{f}(\mathbf{x}_i)^2 + \text{Var}(\epsilon) \\ &= \left(f(\mathbf{x}_i) - \hat{f}(\mathbf{x}_i)\right)^2 + \text{Var}(\epsilon) \end{align} \]
Der erste Teil auf der rechten Seite der Formel beschreibt den reduzierbaren Fehler und der zweite Teil den nicht-reduzierbaren Fehler. Wir sehen also auch hier: es ist sehr wichtig, dass wir eine Funktion \(\hat{f}(\mathbf{x}_i)\) schätzen, welche dem wahren funktionalen Zusammenhang \(f(\mathbf{x}_i)\) möglichst nahe kommt.
Nicht-parametrische Modelle
Bisher haben wir nur von sogenannten parametrischen Modellen gesprochen. Modelle also, bei denen die Anzahl Parameter von vornherein auf eine bestimmte Anzahl limitiert bzw. vorgegeben ist. Nachdem ein Modell \(\hat{f}(\mathbf{x}_i)\) geschätzt wurde, könnten wir im Prinzip die Trainingsdaten wegwerfen, denn alles, was wir benötigen ist in der geschätzten Funktion enthalten.
Eine weitere Art von Modellen sind sogenannte nicht-parametrische Modelle. Solche Modelle versuchen ein Regressions- oder Klassifikationsproblem zu lösen, indem die Distanz von einem Datenpunkt zu den Datenpunkten im Trainingsdatensatz gemessen wird. Nahe Datenpunkte sind dabei wichtiger als weit entfernte Datenpunkte. Wir sehen nun auch gleich, dass wir hier die Trainingsdaten nie wegwerfen können, denn für jede Vorhersage eines neuen Datenpunkts müssen wir die Distanzen zu allen Trainingsdatenpunkten messen. Man spricht in diesem Zusammenhang manchmal auch von instance-based Models, da das Modell von allen Trainingsinstanzen abhängig ist.
Der bekannteste (und einfachste) nicht-parametrische Ansatz ist der K-Nearest-Neighbor Algorithmus (KNN). Die Idee könnte kaum simpler sein: wir nehmen für einen neuen Datenpunkt \(\mathbf{x}_0\) die \(K\) nächsten Nachbarn. Wir bezeichnen die Nachbarschaft von \(\mathbf{x}_0\) als \(N_0\). Die Vorhersagen des KNN Algorithmus unterscheiden sich für das Klassifikations- und das Regressionsproblem:
- Im Fall eines Klassifikationsproblems entspricht unsere Vorhersage der Klasse die am häufigsten vorkommt in der Nachbarschaft \(N_0\), also unter den \(K\) Nachbarn.
- Im Falle eines Regressionsproblems entspricht unsere Vorhersage dem Mittelwert über die \(y\)-Werte der \(K\) Nachbarn. Mathematisch ausgedrückt sieht die Vorhersage wie folgt aus: \(\hat{y}_0 = \frac{1}{K} \sum_{\mathbf{x}_i \in N_0} y_i\).
Das KNN-Modell hat nur einen (Hyper-)Parameter, nämlich \(K\). Das optimale \(K\) finden wir normalerweise mithilfe von Cross-Validation (dazu später mehr).
Stellen Sie sich vor, Sie haben folgendes Klassifikationsproblem, das Sie mit KNN lösen wollen:
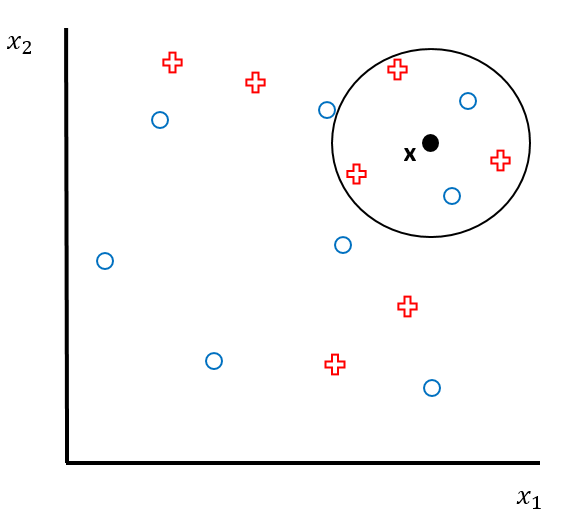
Beantworten Sie folgende Fragen dazu:
Stellen Sie sich vor, Sie haben folgendes Regressionsproblem, das Sie mit KNN lösen wollen:
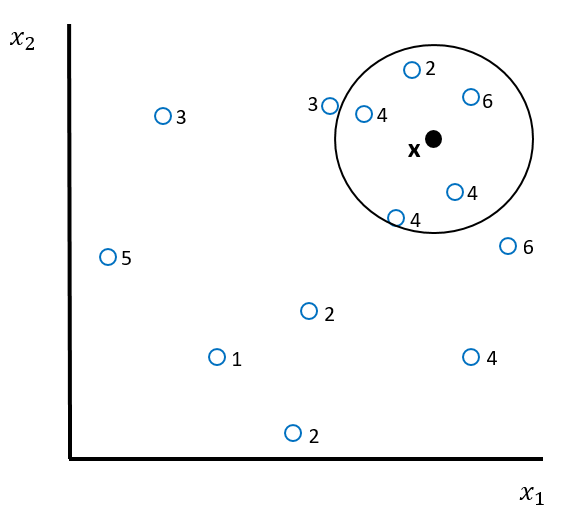
Die grösste Schwäche des KNN-Algorithmus ist, dass er nur gut funktioniert, wenn wir wenige Input-Variablen haben. Je mehr Input-Variablen wir haben, desto weiter entfernt sind die \(K\) Nachbarn von einem Datenpunkt \(\mathbf{x}\), für den wir eine Vorhersage machen wollen. Weit entfernte Nachbarn sind aber nicht gute Prädiktoren. Man spricht in diesem Zusammenhang vom Curse of Dimensionality, eine der grossen Challenges im ML.
Beispielsanwendungen
Werbung
Beispiel: Targeted Advertizing
Unternehmen wie Google betreiben ein sogenanntes Targeted Advertizing. Dabei geht es darum, die Wahrscheinlichkeit, dass eine Userin oder ein User auf ein Online-Inserat klickt, zu modellieren. Diese Wahrscheinlichkeit wird in der Praxis oft click-through rate (CTR) genannt. Für die Vorhersage der CTR werden die spezifischen Merkmale einer Userin oder eines Users sowie Merkmale des Inserats, und insbesondere die Search History einer Userin oder eines Users verwendet. So können jeder Person die Inserate mit der höchsten vorhergesagten CTR gezeigt werden, wodurch der Profit von Unternehmen wie Google maximiert wird.
Computer Vision
Beispiel: Erkennung von Handschrift
Eine enorm bekannte (und bereits sehr alte, aus dem Jahr 1998 stammende) ML-Challenge ist der MNIST Datensatz, der 70’000 Bilder von handgeschriebenen Zahlen enthält. Diese Bilder können als Datensatz dargestellt werden, in dem jede Spalte ein Pixel repräsentiert. Das Ziel ist, für jedes Bild automatisch zu bestimmen, welche Zahl abgebildet ist. Die Post verwendet Algorithmen um automatisch die PLZ auf Briefen und Paketen zu bestimmen. Die Verteilzentren der Post arbeiten unter anderem aufgrund solcher Algorithmen mit wenig menschlichem Arbeitseinsatz.

Ein weiteres Beispiel aus dem Gebiet Computer Vision:
Beispiel: Gesichtserkennung
Die automatische Erkennung von Gesichtern auf Fotos (Face Detection) ist aus mehrfacher Sicht hilfreich. Erstens können so Gesichter in verschiedenen Fotos verglichen werden, was uns erlaubt dieselbe Person in mehreren Fotos zu erkennen (Face Recognition). Zweitens wird die Gesichtserkennung beim Auto-Fokus in Smartphone-Kameras verwendet. Drittens können so bei Anwendungen wie Google StreetView automatisch die Gesichter von Personen unkenntlich gemacht werden.
Die grobe Idee von solchen Anwendungen ist wie folgt: ein Algorithmus untersucht verschiedene, überlappende Teilbereiche eines Fotos und sagt für jeden dieser kleinen Teilbereiche vorher, wie wahrscheinlich es ist, dass es sich dabei um ein Gesicht handelt. Man spricht dabei von einem Sliding Window Detector. (Quelle: K. Murphy (2012), Machine Learning: A Probabilistic Perspective)

Natural Language Processing (NLP)
Beispiel: Auto-Complete
Google und andere Suchmaschinen versuchen unsere Search Queries automatisch zu vervollständigen. Solche Anwendungen basieren auf komplexen Sprachmodellen und einem gigantischen Corpus von vergangenen Search Queries. In unten stehendem Beispiel werden die wahrscheinlichsten Vervollständigungen für das Fragment “wie bleibe ich” angezeigt.
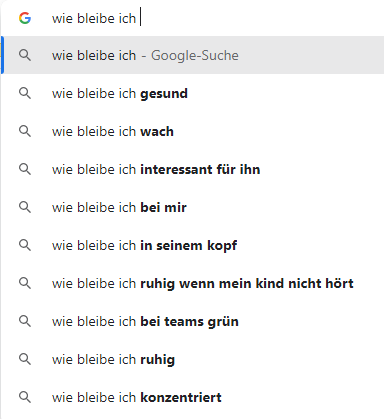
Haben Sie dieselben Vervollständigungsvorschläge?
Die grosse Sensation im Bereich NLP sind jedoch sogennante Large Language Models (LLMs) wie z.B. ChatGPT. Die Investitionen, die aktuell in die Entwicklung von Unternehmenslösungen basierend auf LLMs fliessen sind enorm gross. Gleichzeitig arbeiten sowohl Forschende als auch Unternehmen wie OpenAI mit Hochdruck daran, die Modelle noch besser zu machen. Die Anwendungsbereiche solcher Modelle sind extrem vielfältig. Aktuell wird unter anderem daran gearbeitet, LLMs für einen automatisierten Kundenservice zu verwenden und/oder um interne Prozesse in Organisationen zu optimieren (z.B. Zusammenfassung von Dokumenten, automatisierte Sitzungsprotokolle, etc.).
Retail und Netflix
Beispiel: Recommender Systems
Recommender Systems wurden insbesondere durch die Unternehmen Netflix und Amazon bekannt, welche spezifische Film- bzw. Kaufempfehlungen schon früh umsatzsteigernd einsetzten.
Die Grundidee des Netflix-Systems ist folgendermassen: alle User-Ratings werden in einer sogenannten User-Movie-Matrix zusammengefasst. Jede Zeile in dieser Matrix entspricht einem User bzw. einer Userin. Die Spalten enthalten die Filme, die auf Netflix verfügbar sind. Die resultierende Matrix ist eher sparse, d.h. viele Zellen der Matrix werden keinen Eintrag haben, da die meisten Userinnen und User nur einen Bruchteil aller Filme gesehen bzw. bewertet haben. Die Herausforderung ist nun, für jede leere Zelle eine Vorhersage zu machen. Dazu wird typischerweise ein Algorithmus mit dem Name Collaborative Filtering verwendet.

Hier haben wir uns als Beispiel Netflix (und Amazon) angeschaut, doch Empfehlungen sind vielerorts einsetzbar. Zum Beispiel versuchen Online-Medien so weitere Artikel zu empfehlen, die für eine Leserin oder einen Leser interessant sein könnten. Könnte ein Recommender System auch interessant sein für ein KMU, das den Kundinnen und Kunden Produktempfehlungen machen möchte?
Einführung tidymodels
In diesem Abschnitt gehen wir kurz auf die wichtigsten Elemente des R-Packages tidymodels ein. Bei tidymodels handelt es sich um eine Verbesserung bzw. Erweiterung des bekannten R-Packages caret. Dabei ist der selbe Software-Entwickler (Max Kuhn) federführend. tidymodels ist von der Philosophie her ähnlich aufgebaut wie tidyverse, das Sie ja bereits kennen. Wie bei tidyverse handelt es sich bei tidymodels eher um eine Gruppe von R-Packages als ein einzelnes Package. Wir können diese Gruppe von R-Packages in einem Schritt installieren und laden:
# Wir installieren tidymodels
install.packages("tidymodels")
# Danach laden wir das Package in die aktuelle R-Session
library(tidymodels)tidymodels wird von RStudio unterhalten und ist darum sehr gut dokumentiert. Das Ziel von tidymodels ist es, in R ein einheitliches Interface zu schaffen, um verschiedene ML-Modelle zu rechnen. tidymodels gibt uns in einem gewissen Sinn die Struktur vor, wie wir in R ML-Probleme lösen.
tidymodels vereint vier Kernelemente, die in jedem ML-Workflow vorkommen:
- Erstellen und Rechnen eines Modells (
parsnip) - Preprocessing Pipelines (
recipes) - Evaluierung des Modells mit Resampling Techniken (
rsample) - Hyperparameter Tuning von Modellen (
tune)
Wir werden diese vier Elemente sowie weitere wichtige Aspekte im Detail anschauen, wenn wir uns mit ML-Pipelines auseinander setzen. Um eine erste Idee zu erhalten, schauen wir uns ein kurzes Beispiel zum ersten Element (Erstellen und Rechnen eines Modells) an. Das Beispiel lehnt sich an die Get Started Seite an.
Wir arbeiten in diesem Beispiel mit einem kleinen Ausschnitt aus dem Homegate Datensatz, den Sie ev. bereits kennen gelernt haben. Der Datensatz ist bereits geladen und Sie können ihn in unten stehenden Code Chunks unter dem Namen df aufrufen.
In einem ersten Schritt prüfen wir die Anzahl fehlender Werte pro Spalte. Danach entfernen wir alle Zeilen mit fehlenden Werten und transformieren alle Character Spalten in Faktoren.
# Anzahl fehlende Werte pro Spalte
sapply(df, function(x) sum(is.na(x)))
# Wir entfernen fehlende Werte und transformieren alle Character Spalten in Faktoren
df_final <- df %>%
na.omit() %>%
mutate_if(is.character, as.factor)Nun wollen wir einen Teil der Daten visualisieren. Wir erstellen ein Streudiagramm für die Beobachtungen in den Kantonen Aargau, Solothurn, Zürich und Zug und plotten für jeden Kanton separat einen linearen Fit. Dazu nutzen wir bekannte Funktionen aus dem tidyverse, insbesondere ggplot2.
# Visualisierung der Daten für die Kantone AG, SO, ZH und ZG
df_final %>%
filter(cant %in% c("AG", "SO", "ZH", "ZG")) %>%
ggplot(aes(x = zimmer,
y = miete,
group = cant,
col = cant)) +
geom_point() +
geom_smooth(method = lm, se = FALSE) +
theme_bw()Als nächstes initialisieren wir ein lineares Regressionsmodell und speichern es als lm_mod. Danach wenden wir basierend auf diesem Objekt die fit() Funktion an. Mit der Formel miete ~ zimmer * cant sagen wir der fit() Funktion, dass wir ein Modell mit Interaktionseffekten schätzen wollen. Effektiv führt das dazu, dass wir für jeden Kanton eine separate Gerade (wie in obiger Abbildung) schätzen.
# Wir bilden ein lineares Regressionsmodell
lm_mod <- linear_reg()
# Nun rechnen wir das Modell (Model Fitting)
lm_fit <-
lm_mod %>%
fit(miete ~ zimmer * cant, data = df_final)Mit der Funktion tidy() können wir den Modelloutput aufrufen.
# Überblick Modell
tidy(lm_fit) %>%
print(n = 52)Nun wollen wir unser gefittetes Modell nutzen, um Vorhersagen zu machen. Und zwar wollen wir wissen, wie viel eine 4-Zimmer Wohnung in den Kantonen Aargau, Solothurn, Zürich und Zug gemäss unserem Modell kostet. Dazu erstellen wir erst einen kleinen Dataframe mit der expand.grid() Funktion.
# Dataframe mit x-Werten, für die eine Vorhersage gerechnet werden soll
new_x <- expand.grid(zimmer = 4, cant = c("AG", "SO", "ZH", "ZG"))Jetzt können wir die predict() Funktion verwenden, um die Vorhersagen zu rechnen. Um Vorhersageintervalle zu rechnen, kann der predict() Funktion zusätzlich das Argument type = "conf_int" übergeben werden.
# Vorhersagen rechnen
mean_pred <- predict(lm_fit, new_data = new_x)
# Vorhersageintervalle rechnen
conf_int_pred <- predict(lm_fit, new_data = new_x, type = "conf_int")Wir sind fast fertig! Nun kombinieren wir die x-Werte mit den Vorhersagen sowie den Vorhersageintervallen. Den resultierenden Dataframe verwenden wir dann im letzten Schritt für einen Plot.
# Kombiniere Modelloutputs und x-Werte
plot_data <-
new_x %>%
bind_cols(mean_pred) %>%
bind_cols(conf_int_pred)Nun plotten wir die vier Vorhersagen mitsamt den Vorhersageintervallen.
# Plot der Vorhersagen inkl. Intervallen
ggplot(plot_data, aes(x = cant)) +
geom_point(aes(y = .pred)) +
geom_errorbar(aes(ymin = .pred_lower,
ymax = .pred_upper),
width = .2) +
labs(x = "Kanton", y = "Miete", title = "Vorhersage Miete", subtitle = "4-Zimmer Wohnungen") +
theme_bw()ML-Datenquellen und Literatur
Oft ist es nicht so einfach, einen Datensatz zu finden, der für die Demonstration von ML Modellen taugt. Glücklicherweise gibt es mindestens zwei gute Plattformen, welche eine Fülle von interessanten Datensätzen anbieten.
Kaggle
Die erste Plattform ist Kaggle, eine bekannte ML-Plattform, die in erster Linie sogenannte ML-Competitions hostet. Die Idee dabei ist, dass ein Unternehmen ein ML-Problem auf die Plattform hochlädt und die Kaggle-Community sich dann an diesem Problem versucht. Oft werden am Schluss einer Competition die besten Lösungen mit beachtlichen Geldpreisen honoriert. Mittlerweile hat sich Kaggle aber zu einer regelrechten ML-Kompetenzplattform weiterentwickelt. Unter anderem gibt es nun auch ein Repository mit interessanten Datensätzen.
Repository UC Irvine
Die zweite Plattform ist das Repository der UC Irvine. Dieses Repository lässt sich mit den Filterfunktionen gut nach spezifischen Datensätzen durchsuchen. Z.B. kann nach univariaten Regressionsproblemen im Bereich Business gesucht werden.
Literatur und weiterführende Ressourcen
Zum Thema Machine Learning gibt es eine unglaublich grosse Anzahl Ressourcen online, aber auch in Buchform. In nachfolgender Liste finden Sie eine Auswahl von meinen Empfehlungen:
- [ISLR] Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani. (2021). An Introduction to Statistical Learning : with Applications in R. New York: Springer. 2nd Edition. Link
- [HOML] Aurélien Géron. (2022). Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems. Sebastopol: O’Reilly Media Inc. 3rd Edition. Link
- tidymodels Dokumentation
- Kaggle Kurse
- Machine Learning Tutorials mit R (University of Cincinnati)
- Machine Learning Kurse von Google