
Tools in DataScience 4: data wrangling III
Hinweis:
- An jenen Stellen, die mit einem Graduation-Cap gekennzeichnet sind , erarbeiten Sie sich die Inhalte selbständig
- An Stellen mit einer Wandtafel warten Sie bitte auf Input seitens der Dozierenden
Worum geht es in dieser Sitzung:
Manchmal enthalten Datentabellen die Daten in einer nur schwer zu verarbeitenden, ungeordneten Struktur.
Daten in dieser Form haben ein breites bzw. wide - Format, d.h. jede Zeile enthält mehrere Beobachtungen und eine (oder mehrere) der Variablen ist (sind) in der Kopfzeile gespeichert.
Um nun Diagramme und Auswertungen einfach umsetzen zu können, werden solche Datensätze zu Beginn geordnet. Daten in dieser Form haben dann ein long - Format, d.h. sie enthalten in jeder Zeile eine Beobachtungseinheit (bei Mehrfachmessungen dann auch noch für den jeweiligen Zeitpunkt) und in jeder Spalte je eine Variable, die die gesammelten Daten zur Beobachtungseinheit beinhaltet.
Für die Daten aus unserem Beispiel könnte dies so aussehen:
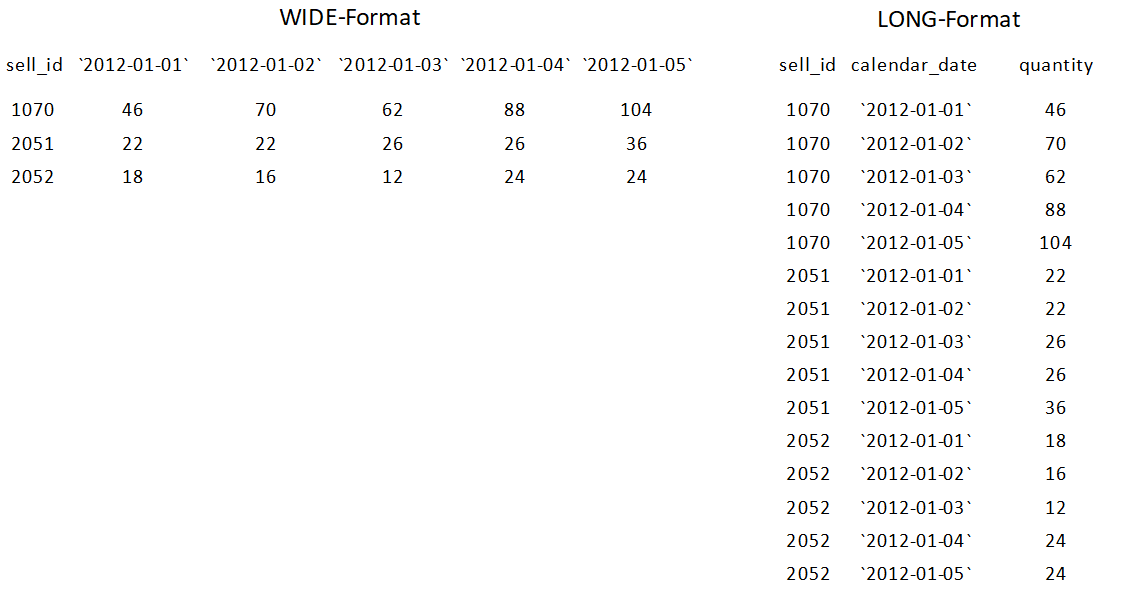
Links, im wide-Format, gibt es
pro Verkaufs-IDeine Variable mit demTagesdatum (calendar_date)als Name,in der die verkaufte Menge (quantity)zur jeweiligen Verkaufs-ID abgespeichert ist.Rechts sieht man dieselben Daten im long-Format, d.h. es gibt zu jeder
Verkaufs-ID (sell_id)je einen Eintrag bei der VariableDatum (calendar_date)und bei der VariableMenge (quantity). Wie Sie sehen, ist das long-Format gerade für grosse Datenmengen aus Gründen der Übersichtlichkeit und der Bearbeitungsmöglichkeiten besser geeignet.
Damit Sie Datensätze in die für Ihre Fragestellung passende Form bringen können, beschäftigen wir uns in dieser Sitzung mit dem Umformen (reshape) von Datensätzen bzw. Data Frames.
Am Ende der Sitzung streben wir ein finales Datenblatt bzw. einen Data Frame an, der alle relevanten Informationen der Teildatensätze zu unserem Datenbeispiel im long-Format enthält, der also geordnet ist.
Umformen von Datentabellen in R
Installation des tidyr packages
Das Umformen von Datentabellen ist in R - und generell bei der Arbeit mit grösseren Datensätzen - ein wichtiger Arbeitsschritt. Entsprechend gibt es als Teil der tidyverse- package Sammlung ein eigenes package tidyr.
Mithilfe der Funktionen des *tidyr - package** in RStudio können wir Datentabellen umformen.
Wir installieren das package und laden die Bibliothek.
install.packages("tidyr")
library(tidyr)Weitere Informationen zum “tidyr - package” finden Sie unter:
https://tidyr.tidyverse.org/index.html
Dort können Sie auch das entsprechende cheat sheet herunterladen: https://github.com/rstudio/cheatsheets/blob/main/tidyr.pdf
Funktion zur Umformung von Datentabellen (long-wide, wide-long)
Zur Erinnerung:
Wir hatten die 3 Datensätze am Ende der letzten Sitzung und in der Hausaufgabe mit der Funktionleft_join()verbunden. Der Datensatzdf_work enthält 16 Spalten und 5404 Zeilen, wobei dieZeile jeweils eine Transaktiondarstellt - also den Verkauf eines bestimmten Produkts (allein oder in Kombination mit anderen Produkten) an einem bestimmten Tag.Pro Tag kann es bis zu 7 verschiedene Transaktionengeben, da die unterschiedlichen Produkte als Einzel- oder, gegebenenfalls, in einem 2er oder 3er Menü verkauft worden sind (siehe “sell_id”).Datenauszug:
1. pivot_wider() - Umformen von Daten vom long- ins wide-Format.
- Um Daten vom long- ins wide-Format umformen zu können, verwenden wir die Funktion pivot_wider(). Dieser Fall tritt seltener auf als die Umformung vom wide- ins long-Format, kann aber mitunter für die Datenbearbeitung ein nützlicher Zwischenschritt sein.
- Das Argument names_from sagt uns, welche Variable für die Spaltennamen verwendet wird (als Grundeinstellung wird der Name “names” vergeben). Das Argument values_from sagt uns, aus welcher Variable die einzelnen Zelleinträge stammen (als Grundeinstellung wird eine Variable “value” vergeben).
- Es ist auch möglich die Spaltennamen auf mehrere Variablen anzuwenden. Das verkompliziert die Datenstruktur weiter.
- Neben weiteren Detaileinstellungen können Sie u.a. das Trennzeichen - Grundeinstellung ist Unterstrich "_" - zu anderen Zeichen ändern. Dies geschieht mit
names_sep = "gewünschtes Trennzeichen". NA Wertewerden dann produziert, wenn für bestimmte Wertpaarkombinationen keine Werte auftreten. Im folgenden Beispiel wurden am 03.01.2012 die sell_ids “2052 und 2053” nicht verkauft. Entweder filtern Sie diese Werte vorab filter(!is.na(Variablennamen)) oder ersetzen Sie durch einen Wert - hier bspw. 0. Dies kann mit der Option values_fill = 0 erreicht werden. In manchen Fällen kann pivot_wider() aus zur Aggregation über bestimmte Merkmalskombinationen verwendet werden.
Beispiel A1:
Im Folgenden sehen Sie den vorhergehenden Auszug aus unserem Beispieldatensatz, der ins
wide-formatüberführt wurde. In dieser Form ist die Datennutzung für weitere Anwendungen meist mit Mehraufwand verbunden und deshalb eher ungeeignet.Lesebeispiel: Die sell_id = 1070 steht bspw. für den Einzelverkauf eines Burgers, die sell_id = 2053 steht für den Verkauf eines Menüs, nämlich der Kombination von Burger, Cola und Kaffee. In der jeweiligen Zeile der
sell_idbeinhalten die Variablen2012-01-01bis2012-01-03etc. die Menge der verkauften Einzelprodukte bzw. der verkauften Menüs an diesem Tag. Am 01.01.2012 wurden bspw. “46 Burger (single) und 30 Menüs (Burger, Cola, Kaffee)” verkauft. Hingegen waren es am 03.01.2012 “62 Burger (single) und kein Menü (Burger, Cola, Kaffee)”.test <- df_work %>% select(calendar_date, sell_id, quantity) %>% slice(1:10) wide <- test %>% pivot_wider(names_from = calendar_date, values_from = quantity) widewide <- test %>% pivot_wider(names_from = calendar_date, values_from = quantity, values_fill = 0) wide
Beispiel A2
Im Folgenden sehen Sie den vorhergehenden Auszug aus unserem Beispieldatensatz, der ins
wide-formatüberführt wurde. Diesmal gibt es zwei unterschiedliche Variablen, die pro Datum abgespeichert worden sind.Lesebeispiel: Die sell_id = 1070 steht bspw. für den Einzelverkauf eines Burgers, die sell_id = 2053 steht für den Verkauf eines Menüs, nämlich der Kombination von Burger, Cola und Kaffee. In der jeweiligen Zeile der
sell_idbeinhalten die Variablenprice_2012-01-01undprice_2012-01-02die Preise der verkauften Einzelprodukte bzw. der verkauften Menüs an diesem Tag. Am 01.01.2012 wurden bspw. “Burger (single)” zum Preis von 15.5 US$ und “Bürgermenüs (Burger, Cola, Kaffee)” zum Preis von 12.6 US$ verkauft (zur Erklärung der Preise von Single- und Menüprodukten erinnern wir uns an die detaillierte Datenbeschreibung in Sitzung II: tiefere Preise bei Menüs sind den geringeren Mengen bzw. Portionsgrössen geschuldet). Äquivalent dazu sehen Sie die Tagesmengen pro Produkt in den Spaltenquantity_2012-01-01undquantity_2012-01-02.test <- df_work %>% select(calendar_date, sell_id, price, quantity) %>% slice(1:8) testwide <- test %>% pivot_wider(names_from = calendar_date, values_from = c("price", "quantity")) wide
2. pivot_longer() - Umformen von Daten vom wide- ins long-Format.
- Um Daten vom wide- ins long-Format umformen zu können, verwenden wir die Funktion pivot_longer(). Dieser Fall tritt häufiger auf als die Umformung vom long- ins wide-Format.
- Das erste Argument der Funktion sagt uns, welche(r) Data Frame bzw. Datentabelle umgeformt werden soll.
- Das zweite Argument benennt die Spalten, deren Werte in jeweils neue Variablen eingerückt werden sollen. Dabei kann man bspw.
einzelne(Auswahl: cols = var1) (Abwahl: cols = -var1, d.h. alle Variablen ausser var1)oder mehrere Variablennamen für die Umformung aus- oder abwählen(bspw. cols = var1:var3; cols = c(holiday, sell_category); -c(holiday, sell_category)). Mitstarts_with("Zeichenkette")(z.B. 2012) können Spalten, die mit bestimmten Zeichenketten beginnen; miteverything()alle Spalten zum Umwandeln ausgewählt werden. - Die neue Spalte, die die ursprünglichen Namen der Variablen enthält, und die neue Spalte mit den Werten können mit den Befehlen
names_to = ..undvalues_to = ..benannt werden. Auch hier gibt es viele Unteroptionen. Bspw. kann man mitnames_prefix = "Zeichenkette"feste Zeichenketten in den Variablennamen beim Umformen entfernen. Die Optionnames_to = .valueserlaubt Werte aus den Spaltennamen direkt den Werten in den neu angelegten Spalten zuzuweisen. - Abschliessend können wir mit dem Befehl
values_drop_na =Fehlwerte ausschliessen und mitnames_transform = list()die Klasse einer Variable abändern (numeric, date, ..).
Beispiel B1:
Im Folgenden sehen Sie erneut das vorhergehende Datenbeispiel A1 im
wide-Format.wideDie Daten werden nun mit der Funktion pivot_longer() ins
long-Formatüberführt.
Lesebeispiel: In der Spalte
sell_idstehen die Verkaufsnummern der Produkte. Die sell_id = 1070 steht bspw. für den Einzelverkauf eines Burgers, die sell_id = 2053 steht für den Verkauf eines Menüs, nämlich der Kombination von Burger, Cola und Kaffee. In der jeweiligen Zeile descalendar_datesteht der Tag, an dem das Produkt verkauft wurde. Am 01.01.2012 wurden - 46 Burger (single) (sell_id = 1070) und 30 Menüs (Burger, Cola, Kaffee) (sell_id = 2053) - verkauft. Hingegen waren es am 03.01.2012 - 62 Burger (single) und kein Menü (Burger, Cola, Kaffee) - , da es keinen Eintrag zur sell_id = 2053 am 03.01.2012 gibt (hier als “NA” ausgewiesen).long<-pivot_longer(wide, `2012-01-01`:`2012-01-03`, names_to = "calendar_date", values_to = "quantity", values_drop_na = FALSE) longDie Daten wurden nun mit der Funktion pivot_longer() ins
long-Formatüberführt. Statt die umzuformenden Spalten zu nennen, können wir im Beispiel auch die “sell_id” (die nicht umgeformt wird) ausschliessen. Zudem wollen wir keine neuen Zeilen für fehlende Werte hinzugefügt bekommen. Die Datumsvariable wird abschliessend wieder als Datum umgeformt (da sie durch die Umformung sonst als Character vorliegt).long <- wide %>% pivot_longer(-sell_id, names_to = "calendar_date", values_to = "quantity", values_drop_na = TRUE, names_transform = list(calendar_date=as.Date)) long
Beispiel B2:
Wir betrachten wieder die Daten aus Beispiel A2.
test <- df_work %>% select(calendar_date, sell_id, price, quantity) %>% slice(1:8) wide <- test %>% pivot_wider(names_from = calendar_date, values_from = c("price", "quantity")) wideMan kann diese zusammengesetzten Spalten nun u.a. wie folgt ins long Format umformen.
long <- wide %>% pivot_longer( cols = -sell_id, names_to = c(".value", "calendar_date"), names_sep = "_", names_transform = list(calendar_date=as.Date)) long
Übung I
Laden Sie nun das aktuelle R-Skript zur weiteren lokalen Bearbeitung der folgenden Übungsaufgaben herunter und speichern Sie es lokal in Ihrem Projektordner.
Lösen Sie die folgenden Übungsaufgaben und vervollständigen Sie das Skript Schrittweise nach jeder Übungsaufgabe.
Bei einigen der Multiple Choice Aufgaben ist es sicher hilfreich, wenn Sie die Syntax zur Lösungsfindung jeweils lokal bei sich in R ausprobieren.
Am Ende der Übung werden die Dozierenden mit Ihnen die Lösungen besprechen.
1
2
Sie haben den folgenden Ausschnitt aus dem Data Frame “df” im long-Format erhalten.
3
Sie haben den folgenden Ausschnitt aus dem Data Frame “df1” erhalten.df1 %>% pivot_wider(names_from = holiday, values_from = average_temperature)
4
Ihnen liegt der folgende Data Frame “df_new” vor.
5
Bei welcher der folgenden Darstellungen handelt es sich um Daten im long-Format?
6
Sie haben den folgenden Ausschnitt aus dem Data Frame “df” im wide-Format erhalten.Die Daten sollen in das folgende long-Format umgeformt werden.
7
Sie haben den folgenden Ausschnitt aus dem Data Frame “df3” erhalten.df3 %>% pivot_longer(`New Year`:`NULL`, names_to = "holiday",
values_to = "average_temp", values_drop_na = TRUE)
Laden Sie nun das aktualisierte R-Skript herunter und speichern Sie es lokal in Ihrem Projektordner.
Umformen von Spalten in Datentabellen in R
Sie wissen bereits, wie man Datentabellen zwischen wide und long - Format umformen kann.
Wir besprechen nun die wichtigsten Möglichkeiten, die man zum Verbinden oder Trennen von Spalten in Datentabellen braucht. Dies schliesst auch den Fall mehrerer, verschieden kombinierter Kopfzeilen bei Daten im wide - Format ein.
Funktionen für das Umformen von Spalten in Datentabellen
1. separate() - Aufteilung von Spalten in Datentabellen.
- Um Spalten in mehrere Spalten aufteilen zu können, verwenden wir die Funktion separate().
- Das erste Argument in der Funktion gibt an, welche Spalte bzw. Variable bearbeitet werden soll.
- Das zweite Argument wird meist als Vektor verwendet c(“var1”, “var2”) und gibt an, in welche Spalten bzw. Variablen die bearbeitete Spalte aufgeteilt werden soll.
- Das dritte Argument gibt das Zeichen an, welches zum Trennen verwendet werden soll. Sie können mittels der Option “sep =” Trennzeichen wie folgt festlegen:
als Zeichen: sep = “[
Zeichen]”als Position: sep =
Position)bei mehreren Zeichen: sep = “[
erstes Zeichen-letztes Zeichen]”
ODER: sep = “[Zeichen 1,Zeichen 2, …]”. Bspw. würden für Einträge der Art “price_48-34” oder “price-48_34” als Trennzeichen bei der Option sep = “[ _ -]” folgen.Unterscheidet sich die Zeichenanzahl zwischen Zeilen des Vektors, wird beim Separieren das Ergebnis durch die vorgegebene Anzahl neuer Spalten bestimmt.
Wenn die Trennzeichen zwischen den Spalten auch innerhalb der Spalten vorkommen (bspw. “sellid_2024_01_02” und man möchte zw. sellid und Datumseingabe separieren), kann bspw. die Unteroption “extra =” verwendet werden.
Beispiele:
Beispiel 1
Im Folgenden sehen Sie einen Auszug aus unserem Beispieldatensatz, der im
long-formatvorliegt. Es gibt allerdings fehlerhafte Einträge bei der Variable “calendar_date”, da Preis & Datum und Menge & Datum nicht voneinander getrennt. Zudem sind in der Spalte “values” die Werte von Preis und Menge zusammen abgespeichert. Wir beheben die fehlerhaften Einträge u.a. mit der separate-Funktion.data
Wir teilen im ersten Schritt die Variable calendar_date in 2 Variablen.
In der ersten variable - “name” - sollen die Bezeichnungen “price” und “quantity” gespeichert werden. In der zweiten Variable - “calendar_date” - soll das Datum erfasst werden
data %>% separate(calendar_date, c("name", "calendar_date"), sep = "_")
Nun ergänzen wir die Funktion
pivot_wider(). Im vorliegenden Beispiel können wir aufgrund der vorgebenen Datenstruktur mit dieser Funktion in ein geordnetes “long-Format” überführen.data %>% separate(calendar_date, c("name", "calendar_date"), sep = "_") %>% pivot_wider(names_from = name, values_from = values)
Beispiel 2:
Wir wollen bei der Variable “calendar_date” nur die Datumseinträge im folgenden Datenauszug beibehalten. Dazu behandeln wir den ersten Eintrag vor dem Trennzeichen als NA.
datadata %>% separate(calendar_date, c(NA, "calendar_date"), sep = "_")
Beispiel 3:
Wir wollen die Jahreseinträge und den Preis in 2 separaten Variablen speichern. Mit extra = “merge” behalten wir den letzten Eintrag in Zeile 1 und 3 (“34” und “50”, was eigentlich Nachkommastellen wären die falsch abgespeichert wurden) bei. Ohne “merge” würde bspw. die Zahl “50” im Eintrag bei Zeile 3 “43_50” gelöscht.
dfdf %>% separate(year_price, c("year", "price"), sep = "_", extra = "merge")
2. unite() - Verbinden von Spalten in Datentabellen.
- Um mehrere Spalten in einer Spalte zusammenfassen zu können, verwenden wir die Funktion unite().
- Das erste Argument in der Funktion gibt an, wie die neue zusammengefasste Spalte bzw. Variable heissen soll.
- Das zweite, dritte,..n-1 Argument gibt an, welche Spalten bzw. Variablen zusammengefasst werden sollen.
- Das letzte Argument gibt das Zeichen an, welches als Trennzeichen verwendet werden soll. Die Grundeinstellung ist “Unterstrich”.
Ein Auszug aus unseren Beispieldaten:
Im Folgenden sehen Sie einen Auszug aus unserem Beispieldatensatz. Die Variablen “name” und “calendar_date” sollen in einer Variable “name_date” zusammengeführt werden.
datZusammenführen der Variablen in einer neuen Variable "name_date" dat %>% unite(name_date, name, calendar_date, sep = "_")
Übung II
Nutzen Sie Ihr lokales R-Skript “04_Datawrangling_1.R” und vervollständigen Sie es Schrittweise nach jeder Übungsaufgabe.
Bei einigen der Multiple Choice Aufgaben ist es sicher hilfreich, wenn Sie die Syntax zur Lösungsfindung jeweils lokal bei sich in R ausprobieren.
Am Ende der Übung werden die Dozierenden mit Ihnen die Lösungen besprechen.
1
Erstellen Sie mit der Funktion separate() aus der Variable “price” zwei weitere Variable “price_1” und “price_2”. Price_1 soll nur die Vorkommastellen, price_2 nur die Nachkommastellen von “price” enthalten.df %>% separate(price, c("price_1", "price_2"), sep = "[.]")
2
Erstellen Sie mit der Funktion separate() aus der Variable “price” nur eine weitere Variable “price_2”, die nur die 2. Nachkommastelle von “price” enthält (Position 4). Ersetzen Sie dazu den Namen der ersten Variable in der separate()-Funktion Syntax mit NA.df %>% separate(price, c(NA, "price_2"), sep = 4)
3
Erstellen Sie mit der Funktion separate() aus der Variable “calendar_date” drei weitere Variablen “year”, “month” und “day”, die jeweils nur Jahr, Monat oder Tag beinhalten.df1<-df %>% separate(calendar_date, c("year", "month", "day"), sep = "-")
df1
4
Erweitern Sie die obige Syntax. Erstellen Sie mit der Funktion unite() aus den Variablen “year”, “month” und “day” eine neue Variable “date”, die alle Werte verbunden über “:” enthält.df %>%
separate(calendar_date, c("year", "month", "day"), sep = "-") %>%
unite(date, year, month, day, sep=":")
Im Folgenden sehen Sie unsere Beispieldaten im wide-Format. Diesmal wurden 3 Variablen mit der “calendar_date” kombiniert und in einem Data Frame “wide1” gespeichert.
5
Formen Sie die Daten im df “wide1” mittels der Funktion “pivot_longer()” so um, dass der folgende Output entsteht:
#wide1 %>% pivot_longer()wide1 %>%
pivot_longer(`price:2012-01-01`:`temp:2012-01-02`,
names_to = "calendar_date",values_to = "values")
6
Das Ergebnis Ihrer vorhergehenden Aufgabe ist im df “data1” hinterlegt. Spalten Sie dort die Variable “calendar_date” so auf, dass der folgende Output entsteht:
data1 %>%
separate(calendar_date, c("names", "calendar_date"), sep = ":")
7
Wandeln Sie die oben separierten Daten nun noch in geordnete long-Daten um, sodass jedes Merkmal/Variable in einer separaten Spalte hinterlegt ist (siehe folgender Output):
#data1 %>% separate(calendar_date, c("names", "calendar_date"), sep = ":") %>%data1 %>%
separate(calendar_date, c("names", "calendar_date"), sep = ":") %>%
pivot_wider(names_from = names, values_from = values)
Laden Sie nun das aktualisierte R-Skript herunter und speichern Sie es lokal in Ihrem Projektordner.
Was haben wir gelernt:
Wir erkennen, ob Daten im wide- oder long- Format vorliegen.
Wir können mit dem package tidyr einfache und komplexe Datentabellen zwischen wide- und long- Format umformen.
Wir können Spalten in Datentabellen umformen.
Hausaufgabe
Bearbeiten Sie die folgenden Aufgabenstellungen im Skript “04_Datawrangling_2”.
Die folgende Syntax erzeugt einen Beispieldatensatz im wide-Format.
Laden Sie dazu den Datensatz df_work als Data Frame.
hw <- df_work %>%
select(sell_id, calendar_date, price, quantity) %>%
filter(sell_id %in% c(1070, 2051) & calendar_date %in% as.Date(c("2012-01-01", "2013-01-01", "2014-01-01", "2015-01-01"))) %>%
pivot_wider(names_from = calendar_date, values_from = c("price", "quantity"))
hw
Bringen Sie die Daten ins long-Format, sodass es 6 variablen (sell_id, year, month, day, price, quantity) im Datensatz gibt.
Jede sell_id sollte jeweils einen Eintrag pro Jahr bei allen Variablen aufweisen, d.h. es sollte 8 Zeilen geben.