
Tools in DataScience 10: Verwendung von R für SQL Datenbankbearbeitung
Hinweis:
- An jenen Stellen, die mit einem Graduation-Cap gekennzeichnet sind , erarbeiten Sie sich die Inhalte selbständig
- An Stellen mit einer Wandtafel warten Sie bitte auf Input seitens der Dozierenden
Worum geht es in dieser Sitzung:
Sie werden heute lernen, was Datenbanken sind und wie Sie mit R relationale Datenbanken erstellen, verändern bzw. bearbeiten und diese wieder speichern können.
Einführung in Datenbanken
Die durch Computer gestützte Optimierung von Arbeitsabläufen basiert oft auf grossen Datenmengen. Speichert man die Daten jeweils separat in den verschiedenen Programmanwendungen verschiedener Verwaltungseinheiten o.ä.(bspw. Abteilungen eines Unternehmens wie “Personal”, “Buchhaltung”, …), führt dies i.d.R. jedoch zu Nachteilen wie bspw. der Mehrfachspeicherung von Informationen, erhöhtem Aufwand bei Änderungen von Dateneinträgen (da man in allen Dateien der verschiedenen Programmanwendungen einzeln ändern muss) oder der eingeschränkten Nutzung durch mehrere Nutzer.
Man umgeht diese und weitere Probleme, indem (strukturierte) Datenbanksysteme (DBS) für die Datenspeicherung und Verwaltung verwendet werden. Ein DBS besteht aus 2 Teilen:
Den Datenbanken, die wiederum aus logisch zusammengehörigen Daten zu einem Sachgebiet bestehen und gemäss ihrer Zusammenhänge in der “realen Welt” hinterlegt sind. Es können mehrere Benutzer gleichzeitig auf eine Datenbank zugreifen (aber nur bedingt zeitgleich dieselben Einträge bzw. Datensätze bearbeiten).
Dem Datenbankmanagementsystem, DBMS, welches als Datenbanksoftware die Datenbanken verwaltet (erstellen, andern,speichern).
Es gibt verschiedene Datenbankmodelle, wobei relationale Datenbanken - siehe folgende Beispielgrafik - am häufigsten verwendet werden.
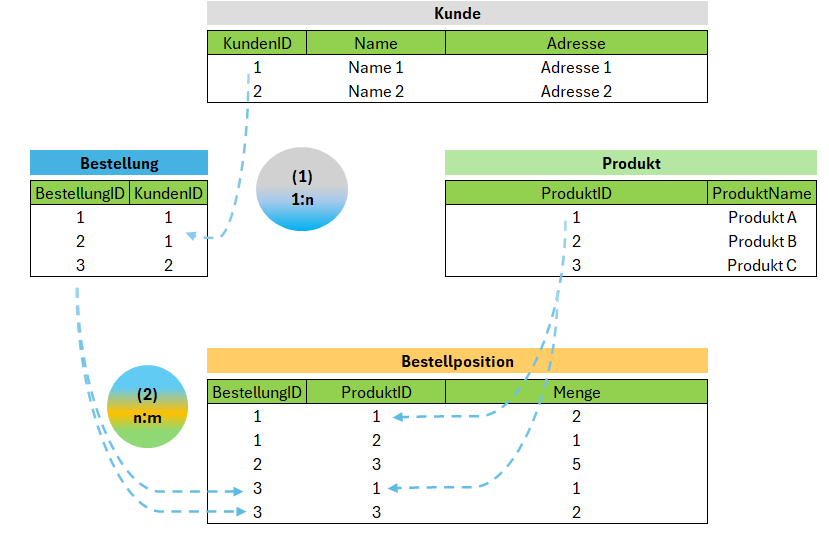
Die obige Abbildung (eigene Darstellung) zeigt Daten aus einer Datenbank (Ablauf: KundIn gibt eine Bestellung auf. Die Bestellung enthält eines oder mehrere Produkte.).
Die Tabellen sind jeweils über “Schlüssel” miteinander verbunden. Dabei hat jeder Datensatz (Eintrag in einer Zeile, bspw. ein Kunde) genau einen “Primärschlüssel” (bspw. “KundenID” in der Tabelle “Kunde”), der einen Datensatz eindeutig kennzeichnet. Sind weitere Schlüssel enthalten, so nennt man diese “Sekundärschlüssel” (bspw. “Name” in der Tabelle “Kunde”, da so der Kundenname nur einmalig verwendet werden kann). Sind in einer Tabelle “Primärschlüssel” einer anderen Tabelle enthalten, nennt man diese “Fremdschlüssel”. Im obigen Beispiel enthält die Tabelle “Bestellposition” die Fremdschlüssel “BestellungID” und “ProduktID” und stellt die Referenz zwischen den Tabellen “Bestellung” und “Produkt” her. Die beiden genannten Fremdschlüssel bilden einen zusammengesetzten Primärschlüssel.
Zudem sind die Beziehungen (Relations) zwischen den Objekten (Entitäten) in Form von Linien und unter Angabe der Art der jeweiligen Beziehung, d.h. einer 1:1, 1:n oder n:m Beziehung dargestellt. Die Relationen der Entitäten “Kunde-Bestellung_Produkt” können in einem Modell (ERM) wie folgt zusammengefasst werden:
- Beziehung “Kunde zu Bestellung”: “1:n”; Kunden können mehrere Bestellungen haben, eine Bestellung hat aber nur einen Kunden.
- Beziehung “Bestellung zu Produkt”: “n:m”; Eine Bestellung kann mehrere Produkte enthalten und ein Produkt kann in mehreren Bestellungen vorkommen.
Datenzugriff und Datenauswertung relationaler Datenbanken erfolgen dabei meist über die Abfragesprache (Structured Query Language) “SQL”.
Mit SQL kann man (strukturierte) Datenbanken erstellen, abfragen, aktualisieren und generell Daten verwalten. Dies ist auch mit R möglich, wobei Client-Server oder auch lokale DBS Konzepte möglich sind.
Meist arbeiten DBS nach dem Client-Server-Konzept, d.h. ein Client stellt eine Anforderung an den Server, dieser bearbeitet sie und gibt eine Antwort zurück. Bspw. würde ein Anwendungsprogramm (bspw. auf einem Computer “A”) eine Anfrage an die Datenbank senden und der (hier: SQL) Server, der meist dem DBMS entspricht, (bspw. auf einem Computer “B”) schickt die ausgewählten Daten an das Anwendungsprogramm zurück.
Bei Anwendungen mit hohen Anforderungen an gleichzeitige Verbindungen, bei großen Datenmengen oder wenn viele Benutzer gleichzeitig auf die Datenbank zugreifen müssen sind relationale Datenbanksysteme wie MySQL oder PostgreSQL geeignet.
Für unsere folgende Beispielanwendung in R verwenden wir eine SQLite Datenbank. SQLite wird als eingebette SQL-Datenbank-Engine (Softwarekomponente des DBMS) sehr häufig verwendet. Im Gegensatz zu den meisten anderen SQL-Datenbanken müssen Sie keinen separaten Datenbankserver einrichten. SQLite liest und schreibt direkt in gewöhnliche Festplattendateien (weiterführende Informationen erhalten Sie bei: https://www.sqlite.org). Zudem ist SQLite bereits vollständig in ein R-Paket eingebettet und braucht keine Installation weiterer (teils kostenpflichtiger) Software.
Bearbeitung relationaler Datenbanken mit R
Installation der relevanten R-Packages
Um mit einer Datenbank aus R heraus zu kommunizieren bietet R mehrere packages an, wobei wir das package DBI in Verbindung mit RSQLite (bzw. odbc für generellen Zugriff auf ODBC-Treibern) verwenden. Das DBI-Paket ist eine Schnittstelle zu all jenen Datenbanksystemen, die einen “open database connectivity driver” (ODBC Treiber) verwenden, wie bspw. SQL Server (https://www.microsoft.com/en-us/sql-server/), Oracle (https://www.oracle.com/database), MySQL (https://www.mysql.com/), PostgreSQL (https://www.postgresql.org/) oder SQLite (https://sqlite.org/). Die DBI-kompatible Schnittstelle zu Open Database Connectivity (ODBC)-Treibern bietet, allgemein, das “odbc-Paket”. Wir nutzen für unsere Zwecke hier das RSQLite-package (das odbc-package ist in diesem Fall nicht notwendig). Beide packages ermöglichen einen effizienten, einfachen Weg, um eine Verbindung zur Datenbank mit dem jeweiligen ODBC-Treiber einzurichten.
Wir installieren das DBI und RSQLite-package. Zudem verwenden wir das dbplyr-package, was Ihnen den Zugriff auf Datenbanken mittels dplyr erlaubt.
install.packages('DBI')
library(DBI)
install.packages(c('RSQLite','dbplyr'))
library(RSQLite)
library(dbplyr)Weitere Informationen finden Sie unter: https://dbi.r-dbi.org/ https://www.tidyverse.org/blog/2019/12/odbc-1-2-0/
Sie können anschliessend eine Verbindung zur gewählten Datenbank erstellen und die Daten bearbeiten (siehe nächster Abschnitt).
Dabei gibt es 2 Möglichkeiten:
Sie verwenden SQL-Syntax um mit der relationalen Datenbank zu kommunizieren. Hierzu werden wir im nächsten Abschnitt ein paar kurze Beispiele gemeinsam besprechen. Umfassende Informationen zu SQL-Syntax finden Sie u.a. unter folgendem Link: https://www.w3schools.com/sql/
Wenn Ihre Daten bereits in einer Datenbank vorliegen oder aufgrund der zu umfangreichen Grösse in eine Datenbank ausgelagert werden, empfiehlt sich die Verwendung (in Verbindung mit dem DBI-package) des
dbplyrpackage, was SQL Syntax in R Syntax (genauer: in dplyr-Syntax) übersetzt und Ihnen so die Kommunikation mit einer Datenbank ohne das zusätzliche Erlernen von “SQL” ermöglicht. Wir werden unsere Beispieldaten mit dplyr Syntax bearbeiten. Detaillierte Informationen zur verfügbaren Syntax finden Sie unter folgendem Link: https://solutions.posit.co/connections/db/advanced/translation/
Download der Beispieldatenbank
Download (hauptsächlich bei SQLite Datenbanken erforderlich, da diese Lokal gespeichert werden.)
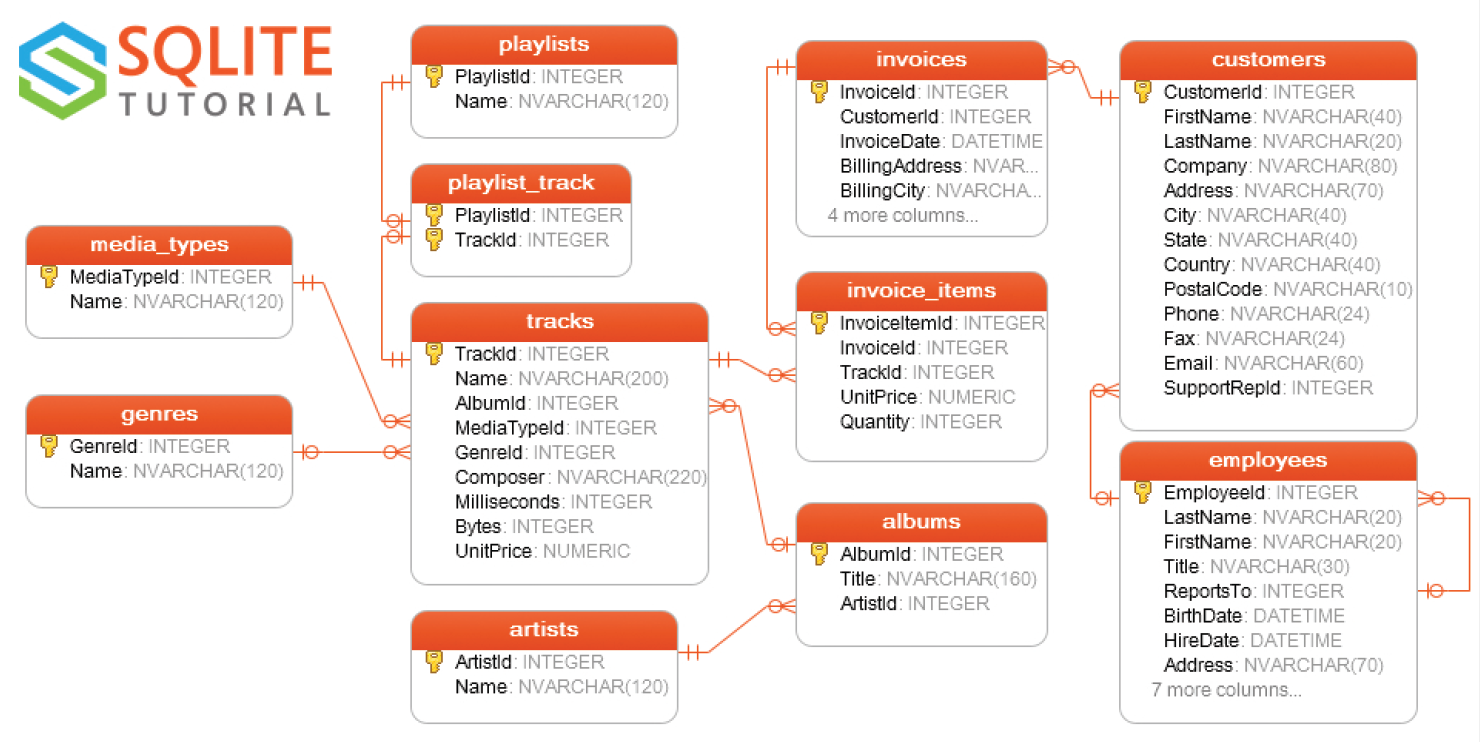
Wir laden die Daten einer SQLite Beispieldatenbank names “Chinook”, die Daten eines digitalen Medienshops enthält, und das dazugehörige Datenbankdiagramm zur Veranschaulichung:
download.file("https://www.sqlitetutorial.net/wp-content/uploads/2018/03/chinook.zip", dest="db1.zip", mode="wb") download.file("https://www.sqlitetutorial.net/wp-content/uploads/2018/03/sqlite-sample-database-diagram-color.pdf", dest="structure.pdf", mode="wb") unzip("db1.zip", exdir = ".", overwrite=TRUE) file.remove("db1.zip") system('open "./structure.pdf"')
Die Chinook-Beispieldatenbank besteht aus 11 Tabellen.
- Mitarbeiterdaten (employees)
- Kundendaten (customers)
- Kopfdaten der Rechnung (invoices)
- Rechnungspositionen (invoice_items)
- Künstlerdaten (artists)
- Albentitel (albums): 1 Künstler pro Album, mehrere Alben pro Künstler möglich.
- Medientyp (media_types)
- Genres
- Songdaten (tracks): jedes Lied gehört zu einem Album
- Daten über Wiedergabelisten (playlists): Jede Wiedergabeliste enthält eine Liste von Liedtiteln.
- Daten über Wiedergabelieder (playlist_track): Jeder Liedtitel kann zu mehreren Wiedergabelisten gehören.
Quiz zur SQLite-Beispieldatenbank
Download
Speichern Sie nun zuerst die Beispieldatenbank und das Datenbankdiagramm lokal in Ihrem Projektordner. Entweder verwenden Sie die oben gezeigte Syntax oder den folgenden Downloadbutton.
Wie schon oben erwähnt, entfällt dieser Schritt gegebenenfalls bei der Nutzung anderer Datenbanken als SQLite (bspw. MySQL), da die Anwendungen häufig direkt auf die SQL-Datenbank auf dem Server zugreifen.
- Bitte machen Sie einen Rechtsklick auf die Datei
chinook.zipund entpacken Sie die Daten in Ihrem Ordner wie folgt:
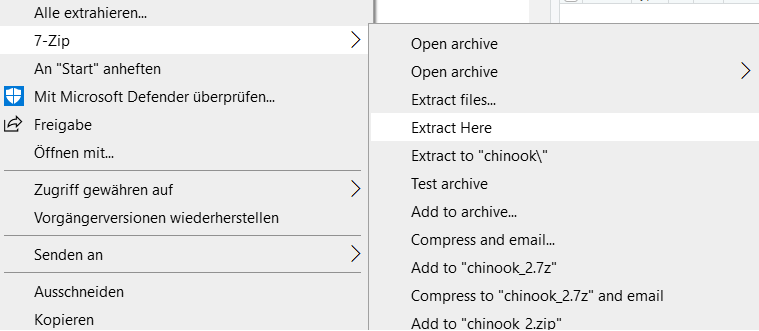
Download der Daten…
Bitte geben Sie die Daten nicht an Dritte weiter.
Vorgehensweise bei der Bearbeitung von Datenbanken und Datenbanktabellen
1. Öffnen der Verbindung mittels Funktionen des DBI packages
An dieser Stelle gibt es, wie bereits erwähnt, 2 Optionen :
a) die Verbindung mit einem externen Server
Sollten Sie diese Option verwenden wollen, kann Ihnen die IT Abteilung Ihres Unternehmens an dieser Stelle weiterhelfen.
conn <- DBI::dbConnect( odbc::odbc(), Driver = "SQL Server", Server = "ServerName", Database = "DatabaseName", uid = "UserName", pwd = "Password", options(connectionObserver = NULL))
b) die Verbindung mit der lokal gespeicherten (oder angelegten) Datenbank
Wir fokussieren im weiteren Verlauf auf die Arbeit mittels lokal hinterlegter SQLite Datenbank (hier: chinook.db). Dabei geben wir mit der Funktion dbDriver den Treiber an (SQLite) und mit der Funktion dbConnect verbinden wir R mit der Datenbank und speichern die SQLiteConnection im Objekt “con”.
drv <- dbDriver("SQLite") con <- dbConnect(drv, dbname = "./chinook.db")
Nun verschaffen wir uns mit der Funktion dbListTables einen Überblick über die in der Datenbank enthaltenen Tabellen.
dbListTables(con)## [1] "albums" "artists" "customers" "employees" ## [5] "genres" "invoice_items" "invoices" "media_types" ## [9] "playlist_track" "playlists" "sqlite_sequence" "sqlite_stat1" ## [13] "tabelle_AlbArt" "tracks"Mit der Funktion dbListFields() erhält man einen Überblick über die Variablen bzw. Spalten einer Tabelle (hier: albums).
dbListFields(con, "albums")## [1] "AlbumId" "Title" "ArtistId"
2. Abfragen (queries)
- Abfragen können mit der Abfragesprache “SQL” gemacht werden. Hier gibt es folgende Möglichkeiten:
a) Sie verwenden SQL Syntax (SQL-Syntax können Sie bspw. mit folgendem Tutorial erlernen: https://www.w3schools.com/sql/) als ‘zitierten String’ mit der dbGetQuery() - Funktion des DBI-packages für Datenbankabfragen:
Beispiel:
dbGetQuery(con, '
SELECT "Artist",
COUNT(*) AS total_albums
FROM "albums"
GROUP BY "Artist"
')b) Sie arbeiten mit dplyr. Dazu installieren und aktivieren Sie das Paket “dbplyr”. Dplyr übersetzt Ihren R-Code in SQL. Wir konzentrieren uns im Folgenden auf diese Option.
Abfragen aus einer Tabelle: Um die Daten in R weiter bearbeiten zu könne, muss man sie mit der tbl() -Funktion in eine Tabelle in R überführen. Dann kann man mit den dplyr-Funktionen select() und filter() Spalten und Zeilen einer Datentabelle der Datenbank auswählen.
Beispiel: tabelle_albums<- con %>% tbl("albums") %>% filter(AlbumId<=10) tabelle_albums %>% head()
Mit der Funktion show_query() erhält man die entsprechende SQL Syntax (nur wenn die Daten nicht als dataframe sondern als Tabelle vorliegen).
tabelle_albums %>% show_query## <SQL> ## SELECT * ## FROM `albums` ## WHERE (`AlbumId` <= 10.0)Abfragen aus mehreren Tabellen: Wenn Schlüssel zwischen den Tabellen vorhanden sind, können Abfragen auch aus mehreren Tabellen Daten in einer Abfrage vereinen.
Beispiel: Wir laden Daten aus den Tabellen “albums” und “artists”, die über die “ArtistId” verbunden werden können.
Tabelle "albums"Tabelle "artists"tabelle_AlbArt<- con %>% tbl("albums") %>% left_join(tbl(con,"artists"), by = "ArtistId") %>% group_by(ArtistId) %>% mutate(freq_Artist = n()) %>% ungroup() %>% arrange(desc(freq_Artist)) Die neue Tabelle "tabelle_AlbArt, in denen Daten zusammengeführt wurden.Wenn die Abfrage finalisiert ist, kann man mit “collect()” die Daten in einen tibble/dataframe umwandeln.
df_AlbArt <- tabelle_AlbArt %>% collect() class(df_AlbArt)## [1] "tbl_df" "tbl" "data.frame"df_AlbArt %>% head()
3. Auswertungen
Nun folgen Auswertungen, bspw. in Form einer Grafik. Wir wählen zur Übersichtlichkeit nur Artists mit >=2 Titeln aus.
Beispiel: Wir laden Daten aus den Tabellen “albums” und “artists”, die über die “ArtistId” verbunden werden können.
df_AlbArt_g <- aggregate(freq_Artist ~ Name, data = df_AlbArt, FUN = length) colnames(df_AlbArt_g) <- c("Name", "Häufigkeit") df_AlbArt_g %>% filter(Häufigkeit >= 2) %>% ggplot() + geom_bar(aes(x = reorder(Name, -Häufigkeit), y = Häufigkeit, fill = Name), stat = "identity",position = "dodge") + theme_minimal() + labs(title = "Anzahl Titel pro Künstler", x = "", y = "") + theme(axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1, size = 8), legend.position = "none") + theme(plot.margin = margin(1, 1, 1, 1, "cm"))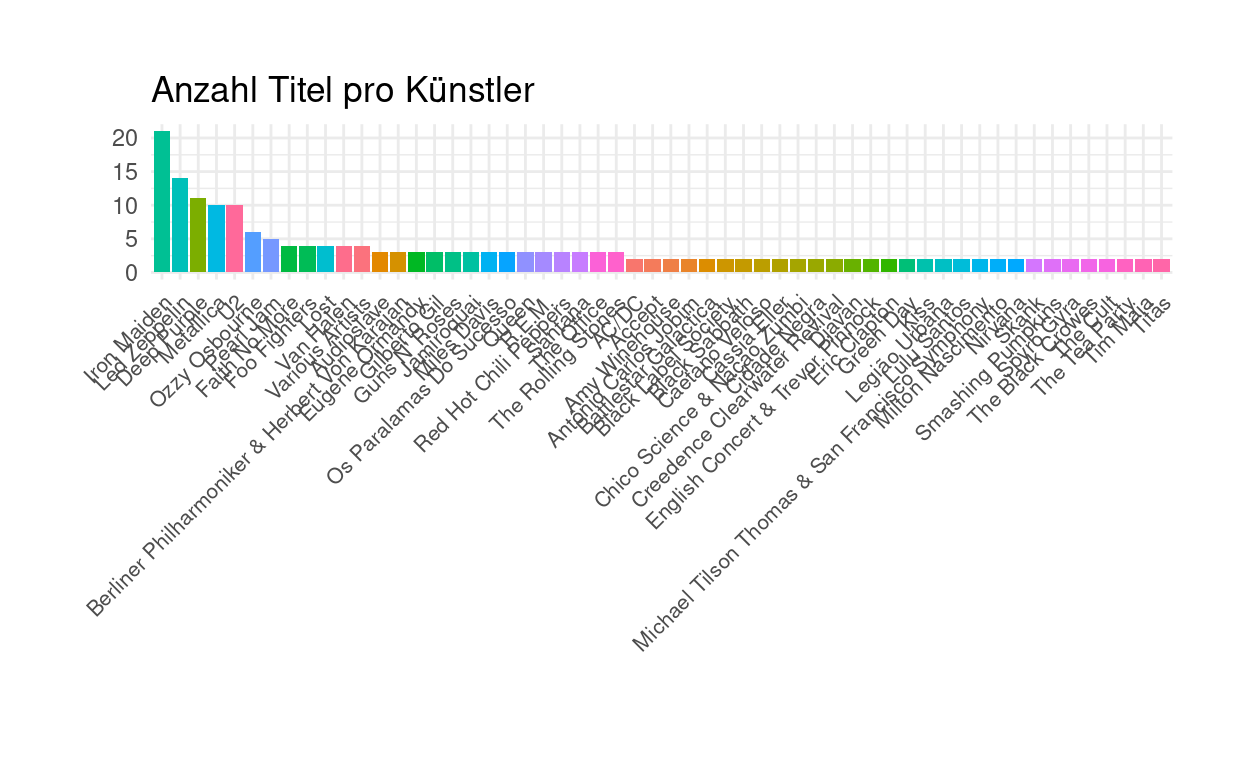
4. Hinzufügen von Tabellen und Schliessen der Datenbankabfrage
Wir speichern den erstellten tibble “df_AlbArt” in der SQLite Datenbank und schliessen die Verbindung.
dbWriteTable(con, "tabelle_AlbArt", df_AlbArt, overwrite = TRUE) dbListTables(con)## [1] "albums" "artists" "customers" "employees" ## [5] "genres" "invoice_items" "invoices" "media_types" ## [9] "playlist_track" "playlists" "sqlite_sequence" "sqlite_stat1" ## [13] "tabelle_AlbArt" "tracks"dbDisconnect(con)
Übung I
Laden Sie nun das R-Skript zur lokalen Bearbeitung der folgenden Übungsaufgaben herunter und speichern Sie es lokal in Ihrem Projektordner.
Lösen Sie die folgenden Übungsaufgaben und vervollständigen Sie das Skript Schrittweise nach jeder Übungsaufgabe.
Bei den Aufgaben ist es sicher hilfreich, wenn Sie die Syntax zur Lösungsfindung jeweils lokal bei sich in R ausprobieren.
1. Verbindung zur Datenbank herstellen
Sie wollen eine Verbindung zur “chinook” SQLite - Datenbank herstellen. Sie liegt im Ordner “www”, welcher sich in Ihrem Arbeitsverzeichnis befindet.
2. Struktur der Datenbank
3. Auswahl und Verbinden der Tabellen “genres” und “tracks”
Lassen Sie sich die in der SQLite-Datenbank “chinook” enthaltenen Tabellen auflisten. Verbinden Sie danach die Tabellen “genres” und “tracks” mit der Funktion “left_join()” über die Spalte “GenreId” und speichern Sie sie in einer neuen Tabelle “t2”. Inspizieren Sie zur Prüfung die Kopfzeile von “t2”.
dbListTables(con)
t2<-
con %>%
tbl("genres") %>%
left_join(tbl(con, "tracks"), by = "GenreId")
t2 %>% head()
4. In Tibble umwandeln und speichern in Datenbank.
Nachdem Sie die Daten weiterverarbeitet haben, wurden sie in der Tabelle t_fin gespeichert. Wandeln Sie die Tabelle “t_fin” in einen tibble um - behalten Sie den Namen bei. Speichern Sie “t_fin” unter seinem Namen in der Datenbank. Prüfen Sie ob t_fin nun in der Datenbank enthalten ist. Schliessen Sie danach die Verbindung zur Datenbank.
t_fin <- t_fin %>% collect()
dbWriteTable(con, "t_fin", t_fin, overwrite = TRUE)
dbListTables(con)
dbDisconnect(con)
Laden Sie nun das aktualisierte R-Skript herunter und speichern Sie es lokal in Ihrem Projektordner.