
Einstieg
Web-Scraping ist das Beziehen (ggf. auch das Bereitstellen) von strukturierten und unstrukturierten Daten über Web-Services.
Zum Beispiel kann es auch schwierig sein, von Adressen die Koordinaten zu finden (wie in Google-Maps). Google stellt hier (kostenpflichtige) APIs zur Verfügung, weshalb wir eine alternative Lösung verwenden werden:
Lernziele
- Sie können Informationen aus statischen (Package
rvest) und dynamischen (PackageRSelenium) Websites ziehen - Sie können mit APIs abfragen machen
- Sie können Ihr eigenes Web-Scrapping Projekt vorantreiben
Installieren Sie nun lokal die R-packages rvest, httr und polite über install.packages('rvest') und so weiter. Vor allem aber installieren Sie ebenfalls:
- das
R-PackageRSelenium: (install.packages('RSelenium'))
Insgesamt brauchen wir für dieses Tutorial folgende Packages:
library(tidyverse)
library(wordcloud)
library(RSelenium)
library(tm)
library(httr)
library(leaflet)
library(scales)
library(RColorBrewer)
library(MASS)
library(rvest)Warum Web-Scraping?
- sehr viele Daten online verfügbar
- soziale Interaktion online (Social-Media)
- Web-Services und Apps generieren Daten zum User-Verhalten
- Online Daten sind häufig zur Anzeige und nicht zum Download verfügbar (e.g. Homegate)
- kostengünstig und zeitsparende Art, Daten zu beschaffen
Ein Kurzbeispiel mit rvest
Wir starten ein kleines Projekt mit dem Package rvest. Von der Euro-Millions Seite wollen wir die letzte Ziehung scrapen - und zwar die Gewinnzahlen und die Verteilung der Anzahl Gewinner.
Wir wollen also von der Euro-Millions-Seite die aktuellen Gewinnzahlen ziehen:
Diese lauten, gemäss untenstehender Webpage:
Link zur Webpage (Ziehung vom 22.05.2026):
Wir analysieren das Beispiel mit folgendem Code:
Beschreibung des EuroMillions-Codes
todaywird als aktuelles Datum gesetzt.- Mit
wday()wird der letzte Freitag (lastfr) und der letzte Dienstag (lasttue) berechnet. todaywird auf das neuere der beiden Daten gesetzt - letzte EuroMillions-Ziehung.- Das Datum wird in das Format DD-MM-YYYY umgewandelt, das von euro-millions.com benötigt wird.
- Aus dem Datum wird der URL gebaut:
https://www.euro-millions.com/results/DD-MM-YYYY
- Die Seite wird mit
rvest::read_html()geladen. - Die Ziehungszahlen werden aus dem CSS-Element
#ballsAscending.ballsextrahiert. - Daraus entstehen:
mynums= die 5 regulären Zahlenmyzs= die 2 Sternzahlen
- Die Gewinn-Tabelle wird über das CSS-Element
#PrizeCHeingelesen und als tibble verarbeitet. - Spalten werden bereinigt (Entfernung von Währungen, Leerzeichen, Nicht-Ziffern).
richtigewird aufgeteilt in:r= Anzahl korrekte reguläre Zahlenz= Anzahl korrekte Sterne
- Für jede Gewinnklasse wird die theoretische Wahrscheinlichkeit berechnet:
- Kombinationen aus 5 aus 50 regulären Zahlen
- Kombinationen aus 2 aus 12 Sternzahlen
- Die Tabelle enthält danach pro Gewinnklasse:
- Anzahl CH-Gewinner
- Anzahl totaler Gewinner
- theoretische Gewinnwahrscheinlichkeit
- Gesamtzahl der Teilnehmer wird geschätzt durch:
esttot= Summe aller Gewinner / Summe aller theoretischen Wahrscheinlichkeitenestch= Summe aller CH-Gewinner / Summe aller theoretischen Wahrscheinlichkeiten
- Ergebnis:
- esttot = geschätzte Gesamtzahl aller Spieler
- estch = geschätzte Anzahl Spieler aus der Schweiz
Starten eines Scraping-Projektes mit RSelenium
Web-Technologien und Wege zur Informations-Gewinnung
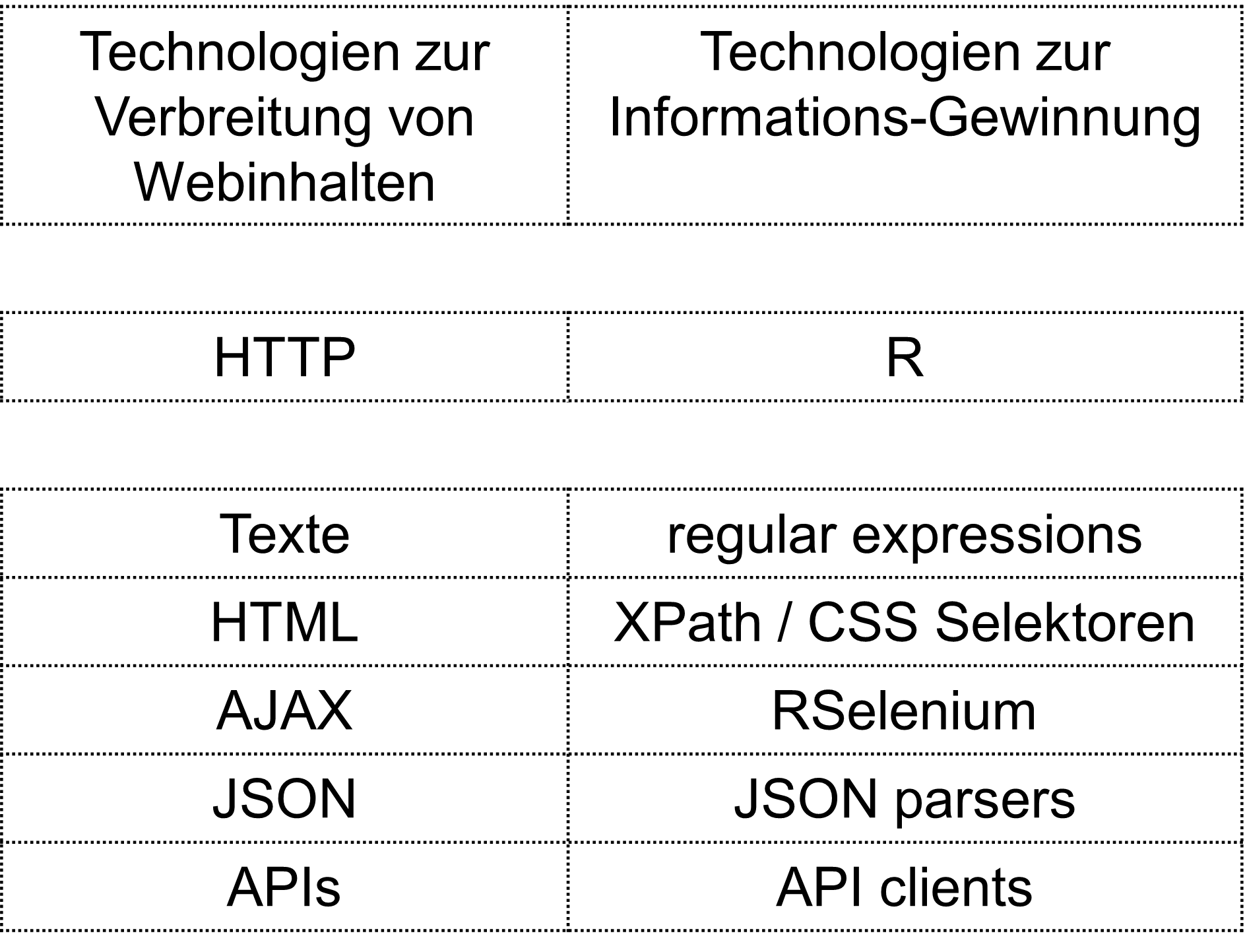
HTMLheisst Hyper Text Markup Language
- W3C-Standard für das Erstellen von Webseiten
HTMLbestimmt die Art und Ort der Speicherung von Informationen
- Ein passives
HTML-Verständnis reicht aus
Insbesondere haben wir schon HTML-tags kennen gelernt.
Wichtige Tags sind: <div> und <span>, welche der Gruppierung der Inhalte über die Zeilen oder innerhalb der Zeilen dienen. Sie verändern nicht das Layout sondern steuern dieses über das CSS-File.
Beispiel CSS (Cascading Style Sheets):
div.happy { color:pink;
font-family:'Comic Sans MS';
font-size:120% }
span.happy { color:pink;
font-family:'Comic Sans MS';
font-size:120% }
Im HTML-Dokument selbst könnte dann stehen
Nebenkosten monatlich CHF 120Monatliche Miete CHF 1'390
Wir könnten nun Inhalte der CSS-Klasse happy aus dem HTML-Dokument abfragen. Um daraus die Mieten zu extrahieren müssen wir mit regular expressions arbeiten (library(stringr) aus tidyverse).
Let’s scrap
Öffnen Sie nun die URL: https://www.immoscout24.ch/de/wohnung/mieten/plz-4600-olten?pn=1 in einem Browser. Anschliessend drücken Sie mit einem Rechtsklick auf das Sie interessierende Element (Die gut 160 gefundenen Wohnungen, Stand 24.11.2025) und wählen dann Element untersuchen oder Untersuchen.
Unser Element hat folgenden Tag resp. CSS-Selektor (gefunden über CSS-Selektor kopieren):
MERKE
In R werden diese CSS-Selektoren nach einem anderen Schema benannt und es kann schwierig sein, den korrekten CSS-Selektor zu finden. Wichtig ist:
- Website-Betreiber mögen es nicht so gerne, wenn Ihre Website gescraped wird, und so werden die Namen der Selektoren häufig geändert!!
- Es gibt manuelles Web-Scraping: Beim manuellen Web-Scraping verwenden Sie R, um HTTP-Anfragen an eine Website zu senden und den HTML-Quellcode der Seite herunterzuladen. Sie können dazu das Paket httr verwenden, um HTTP-Anfragen durchzuführen, und rvest oder xml2, um den heruntergeladenen HTML-Code zu analysieren und die gewünschten Daten zu extrahieren. Mit
rvestkönnen Sie CSS-Selektoren verwenden, um gezielt nach bestimmten Elementen auf der Seite zu suchen und Informationen zu extrahieren. Diese Methode erfordert eine gewisse manuelle Anpassung, da Websites unterschiedlich aufgebaut sind und sich die HTML-Struktur ändern kann. Der Vorteil dieser Methode ist die hohe Geschwindigkeit, es muss aber je nachdem auch das Packagepolitefür ‘höfliches’ Scraping verwendet werden. - Es gibt Webscraping mit Browser-Steuerung: Diese Pakete wie
RSeleniumoderphantomJSbieten Funktionen und Methoden, um Webseiten auf strukturierte Weise zu durchsuchen und Daten zu extrahieren. Zum Beispiel ermöglichtrvestdas einfache Extrahieren von Informationen aus HTML-Dateien mithilfe von CSS-Selektoren, währendRSeleniumautomatisiertes Scraping ermöglichen und auch mit JavaScript-interaktiven Websites umgehen kann. Der Vorteil dieser Methode ist, dass die Chance geringer ausfällt, von der Zielseite als Bot erkannt zu werden.
Wir werden die zweite Methode in diesem Tutorial verwenden - Scraping mit RSelenium
Eine BITTE:
Der Website-Betreiber merkt, wenn wir zu exzessiv scrapen. Er wird dann Gegenmassnahmen einleiten, unter anderem die notwendige Wartezeit pro Abfrage erhöhen oder er wird die CSS-Selektoren regelmässiger ändern. Im schlimmsten Fall werden sogenannte honey pots erstellt, wo wir, insofern als Bot erkannt, die Website crawlen können aber die falschen Ergebnisse angezeigt werden - die Extraktion der Daten ist dann naütrlich nicht mehr interessant…
Um Komplikationen zu vermeiden, verwenden wir eine andere Zielseite, nämlich nicht Homegate selbst, sondern eine auf RAPP angelegte Webpage zu Mietpreisen von Wohnungen.
Unsere Zielseite findet sich hier:
Der relevante Link lautet, bitte kopieren:
Die Webpage erfordert das dynamische Setzen der Postleitzahl - wir wollen 4600 Olten scrapen. Warum? Wenn wir die Postleitzahl 4600 wählen, so ist diese nicht im URL für die Seite ersichtlich. Das heisst, die Postleitzahl muss mittels Java-Script gesetzt werden. Aufgaben wie dies fordert typischerweise Scraping mit RSelenium (dynamische Inhalte). Statische Inhalte können mit rvest bezogen werden. Scraping mit rvest ist viel schneller, aber um einiges weniger flexibel.
Wir starten den Selenium-Browser mit folendem Code:
- Löscht alte Objekte
remote_driverunddriveraus dem Workspace. - Führt
gc()aus, um ungenutzten Speicher freizugeben. - Startet einen Firefox-Webdriver mit
rsDriver():- Browser = Firefox
- Port = 9515
- Aktuelle Versionen von Selenium/Gecko werden verwendet
- Firefox wird ohne spezielle Start-Argumente geöffnet
- Speichert den Selenium-Client in
remote_driver. - Öffnet den Browser.
- Löscht alle Cookies im Browser.
- Setzt
mainurlauf die ImmoPage der FHNW. - Navigiert mit Selenium/Firefox zur angegebenen URL.
Dynamisches Scrapen einer PLZ (4600 Olten)
Dynamische Wahl der Postleitzahl (z.B. 4600 Olten)
Wir setzen nun dynamisch die Postleitzahl im Input-Feld PLZ.
Dies erreichen wir mit untenstehendem Code. Zusätzlich extrahieren wir noch alle Elemente, die überhaupt in diesem Feld setzbar wären und extrahieren diese in den Vektor myplzs.
Mit untenstehendem Code steuern wir das Feld entsprechend an. Setzen Sie besonderes Augenmerk auf den relevanten CSS-Selektor: div.selectize-control.multi.plugin-selectize-plugin-a11y
- Wartet 3 Sekunden, damit die Webseite vollständig geladen ist.
- Sucht das PLZ-Auswahlfeld (Selectize-Element) per CSS-Selector.
- Markiert das Element visuell (
highlightElement()). - Klickt das PLZ-Auswahlfeld an, um es zu öffnen.
- Liest alle verfügbaren PLZ-Werte aus dem Dropdown aus und speichert sie in
myplzs. - Findet das Eingabefeld innerhalb der Selectize-Komponente.
- Setzt die gewünschte PLZ (
plz) und den Ortsnamen (name). - Schickt die PLZ in das Eingabefeld via
sendKeysToElement(). - Bestätigt die Eingabe mit der Enter-Taste (
\uE007). - Führt einen zusätzlichen Klick aus, um die Auswahl zu fixieren.
Pseudo-Code zum Ziehen der Daten
Wir sind nun soweit, dass die relevante Postleitzahl, von welcher wir Daten beziehen wollen, im Selenium-Browser angewählt ist.
Zusätzlich sehen wir…,
- …dass die Informationen zur PLZ 4600 Olten auf 14 Seiten angelegt ist \(\rightarrow\) dies wird unsere Laufvariable
page.
- …dass pro angewählter Seite (maximal) 10 Inserate gelistet sind \(\rightarrow\) dies wird unsere Laufvariable
i.
- …dass ein Inserat zuerst geklickt werden muss, damit die vollen Informationen ersichtlich sind
Den Sachverhalt ist in untenstehender Abbildung dargestellt:
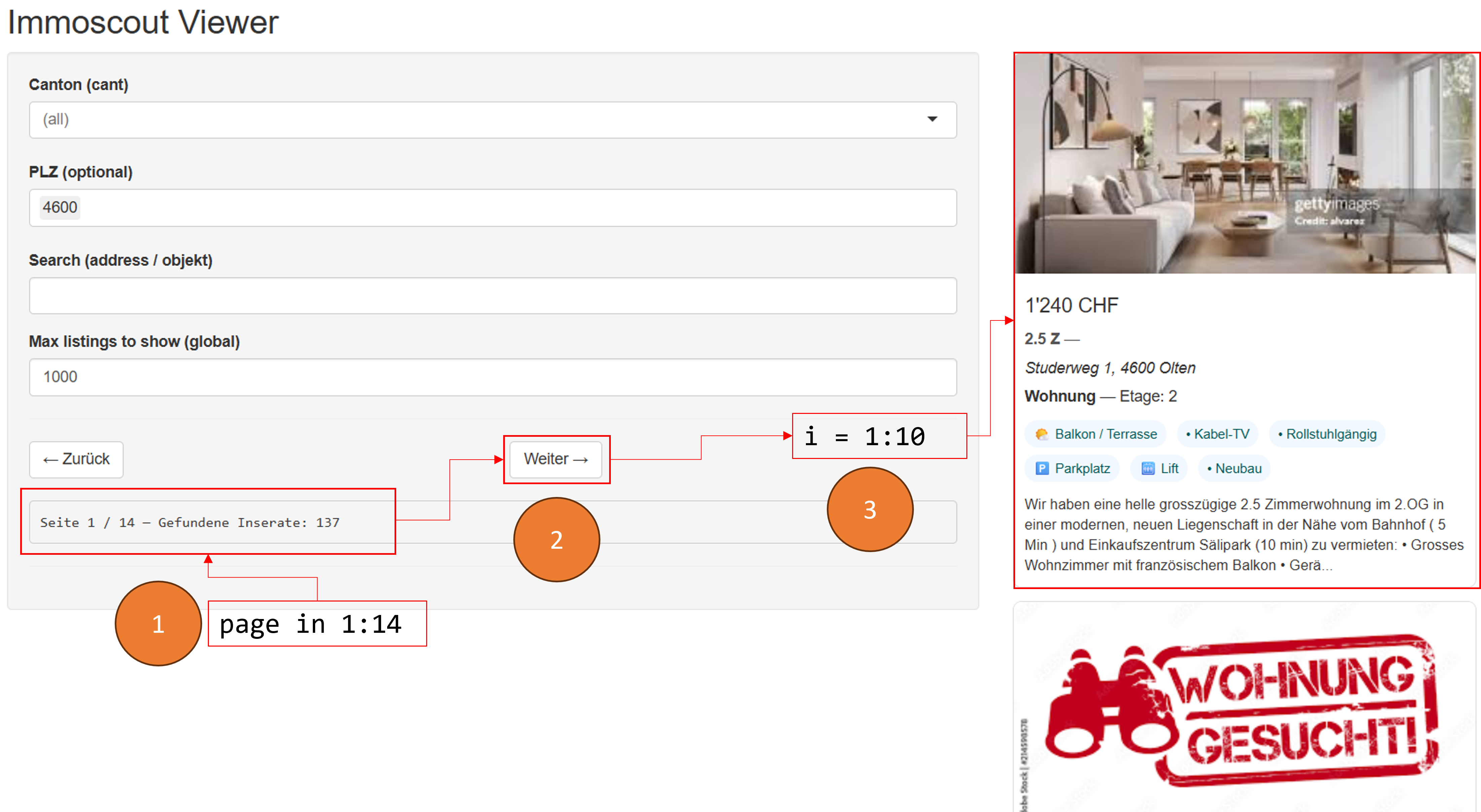
Als erstes müssen wir einen loop über die Seiten anlegen. Dabei geht die Laufvariable page von 1 bis 14.
Wir schreiben unten einen loop, der für page von 1-14 geht und die Zahl der page zurück gibt. Schreib im loop als Kommentar, was innerhalb des loops zu tun wäre.
for(page in 1:14){
print(paste("Ich bin auf Seite ",page,sep=""))
# jetzt auf jeder Seite durch die Inserate i = 1 bis 10 klicken
# von den Inseraten zuerst den Rohtext extrahieren...
# wenn beim letzten Inserat (i=10) angelangt auf den Button "Weiter->" klicken
}Das Setzen von 14 als Ende für den loop ist dabei aber nicht prakatisch. Wenn wir eine andere Postleitzahl scrapen, z.B. 6900 Lugano, so hätte diese Suche mehr oder weniger Seiten als 14. Wir müssen also das Maximum der Seiten dynamisch setzen über maxpage über den relevanten CSS-Selektor:
mypages <- remote_driver$findElements("css","#page_info")
Das Vorgehen sehen wir in untenstehendem Code:
Überführen des Pseudo-Code in funktonsfähigen Code
Nun wollen wir obigen Pseudo-Code noch lauffähig machen.
Hierzu schauen wir uns etwas detaillierter nun folgenden untenstehenden Code an und beschreiben, was er tut:
Der Code…
Iteriert über alle Seiten (
1:maxpage) und über bis zu 10 Inserate pro Seite, um jede Anzeige systematisch abzuarbeiten.Sucht das jeweilige Inserat anhand eines CSS-Selectors (
div.card:nth-child(i)) und klickt es an, sofern es existiert.Öffnet das erscheinende Modal-Fenster, extrahiert dessen Textinhalt und speichert ihn in einem Vektor
mytext.Schliesst das Modal anschliessend über den entsprechenden Button im Footer.
Nach Verarbeitung aller Inserate einer Seite klickt das Skript den “Weiter”-Button (
#btn_next), um auf die nächste Seite zu springen.Arbeitet mit kurzen Wartezeiten (
Sys.sleep()), um Ladezeiten der Webseite zu berücksichtigen und Fehler durch zu schnelles Scrapen zu vermeiden.
Das eigentliche Scraping wäre hier schon zu Ende - nun geht es darum, die Daten aus dem Vektor mytext in einem sauberen data.frame zu speichern.
Daten-Verarbeitung aus mytext
Die Daten aus mytext beinhalten folgende Informationen:
Wohnung — Zelglistr. 3, 4600 Olten 1’320 CHF 3.5 Z — 67 m2 Etage: ? 🐶 Haustiere erlaubt 🌤️ Balkon / Terrasse • Kabel-TV 👶 Kinderfreundlich 🚗 Garage • Altbau Beschreibung: Bei Mietvertragsabschluss schenken wir Ihnen einen Migros- oder Coop-Gutschein im Wert von CHF 1’000.00!
Wir vermieten diese helle Wohnung in einem ruhigen Quartier. Hier einige Highlights:
- Parkettböden in Wohn- und Schlafzimmer
- Geschlossene Küche
- Bad mit Badewanne und Lavabo
- Lichtdurchflutetes Wohnzimmer
- Heller Essbereich
- Gut möbilierbarer Grundriss
- Keller vorhanden
- Nähe Bushaltestelle, Einkaufszentrum Sälipark und Schulen
- Eine Garage kann für CHF 150.– dazu gemietet werden
Bitte beachten Sie, dass die Fotos vom Original abweichen können.
Haben wir Ihr Interesse geweckt? Wir freuen uns auf Ihre Kontaktaufnahme! Schliessen
Uns interessieren vor allem folgende Variablen / Grössen:
objekttyp: Wohnungmiete: 1320zimmer: 3.5wohnflaeche: 67etage: ?ausstattung: Haustiere erlaubt, Balkon / Terrasse, Kabel-TV, Kinderfreundlich, Garage, Altbaubeschreibung: Bei Mietvertragsabschluss schenken wir Ihnen einen Migros- oder…
Extraktion aus Text-Daten: Regular-Expressions
Wir extrahieren die relevanten Variablen nun mit folgendem Code:
mytextwird zuerst mitunlist()in einen einfachen Character-Vektor umgewandelt, damit jeder Eintrag ein Rohtext eines Inserats ist.- Aus diesem Vektor wird ein tibble
dferzeugt, das in der Spalterawjeweils den kompletten Text eines Inserats enthält. - Mit mutate() werden anschliessend strukturierte Variablen über Regular Expressions extrahiert:
objekttyp:- Regex:
^[^—]+ - Bedeutung: Wählt vom Anfang der ersten Zeile (^) alle Zeichen bis zum Gedankenstrich — aus.
- Zweck: Extrahiert die Objektbezeichnung, z. B. Wohnung.
- Regex:
adresse:- Regex:
(?<=— ).*?(?=\\n) - Bedeutung:
(?<=— )findet die Position direkt nach „— “ (positiver Lookbehind)..*?nimmt so wenige Zeichen wie möglich (lazy)(?=\n)stoppt beim nächsten Zeilenumbruch (Lookahead).
- Zweck: Adresse und Ort aus der ersten Zeile extrahieren.
- Regex:
miete:- Regex:
\\d[\\d' ]*(?= *CHF) - Bedeutung:
\\dbeginnt mit einer Ziffer[\\d' ]*danach beliebig viele Ziffern, Leerzeichen oder ’ (für Tausendertrennungen)(?= *CHF)stoppt vor “CHF”, aber ohne es mitzunehmen
- Zweck: Miete erfassen
- Regex:
zimmer:- Regex:
(?<=\\n)[0-9\\.]+(?= *Z) - Bedeutung:
(?<=\n)nach einem Zeilenumbruch[0-9\.]+eine oder mehrere Ziffern oder Punkte (z. B. “2.5”)(?= *Z)endet unmittelbar vor “Z” (für “Zimmer”)
- Zweck: Zimmerzahl extrahieren
- Regex:
wohnflaeche:- Erster Schritt:
(?<=— ).*?([0-9]+) *m2 - Sucht im Block nach dem — nach einer Zahl, gefolgt von “m2”.
- Zweiter Schritt:
str_extract("[0-9]+")extrahiert nur die Zahl. - Zweck: Wohnfläche (m²) numerisch extrahieren.
- Erster Schritt:
etage:- Regex:
(?<=Etage: ).*?(?=\\n) - Bedeutung:
(?<=Etage: )startet nach “Etage:”.*?beliebiger Text(?=\n)bis zum nächsten Zeilenumbruch
- Zweck: Etagenangabe auslesen
- Regex:
ausstattung:- Regex:
(?s)Etage:[^\n]*\\n(.*?)(?=Beschreibung:) - Bedeutung:
(?s)Single-line-Mode (.darf auch Zeilenumbrüche matchen)Etage:[^\n]*\nsucht die Zeile nach “Etage:”(.*?)alles danach, so wenig wie möglich(?=Beschreibung:)endet vor “Beschreibung:”
- Zweck: Der gesamte Ausstattungstext
- Regex:
beschreibung:- Regex:
(?s)(?<=Beschreibung:\\n).* - Bedeutung:
(?s)Single-line-Mode(?<=Beschreibung:\n)startet nach “Beschreibung:” + Zeilenumbruch.*alles bis zum Ende
- Regex:
Koordinaten berechnen
Wir würden die Daten gerne auf einer Karte darstellen. Dafür brauchen wir auf einer Karte die Geo-Koordinaten und wollen die aus den Adressen extrahieren. Hierfür gibt es mehrere Methoden:
- Extrahiere die Koordinaten selbst (mit Google-Maps etc.)
- Extrahiere die Koordinaten mit Google-Cloud oder Amazon-Web-Services (AWS) (kostenpflichtig)
- Nutze ein Gratis-API, e.g. vom Bundesamt für Landestopographie
Wir bedienen uns der dritten Möglichkeit.
Die Funktion, die dabei genutzt wird, ist selbst geschrieben und findet sich hier:
Was ist eine API?
- Eine API (Application Programming Interface) ist eine standardisierte Schnittstelle, über die Programme oder Dienste automatisch miteinander kommunizieren können.
- Sie erlaubt es, Daten von einem externen Server abzurufen, ohne dass man eine Website manuell öffnen muss.
- APIs nehmen Anfragen (Requests) an, verarbeiten sie und schicken Antworten (Responses) zurück, meistens in Form von JSON.
- APIs werden genutzt, um Funktionen, Daten oder Services bereitzustellen, z.B. Geokoordinaten, Wetterdaten, Kartendaten, KI-Antworten usw.
- Eine API stellt sicher, dass Programme zuverlässig, reproduzierbar und strukturiert Informationen austauschen können.
Was macht die Funktion get.coordinates()?
- Nimmt eine Adresse als Eingabe und baut daraus eine Anfrage (
body) für die API SearchServer von geo.admin.ch, dem Schweizer Geo-Informationsdienst. - Sendet mit
GET()eine HTTP-Anfrage an die API-URL https://api3.geo.admin.ch/rest/services/api/SearchServer und übergibt die Adresse als Suchparameter (searchText). - Prüft, ob die API-Antwort (
httr::content(r)) mindestens ein Suchresultat enthält. - Wenn ein Resultat vorhanden ist:
- Extrahiert daraus Latitude (
lat), Longitude (lon), sowie die Landeskoordinaten (x,y) des ersten Treffers. - Speichert diese Werte zusammen mit der ursprünglichen Adresse in einem data.frame
- Extrahiert daraus Latitude (
- Wenn kein Resultat gefunden wird oder die Adresse fehlt:
- Gibt einen Data Frame zurück, bei dem alle Koordinaten
NAsind. - Die Funktion gibt immer ein Data Frame mit genau einer Zeile zurück, egal ob Treffer oder nicht.
- Gibt einen Data Frame zurück, bei dem alle Koordinaten
get.coordinates<-function(address){
body<-list(searchText=address,origins='address',type='locations')
r <- GET("https://api3.geo.admin.ch/rest/services/api/SearchServer",
query = body)
if(length(httr::content(r)$results)>0 & !is.na(address)){
lat <- httr::content(r)$results[[1]]$attrs$lat
lon <- httr::content(r)$results[[1]]$attrs$lon
xx <- httr::content(r)$results[[1]]$attrs$x
yy <- httr::content(r)$results[[1]]$attrs$y
df<-data.frame(address=address,lat=lat,lon=lon,x=xx,y=yy)
}
else{
df<-data.frame(address=address,lat=NA,lon=NA,x=NA,y=NA)
}
return(df)
}get.coordinates<-function(address){
body<-list(searchText=address,origins='address',type='locations')
r <- GET("https://api3.geo.admin.ch/rest/services/api/SearchServer",
query = body)
if(length(httr::content(r)$results)>0 & !is.na(address)){
lat <- httr::content(r)$results[[1]]$attrs$lat
lon <- httr::content(r)$results[[1]]$attrs$lon
xx <- httr::content(r)$results[[1]]$attrs$x
yy <- httr::content(r)$results[[1]]$attrs$y
df<-data.frame(address=address,lat=lat,lon=lon,x=xx,y=yy)
}
else{
df<-data.frame(address=address,lat=NA,lon=NA,x=NA,y=NA)
}
return(df)
}
get.coordinates("Von Roll-Strasse 10, 4600 Olten")Besonders interessant ist hier die elegante Anwendung der Funktion get.coordinates.
Schreiben Sie einen data.frame mydf mit adresse Tiefengrabenstrasse XY, 4102 Binningen, wobei die Hausnummer XY über 30, 32, 34, 36, 38 geht.
mydf <- data.frame(adresse = paste("Tiefengrabenstrasse ",seq(30,38,2),", 4102 Binningen",sep=""))
coors <- lapply(mydf$adresse,get.coordinates) %>% bind_rows(.)
ggplot(data = coors) + geom_point(aes(x = lon, y = lat)) + theme_void()
# oder, viel schöner
leaflet(coors) %>%
addTiles() %>%
addCircleMarkers(
lng = ~lon,
lat = ~lat,
radius = 5,
popup = ~address
)Auf Karte visualisieren
Nun wollen wir die Wohnungen noch auf einer Karte mittels Punkten visualisieren. Dies machen wir mit dem Package leaflet.
Ein Beispiel hierzu findet sich gleich untenstehend:
- Versuche, Dein eigenes Scraping-Projekt zu verfolgen.
- Löse im Mock-Exam die Aufgabe zu Web-Scraping (Meteo)