
Tools in DataScience 5: Grafiken
Hinweis:
- An jenen Stellen, die mit einem Graduation-Cap gekennzeichnet sind , erarbeiten Sie sich die Inhalte selbständig
- An Stellen mit einer Wandtafel warten Sie bitte auf Input seitens der Dozierenden
Worum geht es in dieser Sitzung:
Wir haben uns in den letzten Sitzungen mit strukturellen Aspekten und der “Fertigstellung” unseres Beispieldatensatzes beschäftigt.
In dieser Sitzung gehen wir auf die grafische Inspektion der Daten ein. Grafiken ermöglichen es Ihnen, sich schnell einen Überblick über Entwicklungen, mögliche Zusammenhänge zwischen Variablen oder auch Unterschiede zwischen bestimmten Gruppen zu verschaffen.
Zudem sind Grafiken für die Präsentation von Ergebnissen sehr wichtig.
Wir nutzen das package ggplot2, was Daten im long-Format vorraussetzt. Es wird meist, gerade beim Einstieg in die Datenvisualisierung mit R, gegenüber R Base Graphics bevorzugt, da die Anpassung der Grafiken etwas leichter ist.
Erstellen von Grafiken in R mit ggplot2
Installation des ggplot2 packages
Für das Erstellen von Grafiken in R gibt es sehr viele Möglichkeiten (bspw. Base R oder die packages “grid” oder “lattice”).
Wir beschäftigen uns mit dem package ggplot2 (als Teil der tidyverse-package Sammlung), da es die Grafiken in Teilobjekte zerlegt und diese für uns einfach und verständlich zugänglich sind.
Mithilfe der Funktionen des *ggplot2 - package** in RStudio können wir u.a. Balken-, Histogramme, Boxplots, Streudiagramme und Liniendiagramme erstellen.
Voraussetzung für die Verwendung des packages ist, dass die Daten - wie in unserem Beispiel - im long-Format vorliegen.
Wir installieren das package und laden die Bibliothek.
install.packages("ggplot2")
library(ggplot2)Weitere Informationen zum “ggplot2 - package” finden Sie unter:
https://ggplot2.tidyverse.org/
Dort können Sie auch das entsprechende cheat sheet herunterladen: https://raw.githubusercontent.com/rstudio/cheatsheets/main/data-visualization.pdf
Das Grundprinzip der Grafikerstellung mit ggplot2
1. Wir übergeben unseren Datensatz an ein Grafikobjekt mit der Funktion ggplot().
2. Wir bestimmen die aesthetic mappings mit der Funktion aes(). Es werden die Diagrammvariablen und ihre Achsenzuweisung, Gruppierungsvariablen und die visuellen Eigenschaften der im Diagramm angezeigten Daten festgelegt. Die Zuweisung der aes() kann global oder lokal vorgenommen werden.
Globale Zuweisung der aes() in der Funktion
ggplot(): Wählt manglobal, gelten die Definitionenfür alle Schichtenbzw. Elemente.
Setzt man ein Diagramm aus mehreren Elementen - bspw. Balken und Punkten - zusammen, gilt die in den “aes()” mit bspw. “fill” global festgelegte Füllfarbe (für Körper) für die Balken und die Punkte.Lokale Definitionen setzt man in der(den) Funktion(en) von
geom_...()(bspw. geom_bar() im Falle eines Balkendiagramms):
Man braucht sie, weil man:- der jeweiligen Schicht spezifische Definitionen hinzufügen möchte
- die globalen Einstellungen überschreiben möchte
- Diagramme mit Daten aus verschiedenen Datenquellen konstruiert, also nicht global die gleichen Variablen für alle Diagrammschichten nutzt
- verschiedene Grafikarten in einem Diagramm vereint - bspw. eine Linie in ein Streudiagramm einfügt.
Wenn es keine zwingenden sachlogischen Argumente gibt einen der beiden Fälle (global oder lokal) wählen zu müssen, bleibt es Ihnen überlassen. Wir werden hier beide Varianten behandeln.
Einige wichtige Gestaltungsparameter in aes() sind:
shape= Form des mit geom_point() angezeigten Datenelement (Punkt, Stern, …)fill= Füllfarbe von Körpern (Balken, Punkten, …)color= Aussenlinie eines Balkens, Boxplots oder Punktfarbe (bei Nutzung geom_point())size= bspw. Dicke einer Linie, Grösse eines Punktesalpha= Transparenz der Symbole (bspw. Balken)binwidth= Breite der Balken (Klassen) im Histogrammwidth= Breite der Balken im Balkendiagrammlinetype= Linientyp
3. Abschliessend fügt man mit dem + Zeichen die Schichten hinzu. Man beginnt für gewöhnlich mit der Funktion geom_ (geom_bar, geom_line, …), um den Diagrammtyp festzulegen (Balken, Linie, …). Hiernach könnten bspw. weitere Linien, Punkte etc. eingefügt werden, die weitere Sachverhalte veranschaulichen.
Die detaillierte (Nach)Bearbeitung des jeweiligen Diagrammtyps ist sehr vielfältig, sodass wir hier nur die für unser Beispiel notwendigen Teile besprechen können.
Generell kann man - zusätzlich zu den globalen oder lokalen
aesthetic mappings in ggplot() oder den geom_()- Funktionen mit den scales- Funktionen auf Positionen und Achsen, Farben und Legende und allgemeine ästhetische Einstellungen zugreifen.Zudem sind mit den themes() Optionen auch weitere
individuelle Anpassungenmöglich.Generelle Struktur: ggplot(data = Daten) %>% ODER Daten %>% ggplot() + Schicht 1 + Schicht 2 + ... weitere Anpassungen + ...
Beispiel:
Wir wollen uns die Häufigkeiten der verkauften Produktkategorien “Single” und “Menü” (sell_category) in einem einfachen Balkendiagramm anschauen. Wir erstellen eine neue Variable prodtyp, damit die Grafik einfacher zu lesen ist.
Nun gehen wir wie folgt vor:
Zuerst erledigen wir Vorarbeiten an den Daten und speichern diese in einem neuen df “data”.
Nun definieren wir ein ggplot Objekt, an das unsere Daten übergeben werden.
Wir nennen es “grafik”. Es ist ein Objekt der Klasseggplot.data <- df_work %>% # Vorarbeiten mutate(prodtyp=recode(sell_category, '0'='single', '2'='menu')) grafik <- data %>% ggplot() # Uebergabe Daten an ggplot() und # speichern als Objekt "grafik" class(grafik) # Objekt grafik hat Klasse "ggplot"## [1] "gg" "ggplot"
Nun definieren wir,
bspw. global, inggplot()mit der Funktionaes()unsereaesthetic mappings, also u.a. unsere abzubildene Variable “prodtyp”.
An dieser Stelle können auch weitere Diagrammoptionen, wie bspw. die Farbfüllung der Balken, ausgewählt werden. Wir wählen dazufill = prodtyp, was automatisch die Erstellung einer Legende und eine Farbfüllung der Balken bewirkt. Zur Erinnerung: Es bleibt Ihnen bzw. Ihrem Vorhaben bei der Diagrammerstellung überlassen, ob Sie die Variablen, Farbfüllung von bspw. Balken usw. inggplot()global (also für alle Schichten) oder in der jeweiligen Schicht - also in dengeom_...() - Funktionenlokaldefinieren.
Als Output erhalten wir nur ein leeres Fenster. Da wir bereits hier eine Variable in den “aes()” definiert haben, erscheinen jedoch schon Achsenbeschriftungen. Eine Abbildung erhalten wir erst, wenn wir noch einen Diagrammtyp (“geom_…()”) hinzufügen.grafik <- data %>% ggplot(aes(x = prodtyp, fill = prodtyp)) #Erweiterung der obigen Syntax um aes() #Wir haben den "prodtyp" als X-Variable eingesetzt #Wir haben eine Legende und Farbfüllung für den #prodtyp eingestellt grafik
Abschliessend fügen wir nun dem Grafikobjekt “Grafik” mit der
geom_...() - Funktioneine Schicht hinzu.
Da es sich um ein Balkendiagramm handelt, wählen wirgeom_bar().grafik + geom_bar() #Hinzufügen der Schicht in Form des Balkendiagramms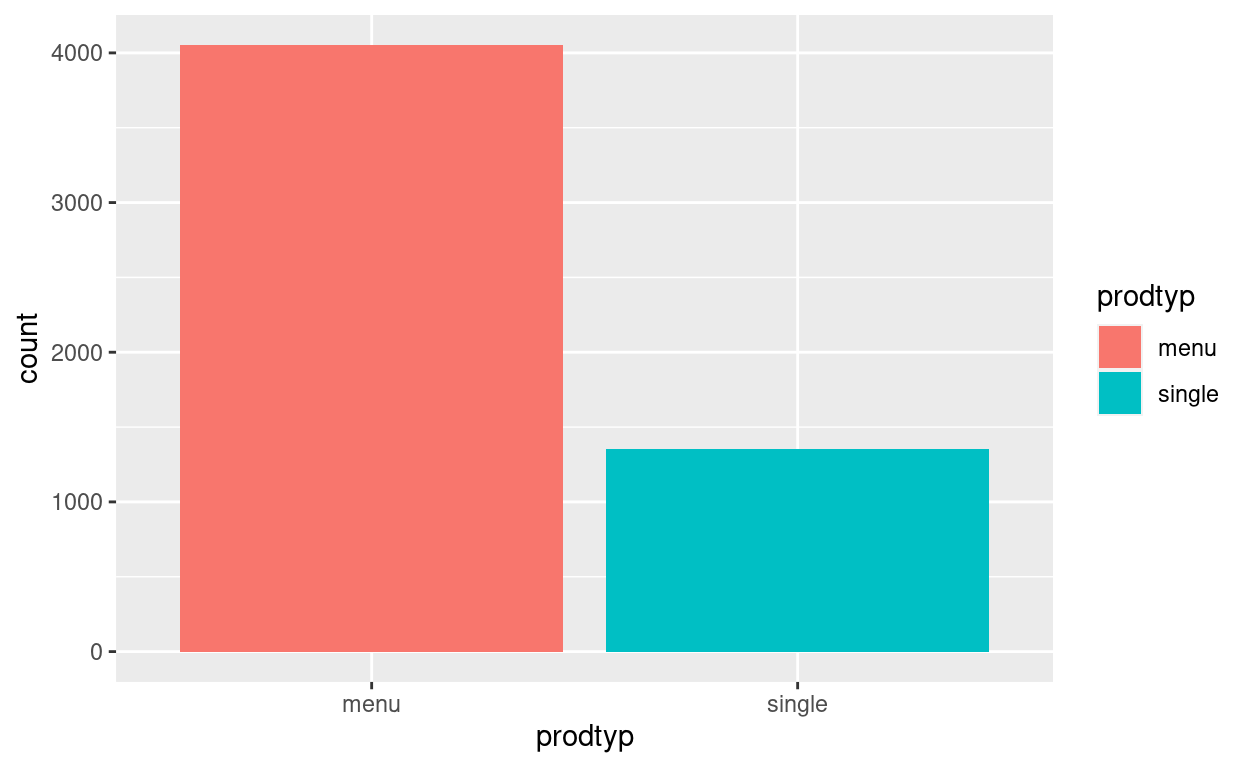
Ausblick:
- Wir behandeln die verschiedenen Diagrammtypen in der Abfolge des dafür notwendigen Skalenniveaus.
- Pro Diagrammtyp sind meist auch Vergleiche nach Gruppen möglich.
- Wir werden ab jetzt die
aes()jeweilslokalerstellen, alsoin der jeweiligen Schicht.
Funktionen zum Erstellen von Grafiken I
Zur Erinnerung: Der Datensatz
df_work enthält nun 16 Spalten und 5404 Zeilen, wobei dieZeile jeweils eine Transaktiondarstellt - also den Verkauf eines bestimmten Produkts (allein oder in Kombination mit anderen Produkten) an einem bestimmten Tag.Pro Tag kann es bis zu 7 verschiedene Transaktionengeben, da die unterschiedlichen Produkte als Einzel- oder, gegebenenfalls, in einem 2er oder 3er Menü verkauft worden sind (siehe “sell_id”).Datenauszug:
1. Balkendiagramme
a) Einfache Balkendiagramme mit der Funktion geom_bar()
- Zur grafischen Veranschaulichung von absoluten und relativen Häufigkeiten (Häufigkeitsverteilung) (un- oder gruppiert) von kategorialen Daten (Nominal, Ordinal) (bspw. Produkttyp (menu vs single == dichotom), Menütyp (burger, burger&coke, burger&lemonade, … == polytom, …) verwenden wir Balkendiagramme (auch Kreisdiagramme sind möglich - welche wir hier nicht behandeln). Wenn die Häufigkeiten der abzubildenden Variable direkt aus den Daten ausgezählt werden können, kann zur Diagrammerstellung bevorzugt die Funktion “geom_bar()” verwendet werden. Stammen die Häufigkeiten der kategorialen Variable aus einer anderen (zweiten) Variable, erstellt man das Diagramm entweder mit der Funktion “geom_bar()” oder der Funktion “geom_col()”. Wir fokussieren der Übersichtlichkeit halber auf “geom_bar()”.
Eine detaillierte Darstellung der Funktionen und Möglichkeiten zur Erstellung von Balkendiagrammen finden Sie hier: https://ggplot2.tidyverse.org/reference/geom_bar.html#aesthetics
Beispiel:
Wir wollen uns die Häufigkeiten (absolut und relativ) der verkauften sell_ids “1070 - 2053” in einem einfachen Balkendiagramm anschauen. Vorab kodieren wir dazu die Variable “sell_id” für die bessere “Lesbarkeit” des Balkendiagramms in “menu” um. Zudem gruppieren wir vorab die Daten nach “menu” und bilden die Variable “quant” - als der absoluten Verkaufsmenge pro Menütyp - und die Variable “proportion” - als relative Häufigkeit der Verkaufsmenge pro Menütyp (in Prozent). Die Werte der X-Achse kommen also aus der kategorialen Variable “menu” und deren Häufigkeiten aus der metrischen Variable “quant”.
Anmerkung: Man kann auch während bzw. innerhalb der Diagrammkonstruktion solche Zusammenfassungen oder Statistiken erzeugen. Dies kann bspw. innerhalb der jeweiligen “geom_…” Funktionen (bspw. für die Erzeugung relativer Häufigkeiten mit “y = ..prop..”) oder mittels einer der “stat_…()”- Funktionen erfolgen. Wir fokussieren in dieser Sitzung auf die “händische” Konstruktion vor der Diagrammerzeugung (die immer verwendet werden kann), da die weiteren Optionen für unsere Daten teilweise ungeeignet sind und es weiterer Formatierungen bedarf.
Wir führen die Vorarbeiten durch und übergeben die Daten an ggplot()
data <- df_work %>% mutate(menu=recode(sell_id, '1070'='burger', '2051'='burger&coke', '2052'='burger&lemonade', '2053'='burger&coke&coffee')) %>% group_by(menu) %>% summarise(quant = sum(quantity)) %>% mutate(proportion = round((quant/sum(quant)),2)*100) %>% ungroup() grafik <- data %>% ggplot()
(1) Aesthetic mappings und Hinzufügen von Schichten:
- Nun definieren wir in geom_bar() mit der Funktion aes() unsere aesthetic mappings, also die Variablen und weitere Bedingungen.
- Mit reorder ordnen wir das “menu” absteigend (Minuszeichen vor “quant”) nach der Variablen “quant” - der absoluten Häufigkeit der Menge des jeweiligen Menütyps.
- Mit fill erreichen wir die farbige Füllung der Balken und die automatische Erstellung einer Legende.
- Abschliessend fügen wir nun dem Grafikobjekt “Grafik” die Schicht hinzu. Würde man die Häufigkeiten nun direkt über die Häufigkeit der zu untersuchenden Variable zählen, dann wäre die Eingabe geom_bar(x = "Variablenname") ausreichend. Da wir in diesem Beispiel aber die Menge bzw. die Anteile der verkauften Menüs pro Menütyp (also die “Höhe” der Balken) nach einer anderen Variable - “quant” oder “proportion” bestimmen, fügen wir der Funktion geom_bar() die Option stat = "identity" hinzu (Standard ist: stat = “count”). Diese ist bei der eingangs erwähnten Funktion “geom_col” standardmässig hinterlegt.
grafik +
geom_bar(aes(x = reorder(menu, -quant),
y = quant, fill = menu),
stat = "identity")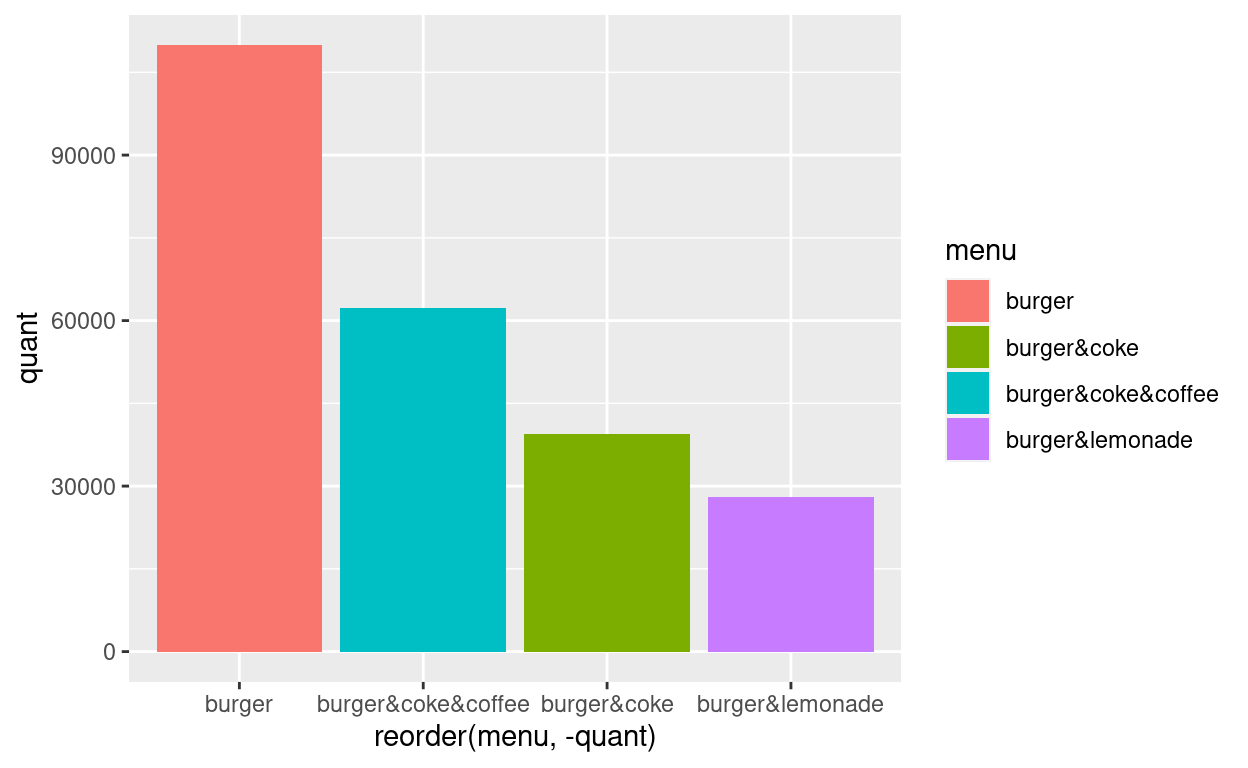
(2) Ändern der Variablen: Wollen wir die relativen Häufigkeiten auf der Y-Achse angezeigt bekommen, ändern wir in diesem Beispiel lokal die Y-Variable und setzen “proportion” ein. Dies muss auch bei “reorder” beachtet werden.
grafik +
geom_bar(aes(x = reorder(menu, -proportion),
y = proportion, fill = menu),
stat = "identity")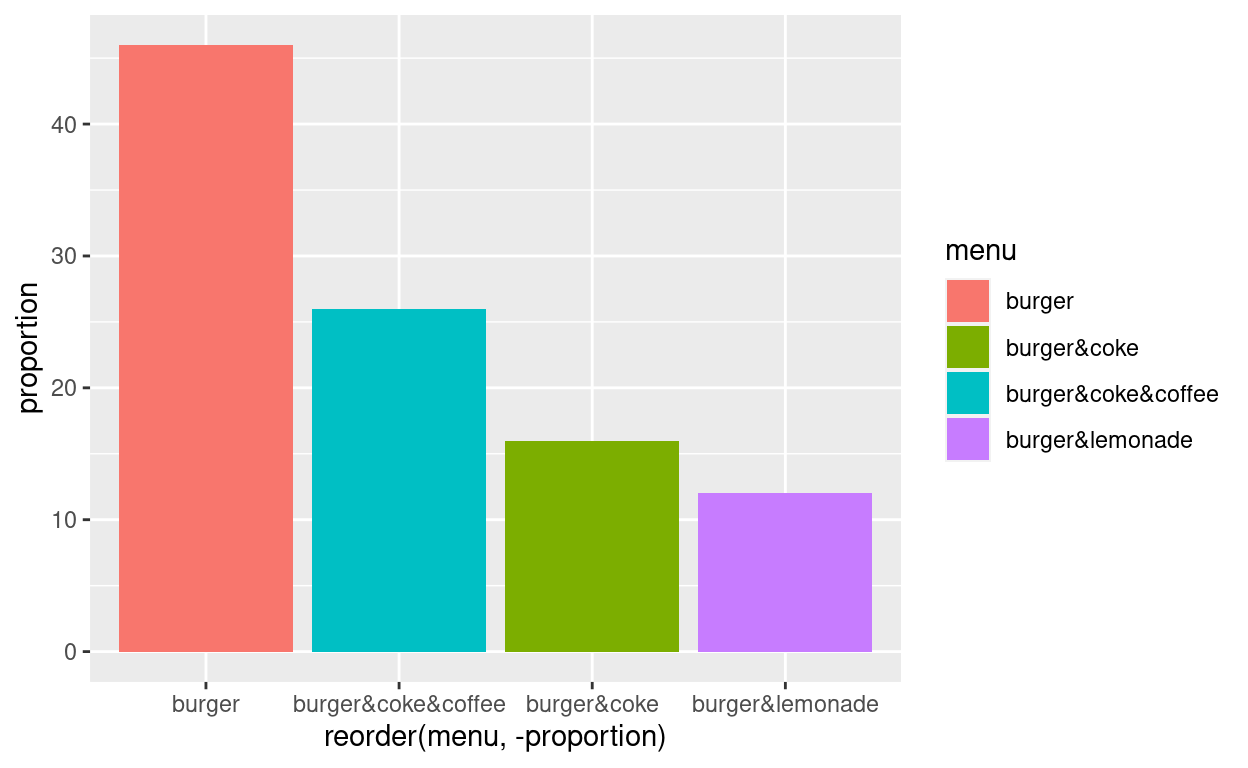
Wie man sieht, gibt es im obigen Diagramm noch weiteren Verbesserungsbedarf. Wir besprechen nun einige Funktionen bzw. Optionen, um Änderungen an den Diagrammteilen vorzunehmen:
(3) Änderung des Layouts mit theme_...():
- Änderung des generellen Layouts zu theme_minimal()
(4) Labels - mit der Funktion labs():
- Hinzufügen einer Überschrift mit labs(title = "TITEL").
- Änderung der Achsenbeschriftungen mit labs(x ="X-Achsen Beschriftung", y = "Y-Achsen Beschriftung")
- Anmerkung: die aufgeführten Beschriftungen wären auch mit der Funktion theme()möglich.
(5) Text im Diagramm - mit der Funktion geom_text():
- Wir zeigen den Anteil pro Menütyp innerhalb des Balkens mit geom_text() direkt an.
- Die label - Option vergibt ein label.
- vjust bestimmt die vertikale Position (hjust die horizontale).
- Color und sizebestimmen die Farbe und Grösse der eingefügten Zahlen.
- Unter colors() können Sie einen Überblick über die Farbnamen gewinnen.
(6) Stil des Diagramms - mit der Funktion theme():
- Mit themegreift man auf den Stil aller nicht Datenelemente eines Diagramms zu. Mehr Informationen gibt es unter: https://ggplot2.tidyverse.org/reference/theme.html
- Unter anderem können Stiländerungen der Achsenbezeichnungen und Abschnitte mit der Funktion theme() mit theme(axis.title.y = element_text(angle = 0, vjust = 0.5), axis.text.x = element_blank(), axis.ticks.x = element_blank()) vorgenommen werden.
- Mit element_text greift man auf die Skalenbeschriftungen zu, mit bspw. element_line auf die Linienmarkierungen usw. .
- Mit angle ändern wir den Winkel der Anzeige der Achsenlabel. Mit element_blank() unterdrücken wir die Anzeige ausgewählter Elemente.
(7) Bearbeitung der Legende oder der numerischen Skalenbezeichnungen - mit scale_ - Funktionen:
- Die numerischen Bezeichnungen der Achsen - die Achsenskalen - sowie die Legende können mit scale-Funktionen geändert werden.
- Wir erinnern uns: Wir haben “fill = menu” gesetzt. Wir ändern hier nur die Reihenfolge in der Legende. Diese kommt aus der Option fill und beinhaltet ein diskretes Merkmal, das “Menü”. Deshalb nutzen wir scale_fill_discrete(name = "menu type", breaks=c("burger","burger&coke&coffee","burger&coke","burger&lemonade")).
Unsere Befehle sind im folgenden Fenster in der Syntax dokumentiert:
grafik +
geom_bar(aes(x = reorder(menu, -proportion), #sortiere menu absteigend nach proportion
y = proportion, #Wert Y-Achse
fill = menu), #Balkenfüllung anhand "menu"
stat = "identity") + #Höhe Balken bestimmt durch "proportion"
theme_minimal() + #Layout
labs(title = "proportion of quantity sold per menu type", #Titel Diagramm
x = "menu type", #Titel X-Achse
y = "proportion") + #Titel Y-Achse
geom_text(aes(x = reorder(menu, -proportion), #notwendige Angabe x
y = proportion, #notwendige Angabe Y
label = proportion), #Zahlen in Balken kommen aus "proportion"
vjust=1.6, #vertikale Verschiebung der Zahlen
color="white", #Farbe der Zahlen
size=3.5) + #Groesse der Zahlen
theme(axis.title.y = element_text(angle = 0, #Winkel des Y-Achsen Titels
vjust = 0.5), #Vertikale Justierung des Y-Achsen Titels
axis.text.x = element_blank(), #Text x-Achse = leer - kein Text
axis.ticks.x = element_blank()) + #Markierung x-Achse = leer - keine Markierung
scale_fill_discrete(name = "menu type", #Titel Legende
breaks = c("burger", #Kateg. d. Legende nach Diagrammreihenfolge
"burger&coke&coffee",
"burger&coke",
"burger&lemonade"))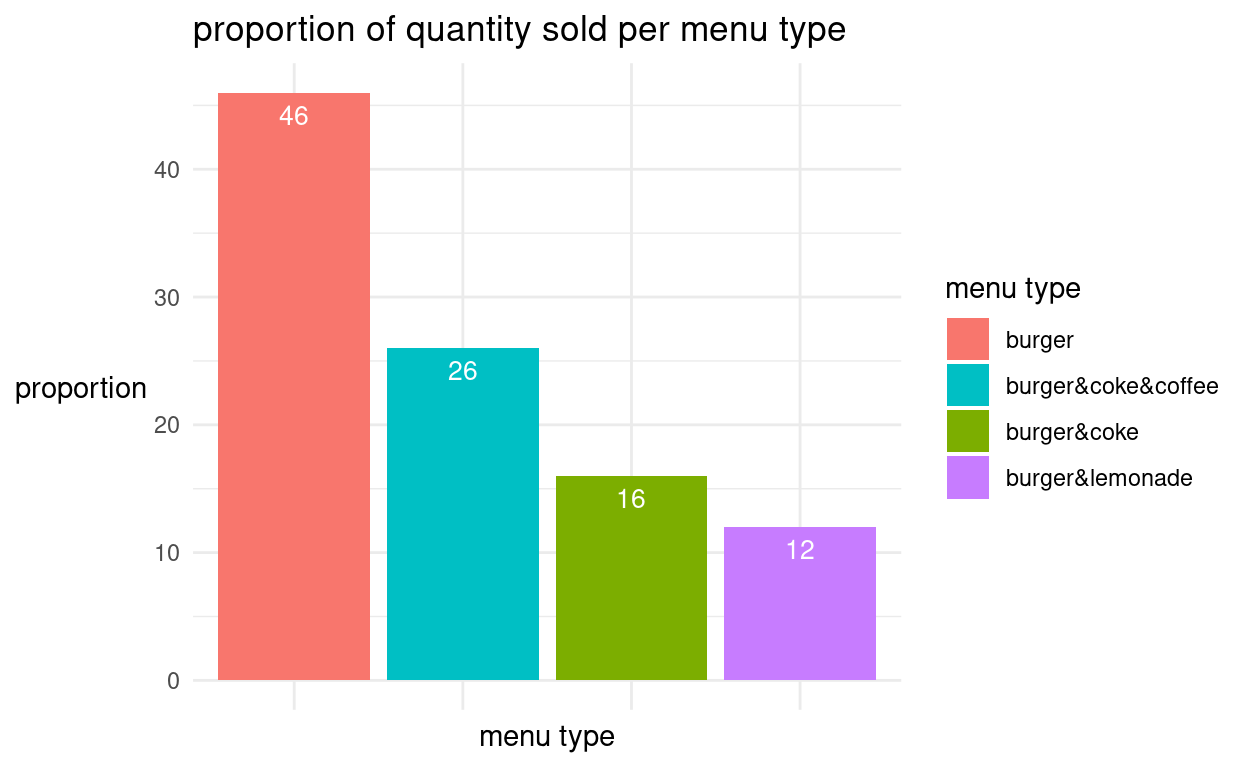
(8) Vertauschen der Achsen - mit der Funktion coord_flip():
- Wir können die Diagrammachsen auch vertauschen, sodass die Balken horizontal erscheinen. Dies geht mit der Funktion coord_flip(), wie man in der 2. Syntaxzeile sieht.
- Damit es übersichtlich bleibt, schalten wir in der Funktion geom_bar() mit show.legend = FALSE die Legende aus und verringern die Balkenbreite mit width = 0.7 etwas.
- Zudem verschieben wir die Zahlen in den Balken mit hjust etwas horizontal.
grafik +
coord_flip() + #Tauschen der Achsen
geom_bar(aes(x = reorder(menu, -proportion), #sortiere menu absteigend nach proportion
y = proportion, #Wert Y-Achse
fill = menu), #Balkenfüllung anhand "menu"
stat = "identity", #Höhe Balken bestimmt durch "proportion"
width = 0.7, #Balkenbreite verringern
show.legend = FALSE) + #Legende ausschalten
theme_minimal() + #Layout
labs(title = "proportion of quantity sold per menu type", #Titel Diagramm
x = "menu type", #Titel X-Achse
y = "proportion") + #Titel Y-Achse
geom_text(aes(x = reorder(menu, -proportion), #notwendige Angabe x
y = proportion, #notwendige Angabe Y
label = proportion), #Zahlen in Balken kommen aus "proportion"
vjust=0.5, #vertikale Verschiebung der Zahlen
hjust=1.5, #horizontale Verschiebung der Zahlen
color="white", #Farbe der Zahlen
size=3.5) + #Groesse der Zahlen
theme(axis.title.y = element_text(angle = 0, #Winkel des Y-Achsen Titels
vjust = 0.5), #Vertikale Justierung des Y-Achsen Titels
axis.text.x = element_blank(), #Text x-Achse = leer - kein Text
axis.ticks.x = element_blank()) + #Markierung x-Achse = leer - keine Markierung
scale_fill_discrete(name = "menu type", #Titel Legende
breaks = c("burger", #Kateg. d. Legende nach Diagrammreihenfolge
"burger&coke&coffee",
"burger&coke",
"burger&lemonade"))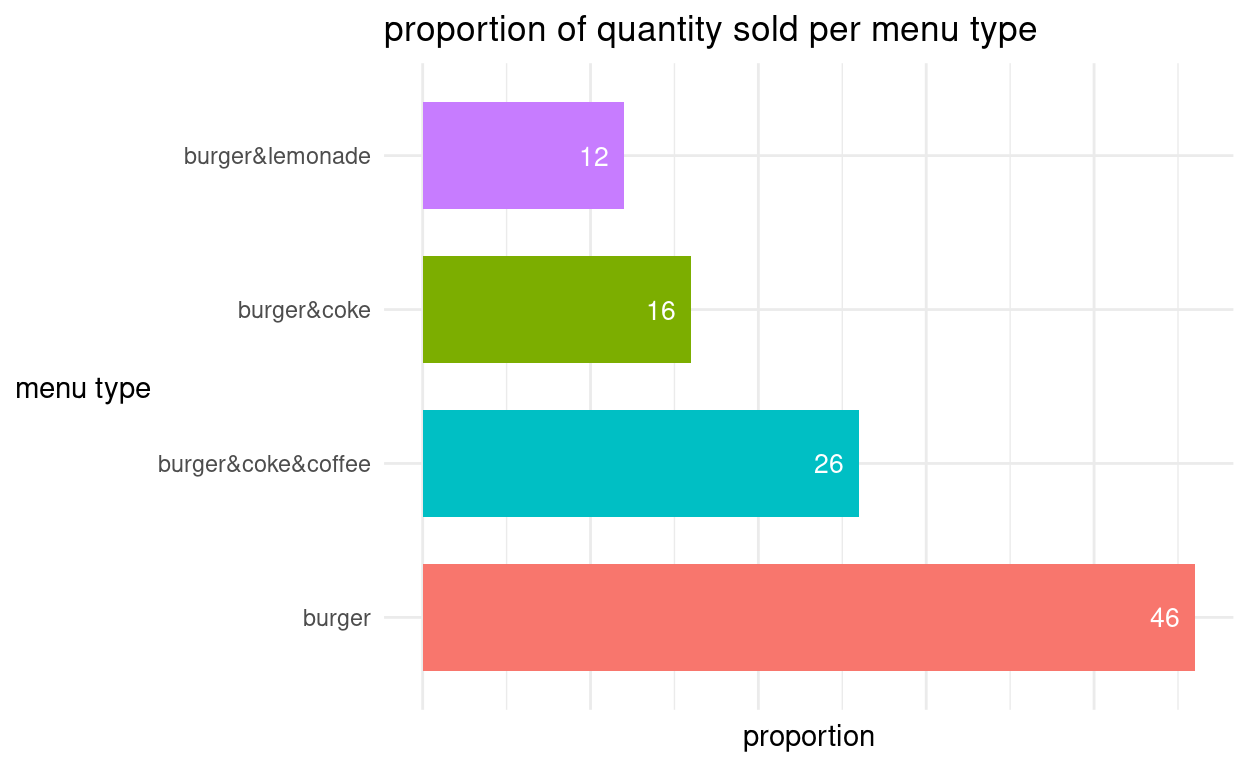
b) Gruppierte Balkendiagramme mit der Funktion geom_bar()
Neben solchen univariaten Darstellungen sind mit Balkendiagrammen auch bivariate Darstellungen möglich. Dazu gruppiert man die interessierende Variable nach einem weiteren Merkmal.
Beispiel:
Wir erweitern unser Beispiel und untersuchen grafisch, ob sich die Verkaufsmengen der Menütypen zwischen Aussen- oder Innenverkäufen unterscheiden.
Wir gruppieren diesmal nicht nur nach dem Menütyp sondern auch nach dem Ort (location), an dem verkauft wurde.
data <- df_work %>%
mutate(menu=recode(sell_id,
'1070'='burger',
'2051'='burger&coke',
'2052'='burger&lemonade',
'2053'='burger&coke&coffee'),
location=recode(is_outdoor, '
0'='indoor',
'1'='outdoor')) %>%
group_by(menu, location) %>%
summarise(quant = sum(quantity)) %>%
group_by(location) %>%
mutate(proportion_c = round((quant/sum(quant)),2)*100,
quant_c = sum(quant),
proportion_c = replace(proportion_c,
proportion_c == 12, 11)) %>%
ungroup %>%
mutate(proportion = round((quant/sum(quant)),2)*100)
grafik <- data %>% ggplot()
Wir ändern nun in den “aesthetics” -
aes()bei geom_bar() noch die Option “fill= location” und fügen “group= menu” hinzu.Standardmässig bekommen wir ein stacked barchart, ein gestapeltes Balkendiagramm, bei folgender Syntax angezeigt:
grafik + geom_bar()Wir müssen, wie auch schon im letzten Abschnitt in
geom_bar()die Optionstat = identityhinzufügen, da die Balkenhöhe nicht durch das Auszählen der Variable “menu” selbst, sondern durch die danach geordnete Variable “quant” bestimmt wird. Wie zu erwarten, sind die Verkaufsmengen aller Menütypen bei der Kategorie Outdoor bei allen Produkten um ein Vielfaches höher als bei Indoor.grafik + geom_bar(aes(x = reorder(menu, -quant), y = quant, fill = location, group = menu), stat = "identity")
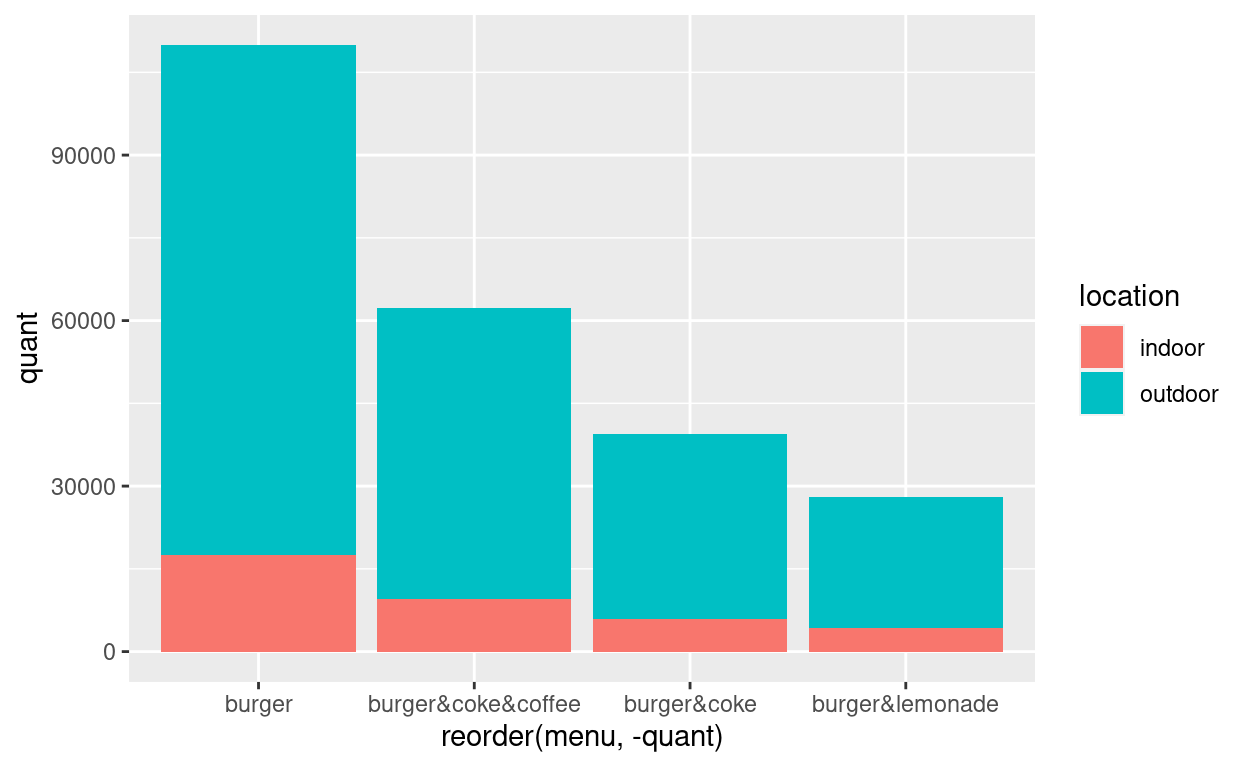
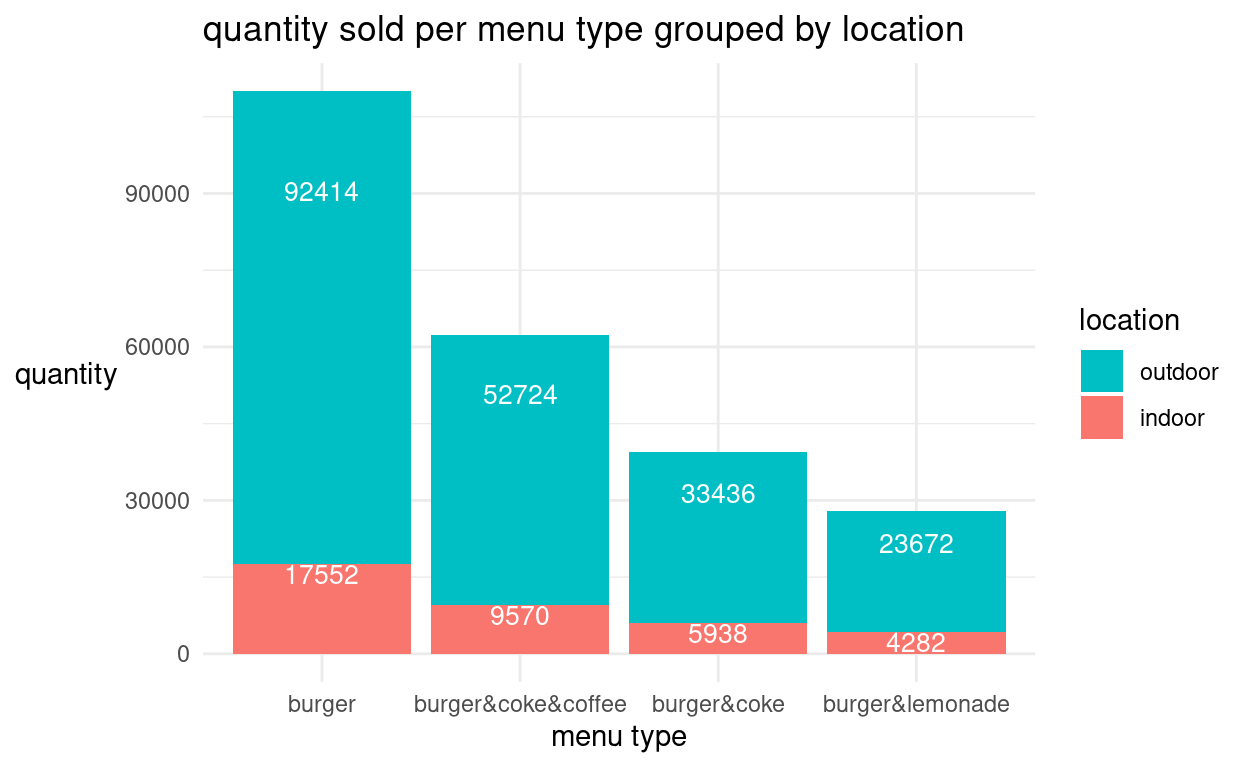
Wir bearbeiten das Diagramm wieder mit einigen Befehlszeilen nach, die wir auch für die einfachen Balkendiagramme zur Justierung genutzt haben. Der Vorteil ist also, dass wir die bereits gebildeten Schichten bzw. Optionen auch zu einem gestapelten Balkendiagramm hinzufügen können. Wir zentrieren lediglich die Position der Zahlen in den Balken mit “vjust=1” und ändern die Reihenfolge in der Legende in der letzten Befehlszeile.
grafik + geom_bar(aes(x = menu, y = quant, fill = location, group = menu), stat = "identity") + theme_minimal() + labs(title = "quantity sold per menu type grouped by location", x = "menu type", y = "quantity") + geom_text(aes(x = menu, y = quant, label = quant), vjust = 1, color = "white", size = 3.5) + theme(axis.title.y = element_text(angle = 0, vjust = 0.5)) + scale_fill_discrete(name = "location", breaks=c("outdoor","indoor"))
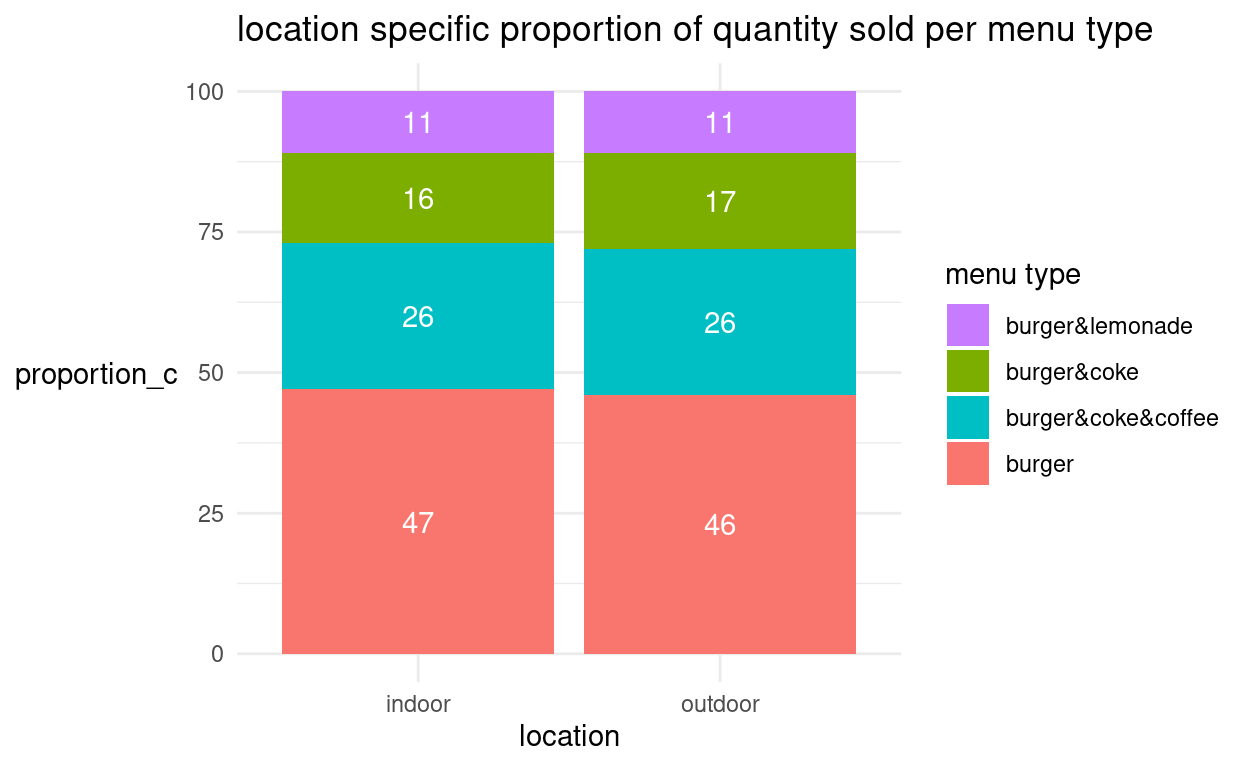
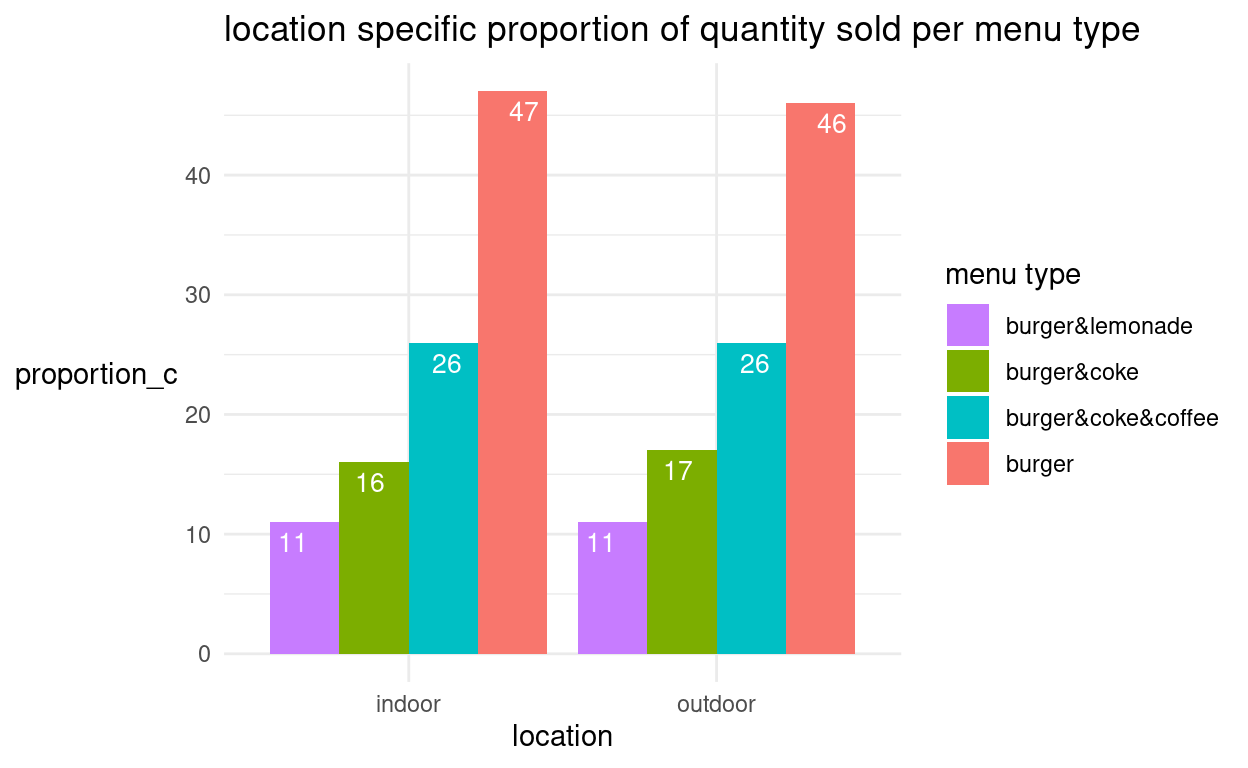
Wir können in geom_bar(aes()) bspw. auch die Menge (quant) auf der Y-Achse durch die oben gebildete Variable Spaltenprozente (proportion_c) ersetzen. Die damit abgebildeten “bedingten relativen Häufigkeiten” beziehen sich auf die Variable “location”, die wir auf die X-Achse setzen.
Die Füllfarbe der Balken (fill) wird durch das Menu bestimmt. Um der Grösse nach zu ordnen, setzen wir als
groupdie Spaltenprozente ein.Bei *
geom_text()müssen wir enstprechend “x”, “y”, “label” und die “group” ändern undposition = position_stack(vjust = .5)hinzufügen, damit die Zahlen übereinander in die richtigen Balken abgetragen werden.Abschliessend ändern wir manuell die Reihenfolge in der Legende.
Wie sich zeigt, scheint der Anteil Menüs unabhängig von der location zu sein.
grafik + geom_bar(aes(x = location, y = proportion_c, fill = menu, #Füllung durch Menu group = proportion_c), #Sortieren nach Anteilen stat = "identity") + theme_minimal() + labs(title = "location specific proportion of quantity sold per menu type", x = "location", y = "proportion_c") + geom_text(aes(x = location, y = proportion_c, label = proportion_c, #Label in Balken aus proportion_c group = proportion_c), #Gruppe = proportion_c color = "white", position = position_stack(vjust = .5)) + #Zahlen in Balken übereinander in korrekter Reihenfolge theme(axis.title.y = element_text(angle = 0, vjust = 0.5)) + scale_fill_discrete(name = "menu type", breaks = c("burger&lemonade", "burger&coke", "burger&coke&coffee", "burger"))
Abschliessend wollen wir die Balken nebeneinander - also
dodge- anordnen. Wir erweitern geom_bar() dazu noch um den Befehlgeom_bar(position = "dodge")und ingeom_text(position = position_dodge(width = 1)).grafik + geom_bar(aes(x = location, y = proportion_c, fill = menu, group = proportion_c), stat = "identity", position = "dodge") + #Balken nebeneinander anordnen theme_minimal() + labs(title = "location specific proportion of quantity sold per menu type", x = "location", y = "proportion_c") + geom_text(aes(x = location, y = proportion_c, label = proportion_c, group = proportion_c), position = position_dodge(width = 1), color = "white", size = 3.5, vjust = 1.5) + theme(axis.title.y = element_text(angle = 0, vjust = 0.5)) + scale_fill_discrete(name = "menu type", breaks = c("burger&lemonade", "burger&coke", "burger&coke&coffee", "burger"))
Übung I
Laden Sie nun das aktuelle R-Skript zur weiteren lokalen Bearbeitung der folgenden Übungsaufgaben herunter und speichern Sie es lokal in Ihrem Projektordner.
Lösen Sie die folgenden Übungsaufgaben und vervollständigen Sie das Skript Schrittweise nach jeder Übungsaufgabe.
Bei einigen der direkten Multiple Choice Aufgaben ist es sicher hilfreich, wenn Sie die Syntax zur Lösungsfindung jeweils lokal bei sich in R ausprobieren.
Am Ende der Übung werden die Dozierenden mit Ihnen die Lösungen besprechen.
1
2
Erstellen Sie mit dem pipe-Operator ein Grafikobjekt “work”, dass den Data Frame “df_work” verwendet. Lassen Sie sich die Klasse des Objekts anzeigen und beantworten Sie danach die Quizfrage.
work <- df_work %>% ggplot()
class(work)
Sie arbeiten in den folgenden Aufgaben nun mit dem nach Datum aggregierten Datensatz “ag”. Er beinhaltet diesselben Variablen wie der df_work - Data Frame, allerdings jeden Tag nur einmal. Alle Werte pro Tag sind Durchschnittswerte.
ag <- df_work %>%
mutate(date = as.Date(calendar_date)) %>%
select(date, is_schoolbreak, is_weekend,
average_temperature, is_outdoor, quantity) %>%
aggregate(. ~ date, ., FUN=mean, na.rm=TRUE) %>%
mutate(is_schoolbreak=as.factor(is_schoolbreak),
is_weekend=as.factor(is_weekend),
temp = (average_temperature-32)*5/9,
is_outdoor=as.factor(is_outdoor))Nutzen Sie für Ihre Lösungen der folgenden Aufgaben bitte die lokalen aes() in der jeweiligen geom_...() Funktion, wie bswp.:
ag %>%
ggplot() +
geom_...(aes(x = , y = ), fill = )3
Erstellen Sie mit der Variable “is_schoolbreak” ein einfaches Balkendiagramm.ag %>% ggplot() +
geom_bar(aes(x = is_schoolbreak))
4
Fügen Sie dem Diagramm den Titel “schoolbreak” hinzu und zentrieren Sie den Titel auf den Wert “0.5”. Verringern Sie nun die Balkenbreite in der Funktion geom_bar() auf 0.6.ag %>% ggplot() +
geom_bar(aes(x = is_schoolbreak), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5))
5
Entfernen Sie das Label der X-Achse. Beschränken Sie die Werte auf dem X-Achsen Abschnitt auf 2 Werte. An der Stelle “0” soll der Name “school”,an der Stelle “1” der Name “no_school” erscheinen. Verwenden Sie die Funktionscale_x_discrete(limits = , labels =).
ag %>% ggplot() +
geom_bar(aes(x = is_schoolbreak), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school"))
6
Fügen Sie nun mit “geom_text” Text in das Diagramm. In beiden Balken soll jeweils am oberen Rand die Anzahl - also der Wert von “count” - stehen. Der Wert wird in diesem Fall - ohne Zuweisung der Häufigkeiten durch eine andere Variable - in der Variable..count.. automatisch von R hinterlegt. Vervollständigen Sie dazu die unten stehende Syntax, indem Sie in “geom_text(aes(x = …., label = …)),” für xund für label die entsprechenden Werte einsetzen. Beantworten Sie danach die Quizfrage.
ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x= , label = ),
stat = "count",
vjust = 1.5,
colour = "white")ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count..),
stat = "count",
vjust = 1.5,
colour = "white")7
8
Gruppieren Sie nun das Balkendiagramm nach der Variable “is_weekend”. Nutzen Sie die aes() Parameter “fill()” und “group()”.ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count..),
stat = "count",
vjust = 1.5,
colour = "white")ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak, fill = is_weekend, group = is_weekend), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count..),
stat = "count",
vjust = 1.5,
colour = "white")
9
Die Zahlen der Häufigkeiten im gruppierten Diagramm werden noch nicht für alle Balkenteile angezeigt. Fügen Sie in in den “aes()” von “geom_text()” die Gruppierungsvariable hinzu und beantworten Sie danach die Quizfrage.ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak, fill = is_weekend, group = is_weekend), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count..),
stat = "count",
vjust = 1.5,
colour = "white")ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak, fill = is_weekend, group = is_weekend), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count.., group = is_weekend),
stat = "count",
vjust = 1.5,
colour = "white")
10
Setzen Sie die Balken nebeneinander. Sie sollten dazu in “geom_text()” die Position in etwa mit “width = 0.6” festlegen, damit die Zahlen in den Balken leserlich erscheinen.ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak, fill = is_weekend, group = is_weekend), width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count.., group = is_weekend),
stat = "count",
vjust = 1.5,
colour = "white")ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak, fill = is_weekend, group = is_weekend), position = "dodge", width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count.., group = is_weekend),
stat = "count",
position = position_dodge(width = 0.6),
color = "white",
hjust = 0.8,
vjust = 1.2)
11
Drehen Sie das Diagramm nun mit der Funktion “coord_flip()” und justieren Sie die Zahlen in den Balken horizontal auf 1. Unterdücken Sie mitname = ""den Namen der Legende. Ändern Sie zudem die Anordnung der Legende gemäss der Balkenanordung mit der Option “breaks = c()” und ändern Sie die Bezeichnungen “0” und “1” zu “no_weekend” und “weekend” mit scale_fill_discrete().
ag %>% ggplot() +
geom_bar(aes(x=is_schoolbreak, fill = is_weekend, group = is_weekend), position = "dodge", width=0.6) +
labs(title = "schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count.., group = is_weekend),
stat = "count",
position = position_dodge(width = 0.6),
color = "white",
hjust = 0.8,
vjust = 1.2)ag %>% ggplot() +
coord_flip() +
geom_bar(aes(x=is_schoolbreak, fill = is_weekend, group = is_weekend), position = "dodge", width=0.6) +
labs(title = "schoolbreak grouped by week section") +
theme(plot.title = element_text(hjust = 0.5),
axis.title.x = element_blank()) +
scale_x_discrete(limits=c("0","1"), labels=c("school","no_school")) +
geom_text(aes(x=is_schoolbreak, label = ..count.., group = is_weekend),
stat = "count",
position = position_dodge(width = 0.6),
color = "white",
hjust = 1) +
scale_fill_discrete(name = "", breaks = c("1","0"), labels=c("weekend", "no_weekend"))
Laden Sie nun das aktualisierte R-Skript herunter und speichern Sie es lokal in Ihrem Projektordner.
Funktionen zum Erstellen von Grafiken II
2. Histogramme
a) Einfache Histogramme mit der Funktion geom_histogram()
- Zur grafischen Veranschaulichung der Verteilung von kontinuierlichen bzw. metrischen - in Klassen zusammengefassten - Variablen (un- oder gruppiert) (bspw. Preis, Alter, Einkommen) verwenden wir Histogramme (auch Häufigkeitspolygone sind möglich, welche wir hier nicht behandeln).
Eine detaillierte Darstellung aller Funktionen und Möglichkeiten zur Erstellung von Histogrammen finden Sie hier: https://ggplot2.tidyverse.org/reference/geom_histogram.html
Beispiel:
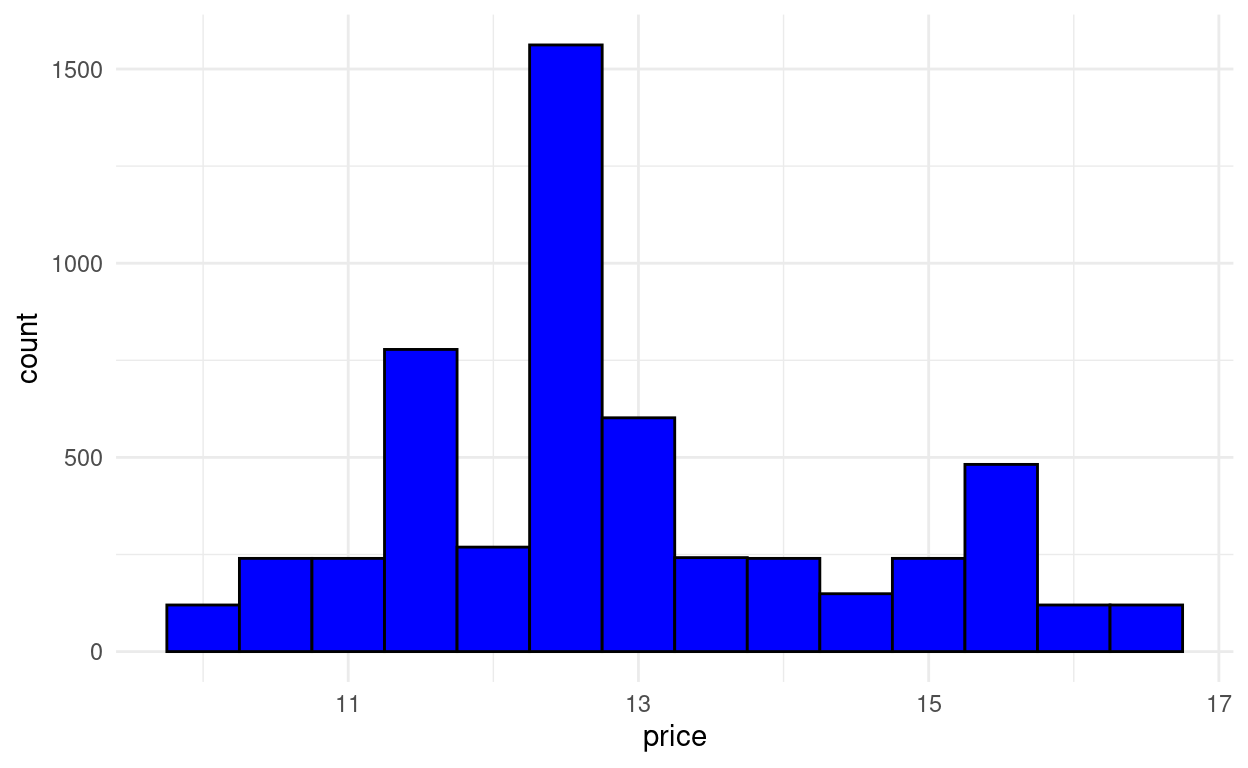
Wir wollen uns die absolute und die relative Häufigkeit der (klassierten) Transaktionspreise in einem Histogramm anschauen. Wir erstellen dazu ein Grafikobjekt. Zudem lassen wir uns die summary() Statistik ausgeben, um einen groben Überblick über die Verteilung zu erhalten. Sie scheint annähernd symmetrisch. Wir übergeben die Variablen und Formatierungen lokal an die “geom_…() - Funktion”, die den Diagrammtyp definiert.
grafik <- df_work %>% mutate(we=recode(is_weekend,
'0'='no weekend',
'1'='weekend')) %>%
ggplot()
summary(df_work$price)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 10.12 11.53 12.64 12.87 13.56 16.50Nun erstellen wir mit der Funktion
geom_histogram(price, bin = 0.5, fill = "blue")das Histogramm.
Geben wir bei
binkeine Klassenbreite an, bestimmt R diese selbst. Wir haben die Klassenbreite so gewählt, dass keine Klasse unbesetzt ist.
Als Balkenfüllung wählen wir eine Farbe direkt aus - “blue”.
Damit alle Balken voneinander unterschieden werden können, wählen wir als Umrandungsfarbe “black”.
Zudem ändern wir erneut das Layout auf
theme_minimal().grafik + geom_histogram(aes(x = price), fill = "blue", binwidth = 0.5, color = "black") + theme_minimal()
b) Gruppierte Histogramme mit der Funktion geom_histogram()
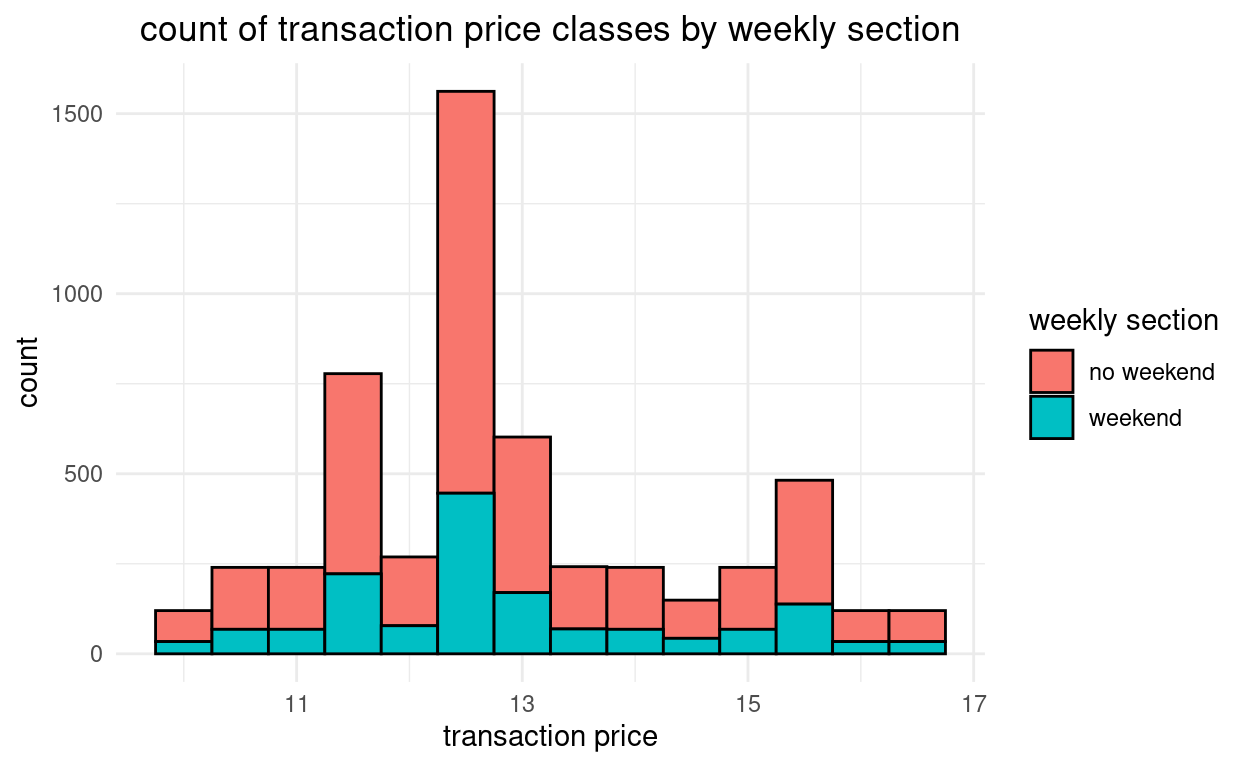
Um die Balken übereinander zu setzen - also
stacked, fügen wir ingeom_histogram(aes())die Option “fill= is_weekend” hinzu. Wir gruppieren also danach, ob Wochenende ist oder nicht.grafik + geom_histogram(aes(x = price, group = we, # Gruppierung fill = we), # Balkenfüllfarbe nach Gruppe binwidth = 0.5, color = "black") + theme_minimal() + labs(title = "count of transaction price classes by weekly section", y = "count", x = "transaction price") + theme(plot.title = element_text(hjust = 0.5)) + scale_fill_discrete(name = "weekly section")
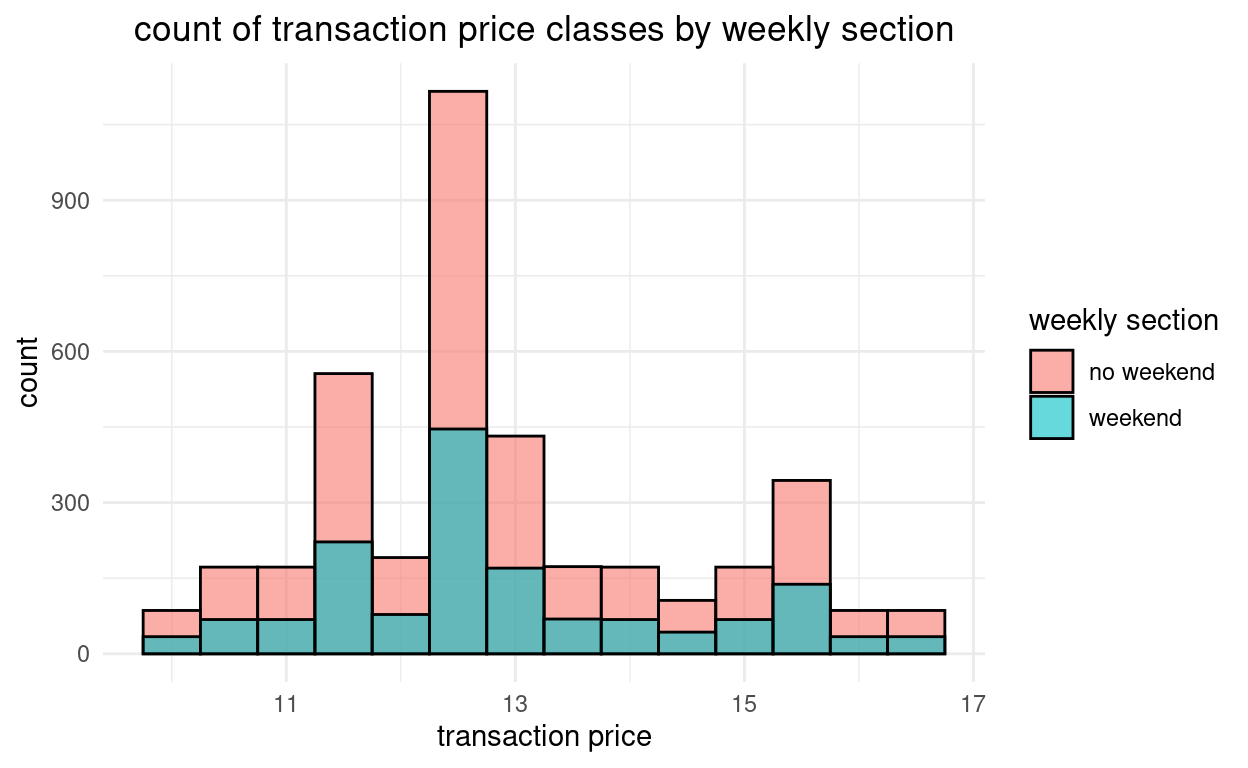
Wollen wir die Diagramme pro Gruppe hintereinander setzen, fügen wir in
geom_histogram(aes())noch die Optionposition = "identity"hinzu.
Die Verwendung der Option
alpha = 0.6erhöht die Transparenz.Da nun beide Diagramme hintereinander abgebildet werden, verkleinert sich die Skala auf der Y-Achse etwas.
grafik + geom_histogram(aes(x = price, group = we, fill = we), binwidth = 0.5, color = "black", position = "identity", # Positionierung hintereinander alpha = 0.6) + theme_minimal() + labs(title = "count of transaction price classes by weekly section", y = "count"x, x = "transaction price") + theme(plot.title = element_text(hjust = 0.5)) + scale_fill_discrete(name = "weekly section")
Für die Anzeige relativer Häufigkeiten der Preisklassen gibt es mind. 2 Möglichkeiten:
- Wir könnten in geom_histogram(aes()) entweder mit y = ..density.. die Dichtefunktion ausgeben, da deren Fläche in der Summe 1 ist.
- Oder (siehe folgende Abbildung) wir können mit y=..count../sum(..count..)*100 die relativen Häufigkeiten in Prozent direkt berechnen. Wir fügen noch eine neue Achsenbeschriftung hinzu und laden das Diagramm erneut.
grafik +
geom_histogram(aes(x = price,
y = ..count../sum(..count..)*100), # relative Häufigkeiten
binwidth = 0.5,
fill="blue",
color = "black") +
theme_minimal() +
labs(title = "histogram showing proportions of transaction price classes",
y = "proportion",
x = "transaction price")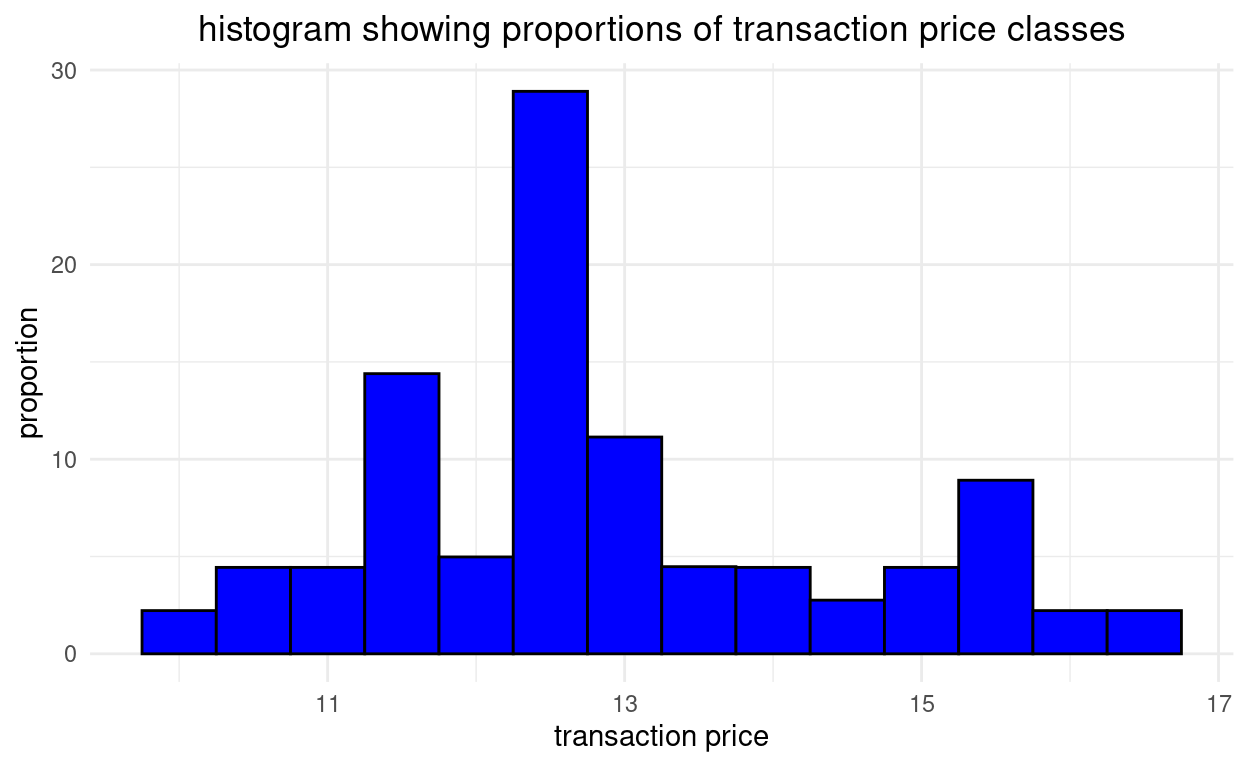
Kombination 2er Schichten in einem Diagramm
Wir können abschliessend auch zwei Optionen in einem Diagramm kombinieren. Diesmal geben wir bei
geom_histogram(aes())mity = ..density..die relativen Häufigkeiten durch die Dichtefunktion aus. Damit ändert sich die Skala der Y-Achse auf die der Dichtefunktion.
Zudem fügen wir die Dichtefunktion als weitere Schicht mit
geom_density()hinzu, wobei dort noch “x=price” bei den “aesthetics” eingestellt werden muss.
Anmerkung: Wir könnten auch die Befehlssyntax bei geom_histogram() so belassen wie im vorigen Beispiel und einfach direkt die Schicht geom_density(aes(x=price, y = (..density..))) hinzufügen. Da die Skala der Dichtefunktion auf der Y-Achse jedoch etwa bei maximal 0.4 endet, wäre die hinzugefügte Dichtfunktion im Diagramm bei einer Y-Skala zwischen 0 und 30 (der Skala, die die Anteilswerte anzeigt) ohne Nachjustierung aber kaum zu erkennen.
Wir laden das Diagramm erneut.
grafik + geom_histogram(aes(x=price, y=..density..), #rel.Häufigkeiten über Dichtefunktion binwidth = 0.5, colour="black", fill="blue", alpha = 0.5)+ geom_density(aes(x=price), #Einblenden der Dichtefunktion alpha=.2, fill="red")
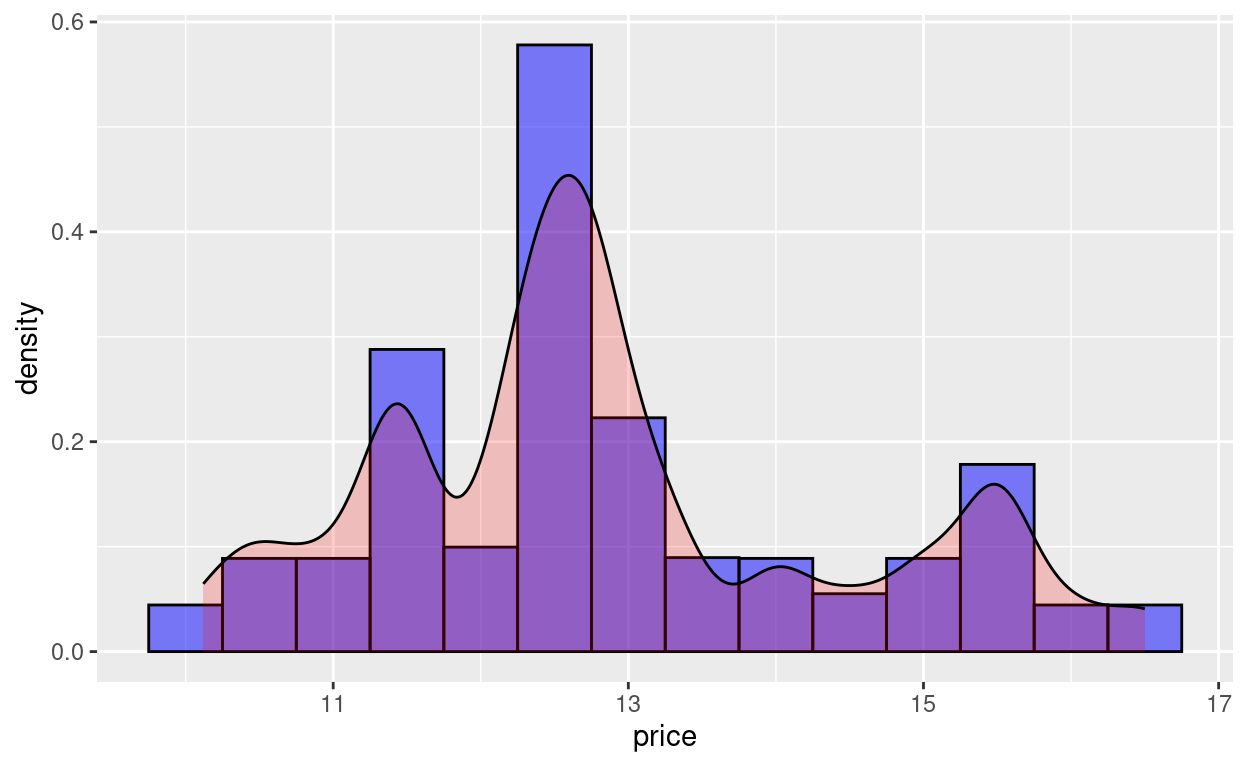
3. Boxplots
a) Einfache Boxplots mit der Funktion geom_boxplot()
- Zur grafischen Veranschaulichung der Verteilung von kontinuierlichen bzw. metrischen Variablen (un- oder gruppiert) (bspw. Preis, Alter, Einkommen) verwenden wir den Boxplot. Gegenüber dem Histogramm hat er den Vorteil, dass er die Verteilung einer kontinuierlichen Variable anhand von Lage- und Streuungsmassen (Median, Interquartilsabstand) sowie alle “abweichenden” Punkte einzeln zusammengefasst abbildet.
Zur Erinnerung:
Die
Boxwird durchQ1 (erstes Quartil) und Q3 (drittes Quartil) begrenztundenthält den Median (Q2) und die mittleren 50% aller Werte. DieLänge der Boxentspricht dem sogenanntenInterquartilsabstand (Q3 - Q1).Die
Länge der Whisker(Antennen) entsprichtmaximal dem 1,5-fachen Interquartilsabstand (IQR)von Q1 nach unten und Q3 nach oben. Der Whisker endet aber in Grafiken bei dem Wert aus den Daten, der noch innerhalb dieser Grenze liegt (es wird also nicht zwingend der errechnete Wert für Q1 oder Q3 abgebildet). Deshalb sind die Whiskers nur selten gleich lang. Wennkeine Datenpunkte außerhalb der Grenze des 1,5 fachen IQRliegen, wird dieLänge der Whiskers durch das Maximum und Minimumbestimmt.Werte die
mehr als 1.5 und weniger als 3 x IQR von Q1 nach unten oder Q3 nach obenentfernt liegen nennt manAusreisser,Wert > 3 x IQR sind Extremwerte. Meist gibt es zumindest Ausreisserwerte, deren kleinster und grösster Wert dann Minimum und Maximum der Verteilung darstellen.
Eine detaillierte Darstellung aller Funktionen und Möglichkeiten zur Erstellung von Boxplots finden Sie hier: https://ggplot2.tidyverse.org/reference/geom_boxplot.html
Beispiel:
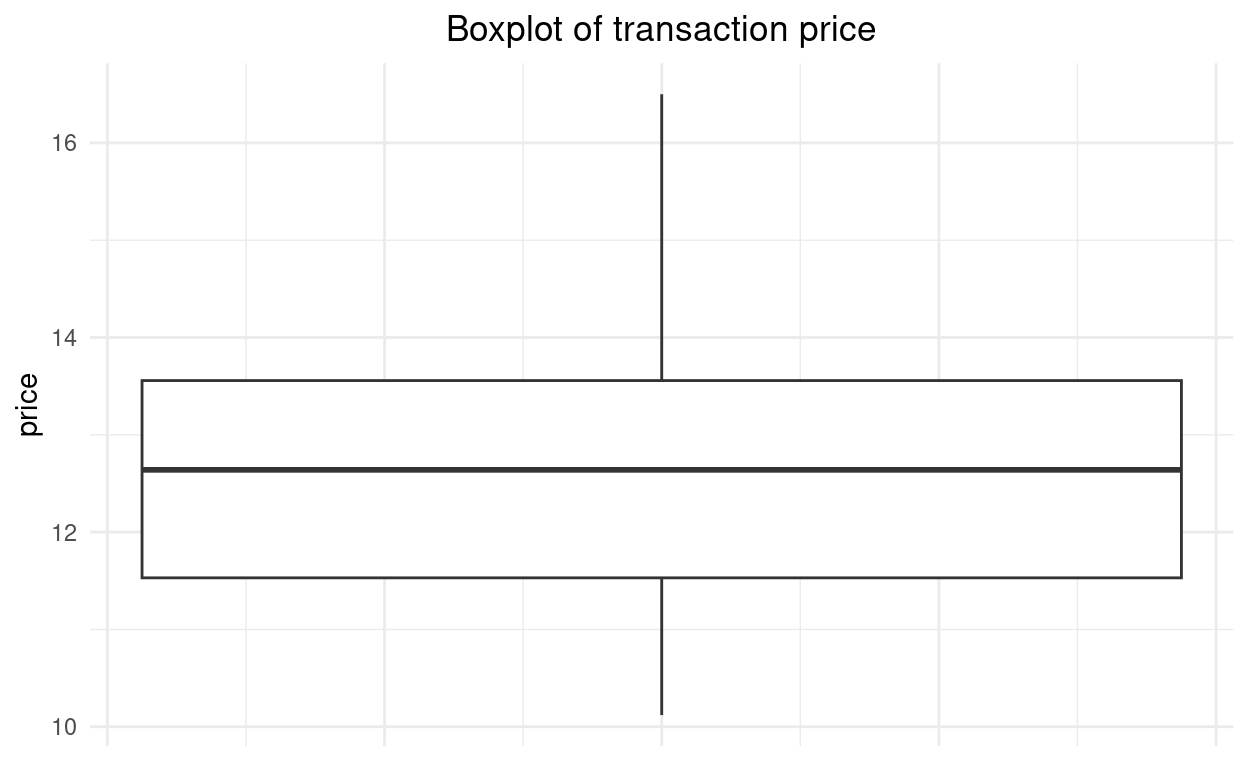
Wir wollen uns die Verteilung der Variable “Transaktionspreis” in einem Boxplot anschauen. Zuerst lassen wir uns die summary() Statistik ausgeben, um einen groben Überblick über die Verteilung zu erhalten. Sie scheint annähernd symmetrisch. Wir übergeben im Anschluss die Variable und Formatierungen lokal an die “geom_boxplot() - Funktion”, die den Diagrammtyp usw. definiert.
summary(df_work$price)## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 10.12 11.53 12.64 12.87 13.56 16.50Nun erstellen wir mit der Funktion
geom_boxplot(aes(y=price))den Boxplot.Die Länge der Whisker entspricht dem Maximum und Minimum, da keine Datenpunkte ausserhalb der Grenze des 1.5 fachen IQR liegen.
Der untere Rand der Box entspricht mit 11.53 dem Q1, der mittlere dicke Balken in der Box entspricht mit 12.64 dem Median (Q2) und der obere Rand mit 13.56 dem Q3.
Der IQR beträgt 2.03 (Q3-Q1).
Ausreisser (1.5*2.03 = 3.045) wären Werte, die kleiner als 8.48 (11.53-3.05) oder grösser als 16.61 (13.56 + 3.05) wären. Diese Werte gibt es im Datensatz nicht.
grafik <- df_work %>% ggplot() grafik + geom_boxplot(aes(y=price)) + theme_minimal() + labs(title = "Boxplot of transaction price") + theme(plot.title = element_text(hjust = 0.5), axis.text.x = element_blank(), axis.ticks.x = element_blank())
b) Gruppierte Boxplots mit der Funktion geom_boxplot()
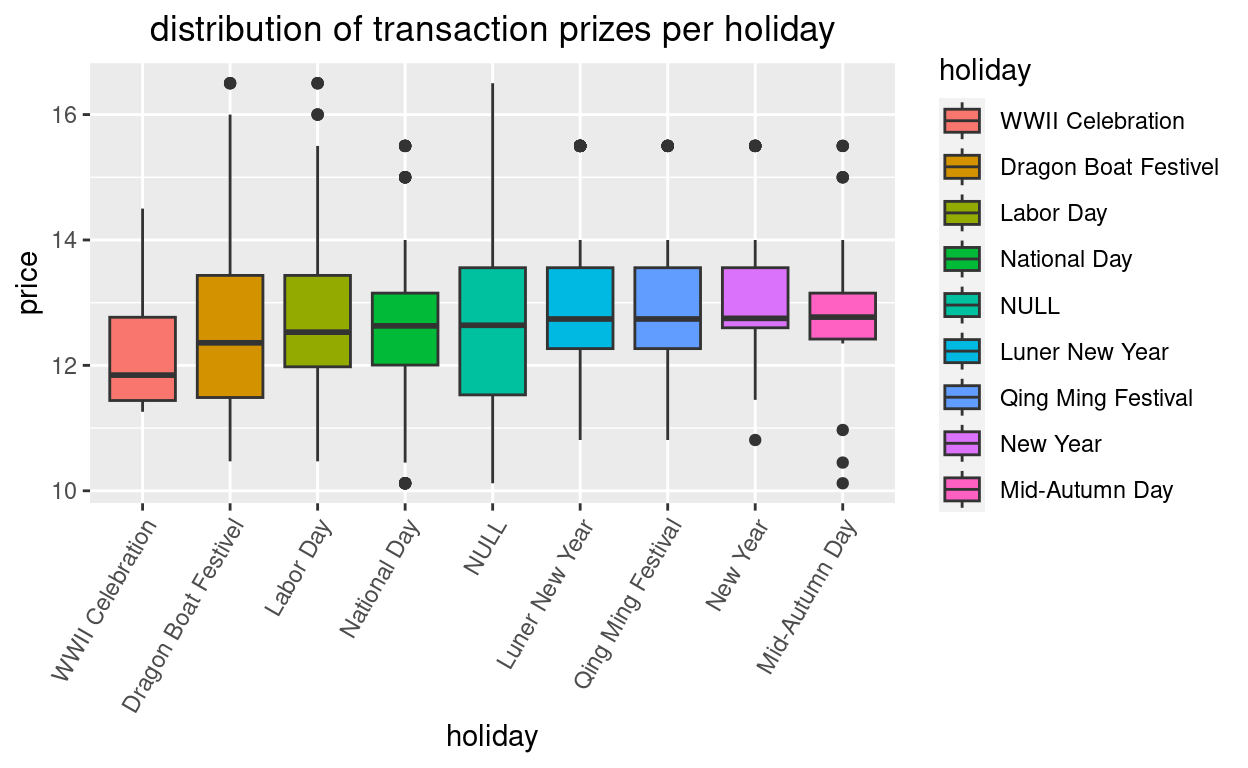
Wir interessieren uns für die Verteilung der Transaktionspreise über die einzelnen (Nicht- &) Feiertage. Wir gruppieren nach der Variable “holiday” und erhalten je einen Boxplot für die Verteilung der Transaktionspreise. Vorab sortieren wir nach dem Median.
Lesebeispiel: Der Mediantransaktionspreis ist am höchsten am “Mid-Autumn Day”, wobei dort die Transaktionspreise - abgesehen von wenigen Aussreissern - am homogensten sind. An Nicht Feiertagen (Kategorie: NULL) ist die Streuung grösser als an den meisten Feiertagen (es gibt aber auch bedeutend mehr getätigte Transaktionen an Nicht Feiertagen (da es mehr Nicht-Feiertage gibt) - also mehr Messungen).
grafik <- df_work %>% mutate(holiday = reorder(holiday, price, FUN = median)) %>% # Sortieren nach Median ggplot() grafik + geom_boxplot(aes(x = holiday, # Gruppierung y = price, fill = holiday)) + # Balkenfarbe nach Gruppe labs(title = "distribution of transaction prizes per holiday") + theme(plot.title = element_text(hjust = 0.5), axis.text.x = element_text(angle = 60, vjust = 1, hjust = 1))
4. Streudiagramme
a) Einfache Streudiagramme mit der Funktion geom_point()
- Zur grafischen Veranschaulichung von Zusammenhängen von kontinuierlichen bzw. metrischen Variablen (un- oder gruppiert) (bspw. Preis, Alter, Einkommen) verwenden wir Streudiagramme.
Eine detaillierte Darstellung aller Funktionen und Möglichkeiten zur Erstellung von Streudiagrammen finden Sie hier: https://ggplot2.tidyverse.org/reference/geom_point.html
Beispiel:
Wir wollen uns den Zusammenhang zwischen der durchschnittlichen Temperatur pro Monat und dem mittleren Preis (pro Monat) in einem Streudiagramm anschauen (der Pearson Korrelationskoeffizient liegt bei (nicht signifikant) -0.09). Zur Veranschaulichung erstellen wir ein Grafikobjekt. Abschliessend übergeben wir die Variablen und Formatierungen
lokalan die “geom_…() - Funktion”, die den Diagrammtyp definiert.grafik <- df_work %>% mutate(calendar_date = ymd(calendar_date), year_month = as.Date(format(calendar_date, "%Y-%m-01"))) %>% group_by(year_month) %>% summarise(monthly_mean_temp = mean(average_temperature, na.rm = TRUE), monthly_mean_price = mean(price, na.rm = TRUE)) %>% ungroup() %>% filter(year_month != "2015-09-01") %>% ggplot() grafik + geom_point(aes(x = monthly_mean_temp, y = monthly_mean_price)) + theme_minimal() + labs(title = "Correlation of avg_temp and avg_price")
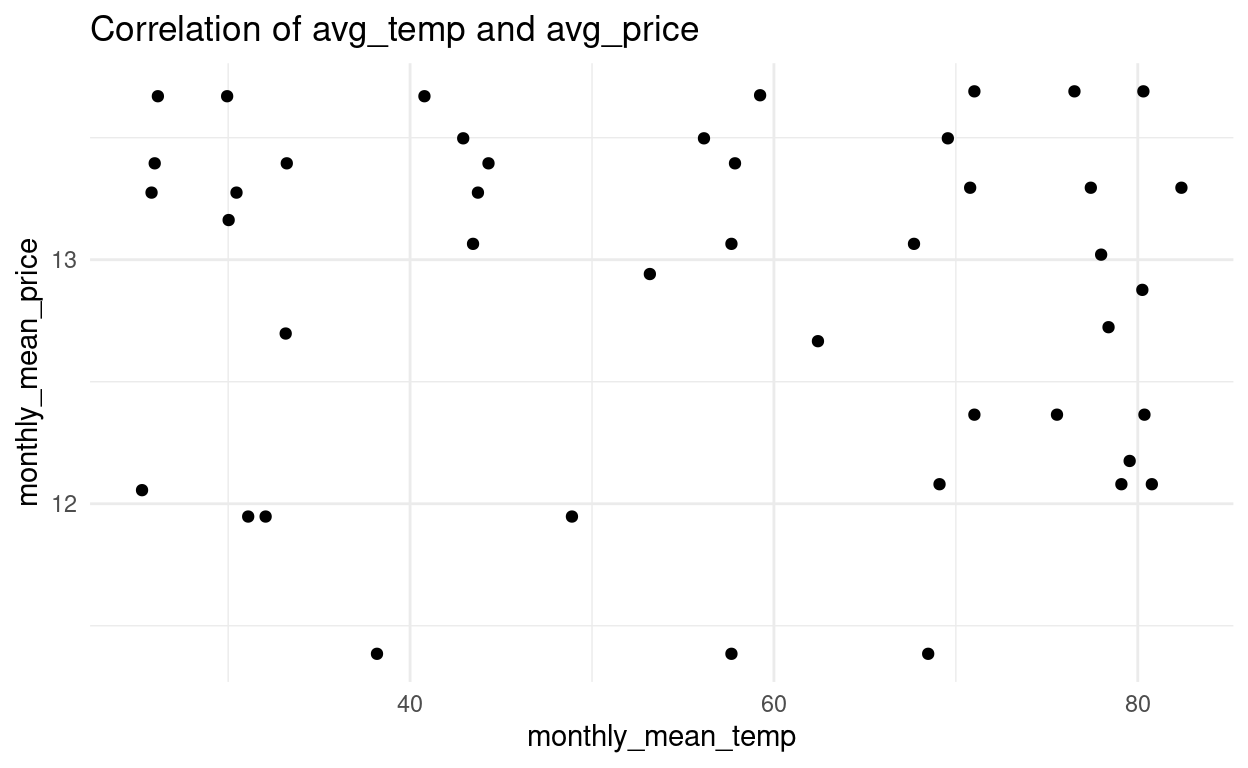
b) Gruppierte Streudiagramme mit der Funktion geom_point()
Beispiel
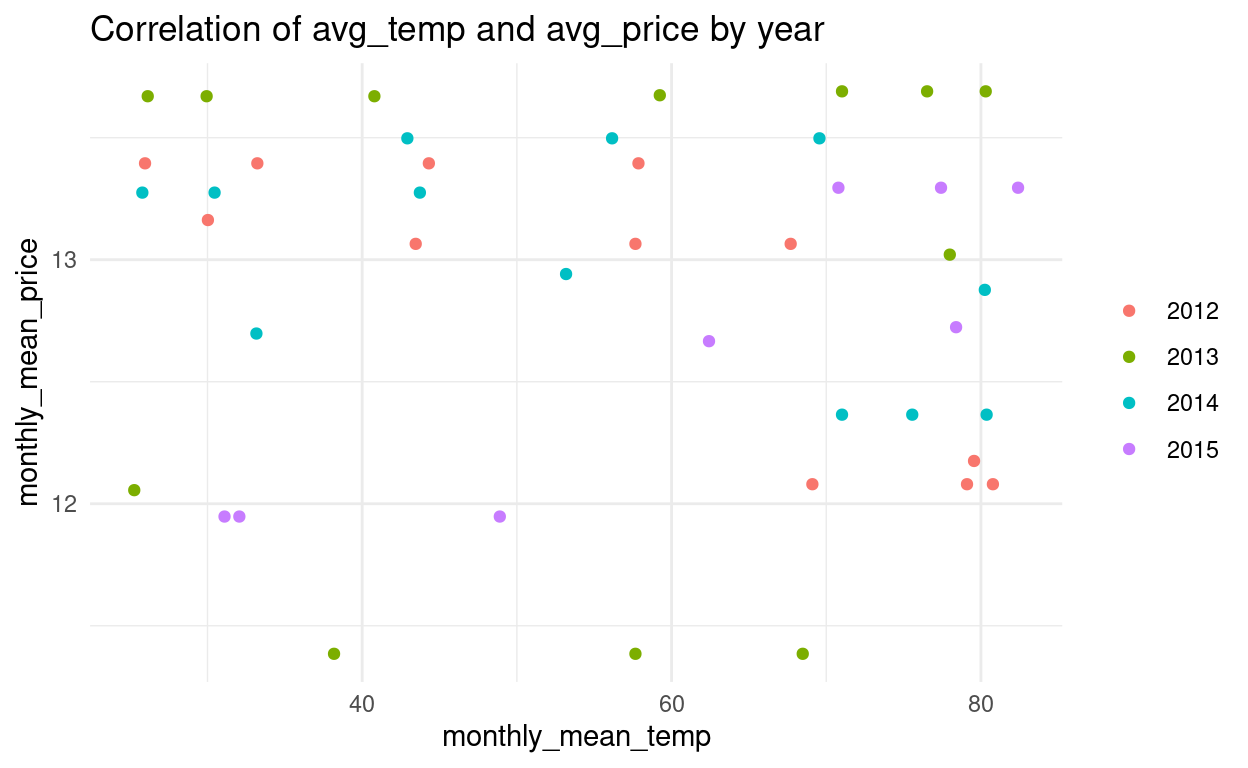
Wir wollen uns den Zusammenhang zwischen der durchschnittlichen Temperatur pro Monat und dem mittleren Preis (pro Monat) in einem Streudiagramm, gruppiert nach dem Jahr, anschauen. Wir erstellen dazu ein Grafikobjekt. Abschliessend übergeben wir die Variablen und Formatierungen
lokalan die “geom_…() - Funktion”, die den Diagrammtyp definiert.grafik_g <- df_work %>% mutate(calendar_date = ymd(calendar_date), month = month(calendar_date, label = TRUE, locale = "de_DE.UTF-8"), year = year(calendar_date)) %>% group_by(year, month) %>% summarise(monthly_mean_temp = mean(average_temperature, na.rm = TRUE), monthly_mean_price = mean(price, na.rm = TRUE)) %>% ungroup() %>% filter(!(year == 2015 & month == "Sep")) %>% ggplot() grafik_g + geom_point(aes(x = monthly_mean_temp, y = monthly_mean_price, group = year, color = as.factor(year))) + theme_minimal() + labs(title = "Correlation of avg_temp and avg_price by year") + theme(legend.title = element_blank())
5. Liniendiagramme
a) Einfache Liniendiagramme mit der Funktion geom_line()
Zur grafischen Veranschaulichung der zeitlichen Entwicklung (Veränderung) von kontinuierlichen bzw. metrischen Variablen (un- oder gruppiert) (bspw. Preis, Alter, Einkommen) verwenden wir Liniendiagramme.
Eine detaillierte Darstellung aller Funktionen und Möglichkeiten zur Erstellung von Liniendiagrammen finden Sie hier: https://ggplot2.tidyverse.org/reference/geom_path.html
Beispiel:
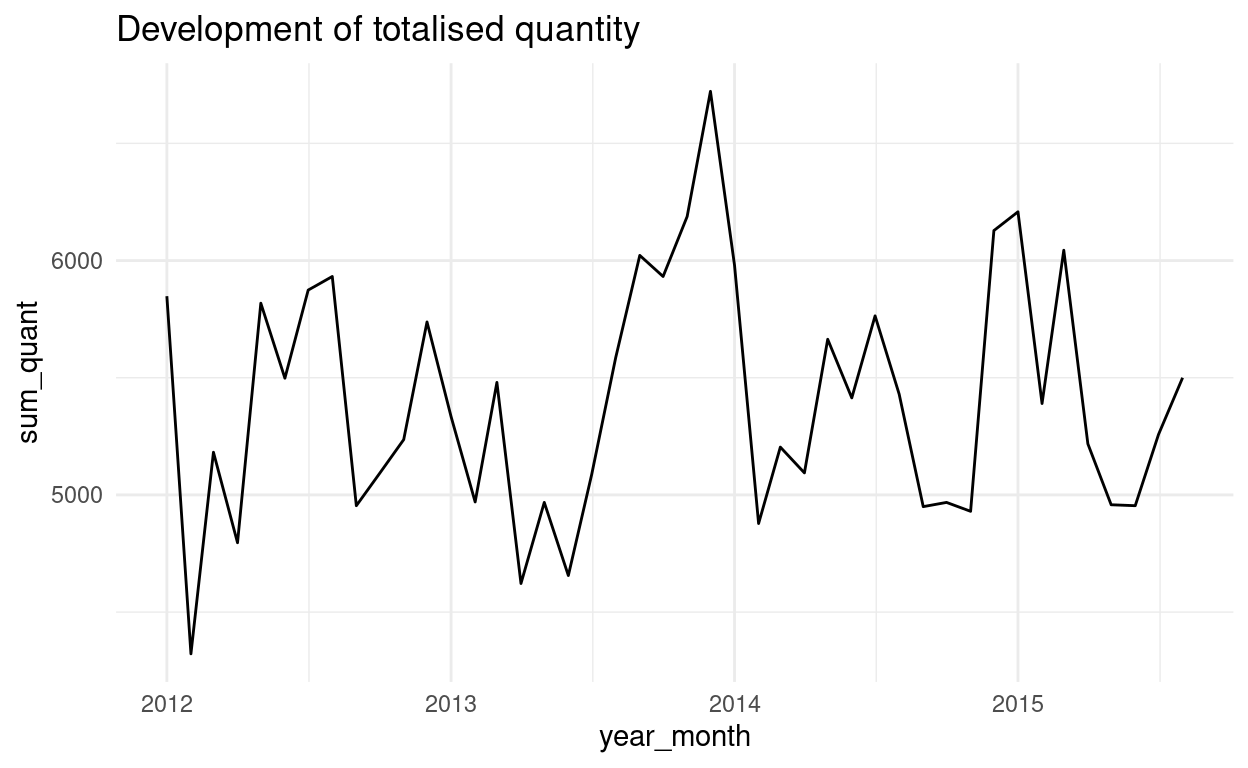
Wir wollen uns den zeitlichen Verlauf der Summe der verkauften Mengen pro Monat in einem Liniendiagramm anschauen. Wir erstellen dazu ein Grafikobjekt. Abschliessend übergeben wir die Variablen und Formatierungen
lokalan die “geom_…() - Funktion”, die den Diagrammtyp definiert.grafik <- df_work %>% mutate(calendar_date = ymd(calendar_date), year_month = as.Date(format(calendar_date, "%Y-%m-01"))) %>% group_by(year_month) %>% summarise(sum_quant = sum(quantity, na.rm = TRUE)) %>% ungroup() %>% filter(year_month != "2015-09-01") %>% ggplot() grafik + geom_line(aes(x = year_month, y = sum_quant)) + theme_minimal() + labs(title = "Development of totalised quantity")
b) Gruppierte Liniendiagramme mit der Funktion geom_line()
Beispiel
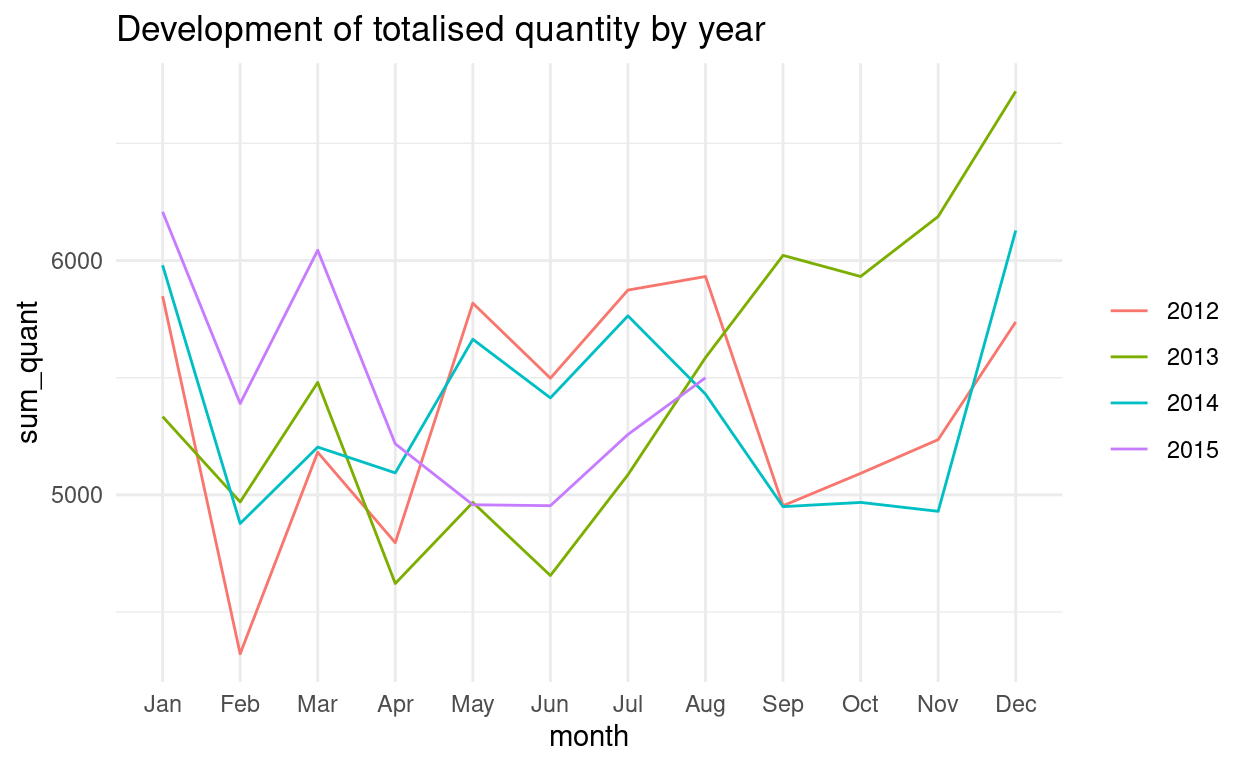
Wir wollen uns den zeitlichen Verlauf der Summe der verkauften Mengen pro Monat, gruppiert nach Jahr, in einem Liniendiagramm anschauen. Wir erstellen dazu ein Grafikobjekt. Abschliessend übergeben wir die Variablen und Formatierungen
lokalan die “geom_…() - Funktion”, die den Diagrammtyp definiert.Um die Grafik speichern zu können, speichern wir sie im Grafikobjekt “my_plot”.
grafik_g <- df_work %>% mutate(calendar_date = ymd(calendar_date), month = month(calendar_date, label = TRUE, locale = "de_DE.UTF-8"), year = year(calendar_date)) %>% group_by(year, month) %>% summarise(sum_quant = sum(quantity, na.rm = TRUE)) %>% ungroup() %>% filter(!(year == 2015 & month == "Sep")) %>% ggplot() grafik_g + geom_line(aes(x = month, y = sum_quant, group = year, color = as.factor(year))) + theme_minimal() + labs(title = "Development of totalised quantity by year") + theme(legend.title = element_blank())
Speichern von Grafiken
Abschliessend speichern wir die Grafik mit der Funktion
ggsave()impng- Format (auch andere Formate sind möglich)unter dem Namen “Linien_g.png” in unserem Arbeitsverzeichnis (png = portable network graphics).ggsave(filename = "linien_g.png", plot = my_plot)
Übung II
Nutzen Sie Ihr lokales R-Skript “05_Graphics_1.R” und vervollständigen Sie es Schrittweise nach jeder Übungsaufgabe.
Bei einigen der direkten Multiple Choice Aufgaben ist es sicher hilfreich, wenn Sie die Syntax zur Lösungsfindung jeweils lokal bei sich in R ausprobieren.
Am Ende der Übung werden die Dozierenden mit Ihnen die Lösungen besprechen.
Sie arbeiten in den folgenden Aufgaben erneut mit dem nach Datum aggregierten Datensatz “ag”. Er beinhaltet diesselben Variablen wie der df_work - Data Frame, allerdings jeden Tag nur einmal. Alle Werte pro Tag sind Durchschnittswerte.
Nutzen Sie für Ihre Lösungen der folgenden Aufgaben bitte die lokalen aes() in der jeweiligen geom_...() Funktion, wie bspw.:
ag %>%
ggplot() +
geom_...(aes(x = , y = ), fill = )1
Erstellen Sie mit der Variable “temp”, der Temperatur in Grad Celsius ein einfaches Histogramm mit Balkenbreite 2 Grad Celsius und schwarzer Umrandung der Balken.ag %>%
ggplot() +
geom_histogram(aes(x = temp), binwidth = 2, color = "black")
2
Formatieren Sie das Diagramm als “theme_minimal”. Fügen Sie dem Histogramm nun mit der Funktionscale_fill_gradient(low = "blue", high = "red") eine Farbpalette hinzu. Ergänzen Sie dazu in den “aes() bei geom_histogram” noch “fill = ..x..”. So werden die Werte der X-Achse zur Füllung verwendet. Geben Sie dem Diagramm abschliessend der Titel “temperature of sales days”.
ag %>%
ggplot() +
geom_histogram(aes(x = temp, fill = ..x..), binwidth = 2, color = "black") +
theme_minimal() +
scale_fill_gradient(low = "blue", high = "red") +
labs(title = "temperature of sales days") +
theme(plot.title = element_text(hjust = 0.5))
3
Wie man bei der Abbildung in der vorhergenden Aufgabe gut sehen kann, handelt es sich um eine sogenannte - Bimodale Verteilung - da sie 2 Gipfel hat. Beantworten Sie dazu folgende Quizfrage.
4
Wir wollen nun grafisch untersuchen, ob sich die Temperaturen zwischen den Kategorien der Variable “is_outdoor” stark voneinander unterschieden haben. Erweitern Sie die obige Syntax um die Option “group” und erstellen Sie ein gruppiertes Histogramm.ag %>%
ggplot() +
geom_histogram(aes(x = temp, fill = ..x..), binwidth = 2, color = "black") +
theme_minimal() +
scale_fill_gradient(low = "blue", high = "red") +
labs(title = "temperature of sales days") +
theme(plot.title = element_text(hjust = 0.5))ag %>%
ggplot() +
geom_histogram(aes(x = temp, fill = ..x.., group = is_outdoor), binwidth = 2, color = "black") +
theme_minimal() +
scale_fill_gradient(low = "blue", high = "red") +
labs(title = "temperature of sales days") +
theme(plot.title = element_text(hjust = 0.5))
5
Leider lässt die gewählte Farbpalette keine detaillierten Vergleiche zu. Erstellen Sie das Histogramm anhand der unten abgebildeten Syntax erneut. Ändern Sie es diesmal so, dass pro Gruppe nur eine einheitliche Farbe angezeigt wird. Löschen Sie dazu zuerst die Zeile: “scale_fill_gradient(low =”blue“, high =”red“) +” und nehmen Sie dann noch eine weitere Veränderung vor.ag %>%
ggplot() +
geom_histogram(aes(x = temp, fill = ..x.., group = is_outdoor), binwidth = 2, color = "black") +
theme_minimal() +
scale_fill_gradient(low = "blue", high = "red") +
labs(title = "temperature of sales days") +
theme(plot.title = element_text(hjust = 0.5))ag %>%
ggplot() +
geom_histogram(aes(x = temp, fill = is_outdoor, group = is_outdoor), binwidth = 2, color = "black") +
theme_minimal() +
labs(title = "temperature of sales days") +
theme(plot.title = element_text(hjust = 0.5))
6
Nun lässt die Grafik zwar Vergleiche zu, ist aber immer noch schlecht zu “lesen”. Ändern Sie die Syntax, sodass die Diagramme hintereinander, statt aufeinander, abgebildet werden. Ändern Sie auch die Transparenz, sodass sich die Lesbarkeit nochmals erhöht und beantworten Sie danach die Quizfrage.ag %>%
ggplot() +
geom_histogram(aes(x = temp, fill = ..x.., group = is_outdoor), binwidth = 2, color = "black") +
theme_minimal() +
scale_fill_gradient(low = "blue", high = "red") +
labs(title = "temperature of sales days") +
theme(plot.title = element_text(hjust = 0.5))ag %>%
ggplot() +
geom_histogram(aes(x = temp, fill = is_outdoor, group = is_outdoor), binwidth = 2, color = "black", position = "identity", alpha = 0.3) +
theme_minimal() +
labs(title = "temperature of sales days") +
theme(plot.title = element_text(hjust = 0.5))7
8
Im letzten Teil der Übung geht es nun um die Unterschung der mittleren Menge verkaufter Produkte im Betrachtungszeitraum von 4 Jahren. Erstellen Sie einen Boxplot mit “theme_minimal”, der die Verteilung der Variable “quantity” zeigt.ag %>%
ggplot() +
geom_boxplot(aes(y=quantity)) +
theme_minimal()
9
Geben Sie dem Diagramm den Titel “boxplot”. Löschen Sie die X-Achsen Werte (inkl. Ticks) und zentrieren Sie den Diagrammtitel. Beantworten Sie die folgenden 2 Quizfragen.ag %>%
ggplot() +
geom_boxplot(aes(y=quantity)) +
theme_minimal()ag %>%
ggplot() +
geom_boxplot(aes(y=quantity)) +
theme_minimal() +
labs(title = "Boxplot of quantity") +
theme(plot.title = element_text(hjust = 0.5),
axis.text.x = element_blank(),
axis.ticks.x = element_blank())
10
11
12
Gruppieren Sie nun nach der Variable “is_schoolbreak” um zu prüfen, ob bzw. wie sich die Verteilung der verkauften mittleren Menge zwischen Schulferien und nicht Ferienzeiten unterscheidet. Wählen Sie als Diagrammtitel “distribution of mean sold quantity by schoolbreak” und unterdrücken Sie den X-Achsentitel und die Achsenbezeichnung.ag %>%
ggplot() +
geom_boxplot(aes(y=quantity)) +
theme_minimal() +
labs(title = "Boxplot of quantity") +
theme(plot.title = element_text(hjust = 0.5),
axis.text.x = element_blank(),
axis.ticks.x = element_blank())ag %>%
ggplot() +
geom_boxplot(aes(x = is_schoolbreak, y=quantity, fill = is_schoolbreak)) +
labs(title = "distribution of mean sold quantity by schoolbreak") +
theme(plot.title = element_text(hjust = 0.5),
axis.text.x = element_blank(),
axis.ticks.x = element_blank(),
axis.title.x = element_blank())
Anwendungsaufgabe
Bearbeiten Sie die folgenden Aufgabenstellungen hier bei RAPP im vorgegebenen Feld weiter unten.
Die folgende Syntax erzeugt einen Beispieldatensatz im long-Format. Laden Sie dazu vorab den Datensatz df_work als Data Frame.
ag1 <- df_work %>%
mutate(date = as.Date(date)) %>%
select(date,price,quantity,is_outdoor,is_weekend) %>%
aggregate(. ~ date, ., FUN=mean, na.rm=TRUE) %>%
mutate(we=recode(is_weekend, '0'='no weekend', '1'='weekend'),
week=as.factor(is_weekend),
locat=as.factor(is_outdoor),
loc = recode(is_outdoor,'0'='indoor','1'='outdoor'),
revenue = round(price*quantity, 2))
head(ag1)
Erstellen Sie mit den Variablen im Data Frame “ag” die folgenden 2 Diagramme.
Beginnen Sie mit der Konstruktion wie folgt:
grafik1 <- ag1 %>% ggplot()
(a) gruppierte Histogramme - Balken übereinander
Tipp: Sie können die verwendete Balkenbreite aus der Abbildung schlussfolgern.
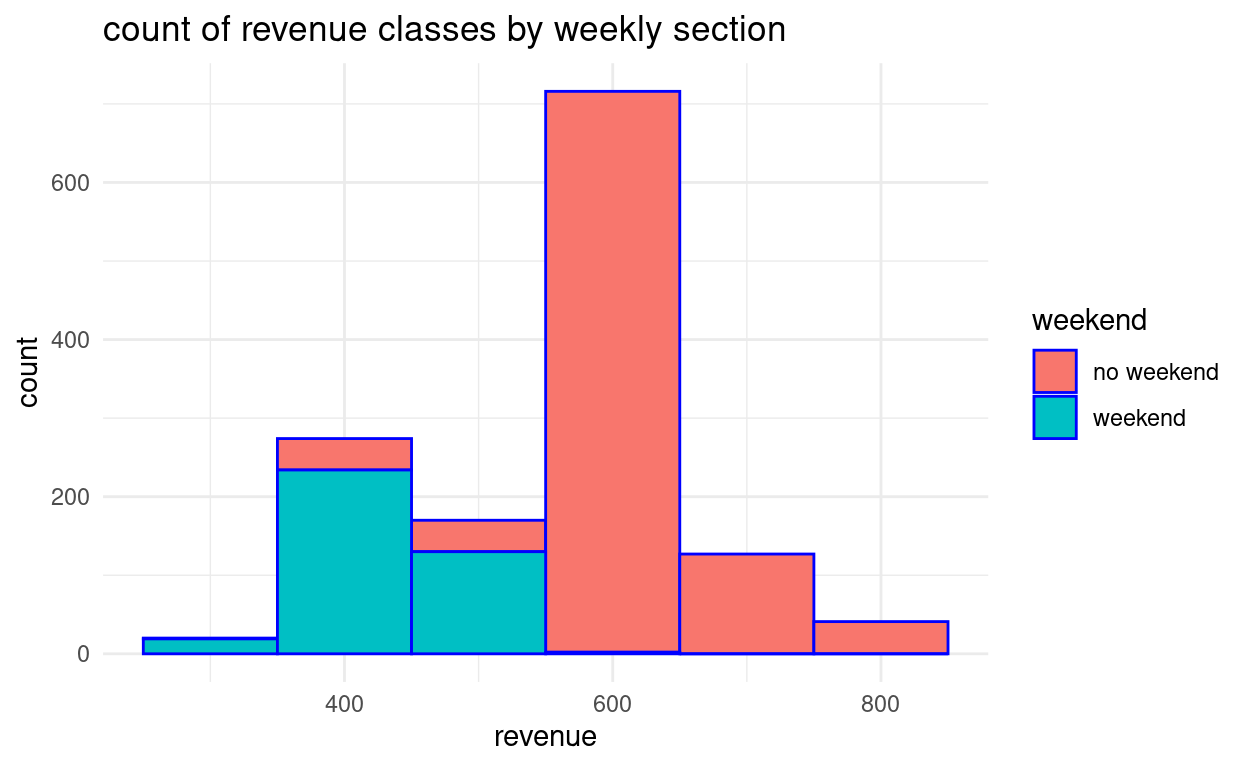
(b)
Tipp: Wenn Sie das Diagramm korrekt erstellen, müssen Sie zusätzlich nur noch das “Thema” ändern, den Titel vergeben und ihn zentrieren.
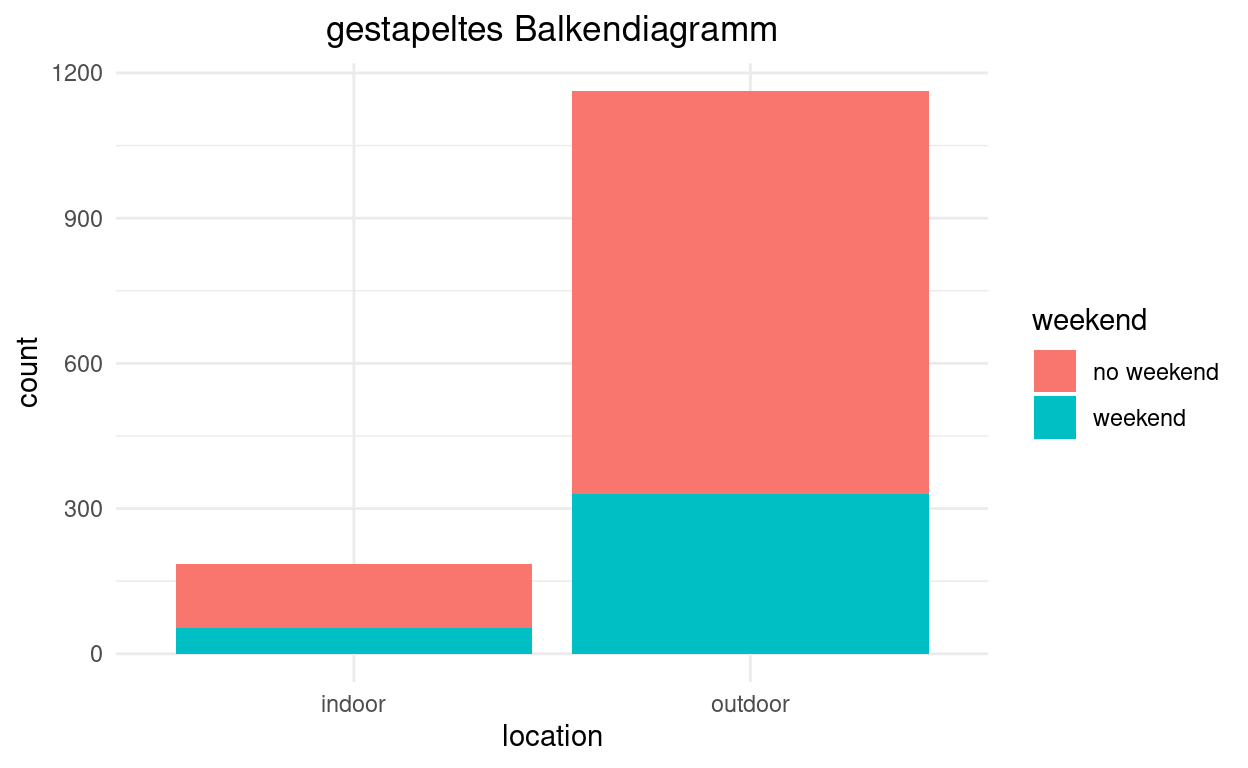
Laden Sie nun das aktualisierte R-Skript herunter und speichern Sie es lokal in Ihrem Projektordner.
Was haben wir gelernt:
Wir wissen, welche Diagrammtypen für welche Messniveaus geeignet sind.
Wir wissen, wie wir mit dem package gplot(2) das Grundprinzip der Grafikerstellung umsetzen und was der Unterschied zwischen lokalen und globalen aes() ist.
Wir können einfache und gruppierte (stacked oder dodge) Balkendiagramme für abs. und rel. Häufigkeiten erstellen.
Wir können einfache und gruppierte Histogramme für abs. und rel. Häufigkeiten, auf- oder hintereinander angezeigt, erstellen.
Wir können einfache und gruppierte Boxplots zur Anzeige der Verteilung von kontinuierlichen Variablen erstellen.
Wir können einfache und gruppierte Streudiagramme zur Anzeige des (potentiellen) Zusammenhangs von kontinuierlichen Variablen erstellen.
Wir können einfache und gruppierte Liniendiagramme zur Anzeige der zeitlichen Entwicklung/Veränderung von kontinuierlichen Variablen erstellen.