
Tools in DataScience 1 - Einführung
Hinweis:
- An jenen Stellen, die mit einem Graduation-Cap gekennzeichnet sind , erarbeiten Sie sich die Inhalte selbständig
- An Stellen mit einer Wandtafel erhalten Sie Input seitens der Dozierenden bzw. werden durch die Inhalte geführt
Worum geht es in dieser Sitzung:
Ziel der heutigen Sitzung ist es ein grundlegendes Verständnis der Programmiersprache R zu erlangen, sodass Sie R mittels Console oder RStudio bedienen können.
Sie werden lokal auf Ihrem Rechner ein R-Projekt anlegen, Code-Files benutzen und Daten einlesen.
Sie werden erfahren, wie Sie verschiedene Datenformate, wie csv, txt oder proprietäre Format (Excel), aber auch Daten aus anderen Statistikprogrammen wie bswp. SPSS als tibble (Data Frame - mehr dazu in sitzung II) in R importieren können.
Da R vielfältig einsetzbar ist, werden Sie auch lernen wie man R als Taschenrechner für verschiedene Rechenarten benutzt.
Abschliessend geht es darum, Vektoren zu erstellen, zu bearbeiten und Informationen aus den in ihnen gespeicherten Daten zu extrahieren.
Das Modul - Tools in DataScience
Beschreibung des Beispieldatensatzes
Datensatz zur Optimierung der Verkaufspreise im Einzelhandel
Wir arbeiten in den folgenden Sitzungen mit den Daten eines Cafés, welche zur Optimierung der Preisgestaltung über den Zeitraum von 2012-2015 gesammelt wurden. Sie könnten bspw. dazu genutzt werden, auf der Grundlage der vergangenen Verkäufe die Preiselastizität und die optimalen Preise für die Artikel zu ermitteln.
Der Datensatz bestzeht aus 3 Teildatensätzen:
a) CafeTransactionStore: Informationen über Preis, Absatzmenge und Produkt(kategorie) aller Transaktionen des Cafes. Als Transaktion gilt nicht der Verkauf eines Produktes an eine Person, sondern der Verkauf einer Produktart in bestimmter Menge an einem Tag.
b) CafeDateInfo: Informationen über den jeweiligen Transaktionstag des Cafes
c) CafeSellMeta: Informationen über die verkauften Produkte des Cafes
Insgesamt gibt es 13 unterschiedliche Variablen, die eine Mischung aus Faktoren und numerischen Datentypen sind.
Der Datensatz enthält keine fehlenden Werte.
Insgesamt gibt es 5404 Datenzeilen im Transaktionsdatensatz und 1349 Datenzeilen (eigentlich 1348 - darauf kommen wir in Sitzung III zu sprechen) im Datensatz zum Transaktionstag.
Der Unterschied in den Datenzeilen liegt darin begründet, dass an einigen Tagen mehrere Transaktionen hinterlegt sind.
Quiz zum Case der Sitzungen mit RStudio
Speichern Sie nun zuerst die Daten für den Kurs.
Erzeugen Sie einen leeren, neuen Ordner auf Ihrer Festplatte mit dem Namen Case - dieser Ordner Case kann sich in einem anderen Ordner, zum Beispiel Managerial_DataScience befinden.
Speichern Sie bitte die Daten im Ordner Case.
Bitte machen Sie einen Rechtsklick auf die Datei
Data_PriceOpt.7zund entpacken Sie die Daten in Ihrem Ordner wie folgt:
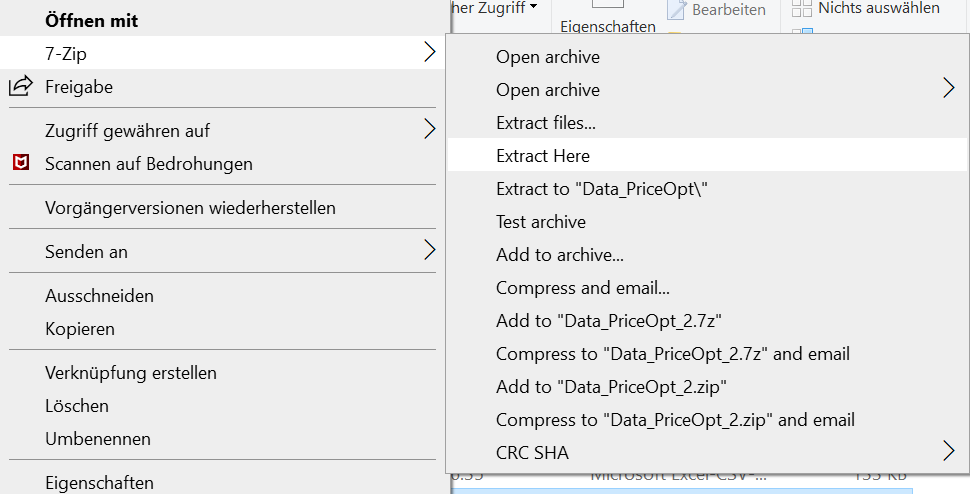
Download der Daten…
Bitte geben Sie die Daten nicht an Dritte weiter.
R und RStudio
Um mit den Daten zu arbeiten, brauchen wir eine geeignete Software. Wir arbeiten in den ersten Sitzungen mit RStudio, in späteren Sitzungen mit Excel. Wahrscheinlich müssen Sie nur RStudio auf Ihrem Rechner installieren, da Excel meist schon als Basissoftware auf PCs installiert ist bzw. die Verwendung von Office Paketen gängige Praxis ist.
R selbst bezeichnet den Namen der Programmiersprache, RStudio ist ein IDE (Integrated Development Environment) für R. IDEs wurden entwickelt um das Programmieren von Anwendungen oder Scripts zu vereinfachen. R wurde 1993 von Ross Ihaka und Robert Gentleman als Programmiersprache für Statistik an der Auckland Universität in Neuseeland entwickelt und gehört heute zum Standardrepertoire von Datenwissenschaft/-Analyse.
Installation von R, RStudio und zugehörigen Paketen
Hinweis: Die Screenshots sind gegebenenfalls nicht ganz aktuell. Installieren Sie jeweils die aktuellste verfügbare Version von R resp. R-Studio.
Wenn Sie R respektive RStudio zuerst noch installieren müssen, dann haben Sie wahrscheinlich auch noch keine Erfahrung mit der Software gesammelt. In diesem Fall sollten Sie erst das Basis-Tutorial leaRn absolvieren. Der VPN der FHNW muss zum Absolvieren des Tutorials eingestellt sein. Das Tutorial finden Sie hier: http://learn.fhnw.ch/english.html
Falls Sie R und RStudio schon installiert haben, brauchen Sie die folgenden Ausführungen nicht zu lesen, gehen aber bitte weiter bis zum Punkt “Installation von Paketen” und stellen sicher, dass in Ihrer Version von R resp. RStudio die dort aufgeführten Pakete installiert sind.
Installation von R
Gehen Sie zu folgendem URL: https://www.r-project.org/ Klicken Sie auf den Link «download R»:
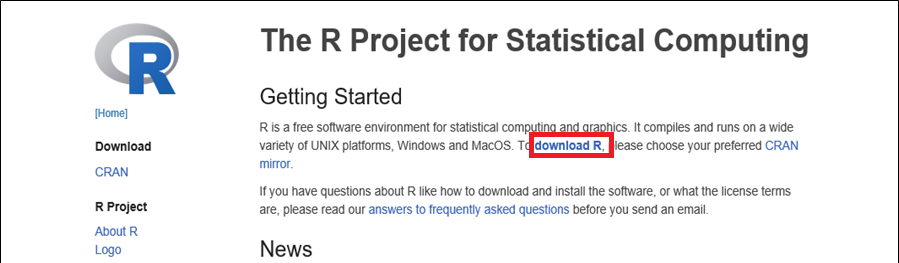
Wählen Sie als Installationsquelle «Switzerland» aus

Wählen Sie den Link zur Installation aus (Windows- oder Mac-Gerät):

Klicken Sie «install R for the first time» und folgen Sie den Anweisungen. Mac-User können direkt den Link «R-4.2.0.pkg» für die Installation anwählen.

Windows-User können direkt auf den Link «Download R 4.2.0. for Windows» gehen und die Installationsdateien runterladen.

Nachdem die Installationsdatei gespeichert wurde, führen Sie die relevante .exe Datei aus und installieren R. Allenfalls ist danach ein Neustart des Computers nötig.
Ist R korrekt installiert, so können Sie es über das Start-Menü links unten anwählen und starten (allenfalls müssen Sie nach unten scrollen, bis die installierten Programmen aufgeführt sind, welche unter ‘R’ gelistet sind).
Wenn Sie das Programm nun starten, sollten Sie folgenden Screen sehen:
Tippen Sie folgende Rechnung in die Konsole: 3+4
und bestätigen Sie mit der ENTER-Taste
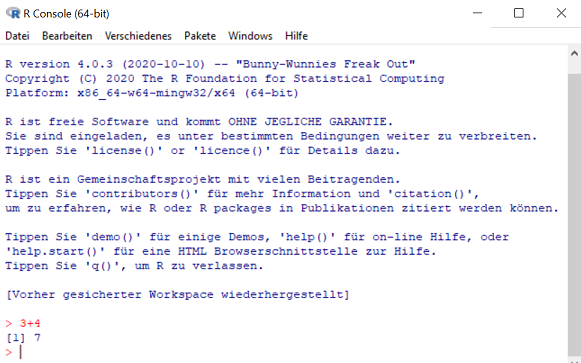
Nun sind wir soweit, dass RStudio installiert werden kann.
Installation von RStudio
R-Studio ist eine integrierte Entwicklungsumgebung und grafische Benutzeroberfläche für die Statistik-Programmiersprache R.
RStudio ermöglicht u.a. eine Autovervollständigung, automatische Einrückungen, Syntaxhervorhebung, integrierte Hilfe und Informationen zu Objekten in der Arbeitsumgebung. Es gibt die Möglichkeit Datensätze zu inspizieren und zu bearbeiten.
Gehen Sie zur URL: http://www.rstudio.org/ Klicken Sie im Browser rechts oben auf «Download»
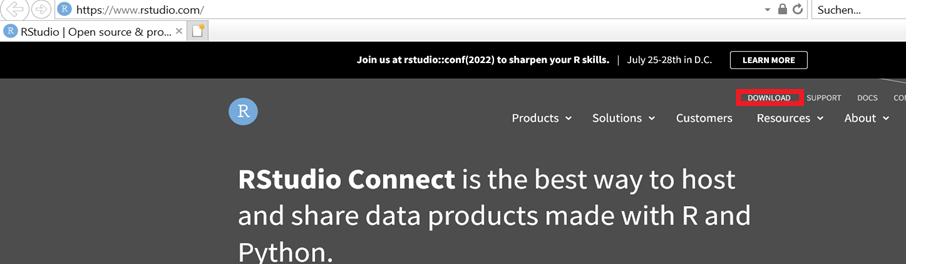
Scrollen Sie nach unten zu «All Installers» und wählen Sie die für Gerät und Betriebssystem passende Datei aus:
Speichern Sie die Installationsdatei und führen Sie diese anschliessend mit einem Doppelklick aus. Allenfalls ist danach ein Neustart nötig. Suchen Sie danach das RStudio Icon: 
Bei Windows-Usern findet es sich in der Taskleiste und startet durch Anklicken. Gehen Sie dann auf: View -> Panes ->Show all Panes. RStudio ist nun fertig eingerichtet:
Nach erfolgreicher Installation können Sie nun RStudio, gleich wie vorhin R, über die Taskleiste oder das Startmenü anwählen und mit Mausklick starten.
Installation von Paketen (packages)
In RStudio arbeiten Sie häufig mit Befehlen, die in bestimmten Paketen (´packages´) hinterlegt sind. Öffnen Sie RStudio und installieren Sie die Package-Sammlung “tidyverse”:
Dazu schreiben Sie im linken oberen Fenster - dem Editor - folgenden Befehl:
install.packages('tidyverse')
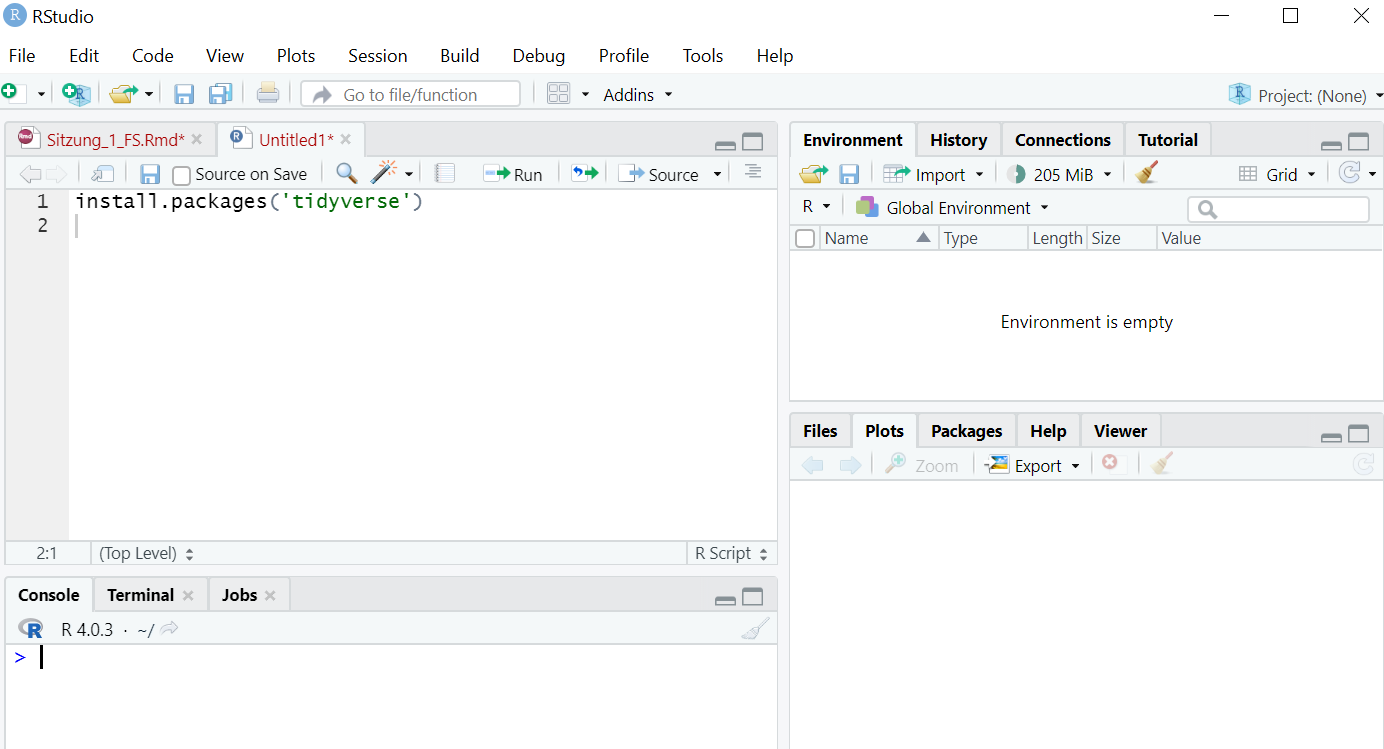
Das Paket benötigt andere Pakete etc., die ebenfalls installiert werden. Je nach Internetverbindung dauert die Installation circa 5-10 Minuten.
Arbeiten mit RStudio
Überblick RStudio
In R - Studio gibt es vier verschiedene Anzeigefenster.
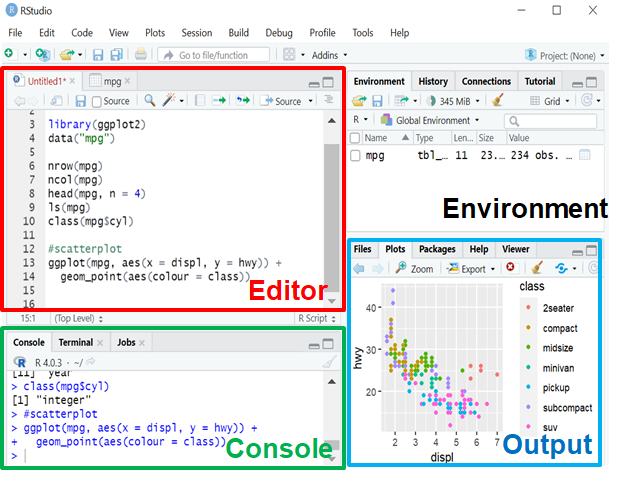
Im Editor (links oben) können Sie Befehle eingeben. Speichern Sie diese regelmässig als
Skript, sodass Sie Ihren Arbeitsablauf nicht ständig wiederholen müssen. Mit der Tastenkombination Cmd/Ctrl + Enter oder bei Anklicken von Run können Sie Code ausführen.Die Objekte der aktuellen R-Arbeitsumgebung - dem Workspace - (Vektoren, Matrizen, DataFrames, …), sehen Sie im Environment (rechts oben).
Die Console (links unten) ist der Ort, an dem R darauf wartet, dass Sie ihm sagen, was es tun soll, und wo es die Ergebnisse eines Befehls anzeigt.
Prinzipiell können Sie R auch mit der Console R bedienen. Ein Skript (geschrieben im Editor) ist aber vorteilhafter.Im Fenster Output (rechts unten) werden Ihnen u.a. die erstellten Diagramme angezeigt.
Ein zentraler Punkt ist die Verwaltung von Dateien, wenn Sie mit R arbeiten. Hierfür eröffnen wir ein Projekt. Dafür erhalten Sie Input von den Dozierenden.
R Projekt
Vorteile:
- Das Arbeitsverzeichnis Working Directory ist automatisch auf den Projektordner festgelegt.
- Alle Dokumente (Skripte, Daten, Resultate …) liegen an einem Ort.
Vorgehen bei Projekteröffnung
- Erstellen Sie nun lokal auf Ihrem Rechner einen Projektordner. Wählen Sie dazu am besten den Ordner, in dem Sie die heruntergeladenen Daten für den Kurs zu Kursbeginn gespeichert haben.
- Eröffnen Sie nun in RStudio ein neues Projekt unter “File/New Project…”
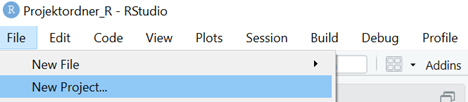
- Wählen Sie “Existing Directory”
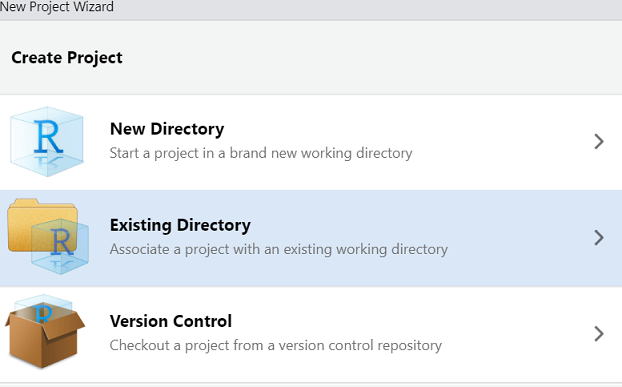
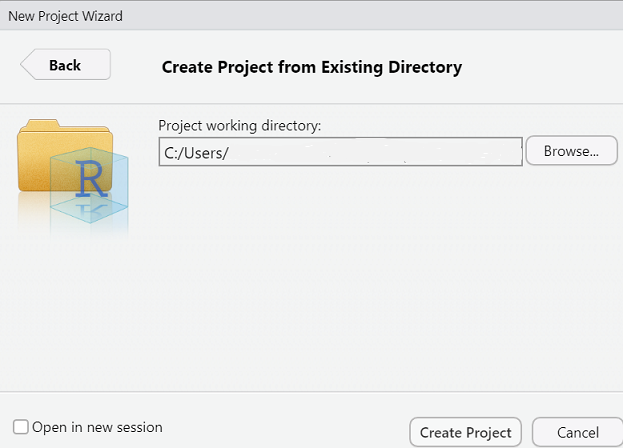
- Navigieren Sie zum bei 1. erstellten Ordner und drücken Sie «Create Project»
R-Skript
Öffnen Sie RStudio.
Klicken Sie anschliessend auf File -> New File -> R Script
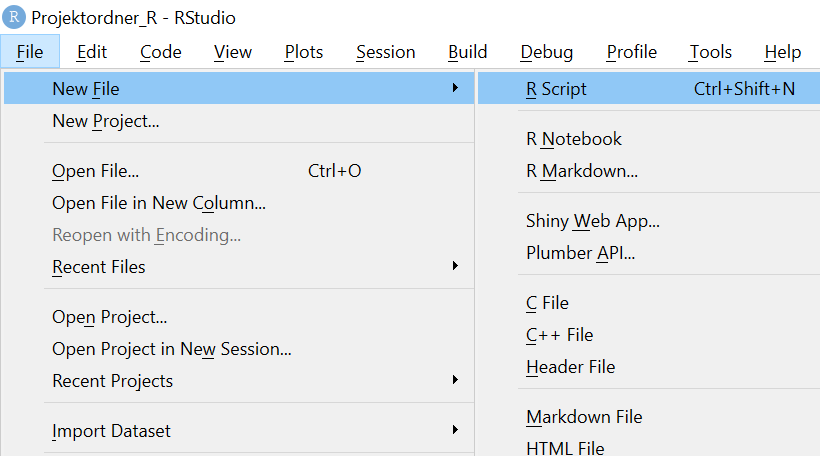
Dabei öffnet sich ein Fenster oben «Untitled1». Dies ist ein noch unbenanntes R-Script. Mit einem R-Script können Sie Ihre Befehle abspeichern und jederzeit wieder ausführen.
Wenn Sie im R-Script einen «Hashtag» (#) an den Anfang einer Zeile stellen, so wird R diese Zeile als Kommentar erkennen und nicht ausführen. Das ist für Sie selbst nützlich, damit Sie Notizen anlegen können. Schreiben Sie nun in eine Zeile des neu geöffneten Skriptes:
# Mein erstes R - Skript
Danach: 1+2
Führen Sie beide Zeilen aus.
Festlegen des Arbeitsverzeichnisses (working directory)
Gehen Sie nun auf File -> Save as und speichern Sie das R-Skript im Projektordner, also dort wo Sie auch Ihre anderen Dateien für diese Vorlesung gespeichert haben (Daten usw.). Nennen Sie das File Intro_to_R.
Nachdem das Skript gespeichert wurde, sollten Sie noch das Arbeitsverzeichnis (working directory) festlegen. wenn Sie in Ihrem R-Projekt arbeiten, ist das Arbeitsverzeichnis der R-Projektordner. Andernfalls ist die Festlegung des working directory notwendig, damit R weiss, in welchem Ordner nach den Dateien zu suchen ist, falls diese aufgerufen werden. Generell kann man das Arbeitsverzeichnis wie folgt festlegen: Session -> Set Working Directory -> To Source File Location. Danach erscheint in der Konsole ein Befehl, dass das Arbeitsverzeichnis (Working Directory) gesetzt wurde, bspw.:
setwd("C:/Users/Desktop/Unterricht_DataScience/Projektordner_R")
Eine verallgemeinerte Option zum Festlegen des Arbeitsverzeichnisses auf den Ordner, in dem Sie ihr R-Skript gespeichert haben ist die Folgende. Dabei sparen Sie sich die händische Eingabe des Verzeichnisbaums:
setwd(dirname(rstudioapi::getActiveDocumentContext()$path))
Hinweis zum Dateipfad und Betriebssystem:
Wenn Sie unter Windows arbeiten, müssen Sie im Dateipfad entweder Schrägstriche / oder doppelte Backslashes \ verwenden.
Bei Mac-Benutzern sieht der Dateipfad möglicherweise eher so aus: setwd(“~/Unterricht_DataScience/Projektordner_R”).
Markieren Sie nun in der Konsole diese Zeile (Bei Ihnen heisst das Verzeichnis sicherlich etwas anders) und kopieren Sie diese in eine neue Zeile im R-Script. Das führt dazu, dass bei erneutem Laden des Skriptes das Arbeitsverzeichnis automatisch korrekt gesetzt wird. Speichern Sie anschliessend das Skript mithilfe des Befehls CTRL+S (während Sie ein Skript erstellen, sollten Sie sehr regelmässig speichern).
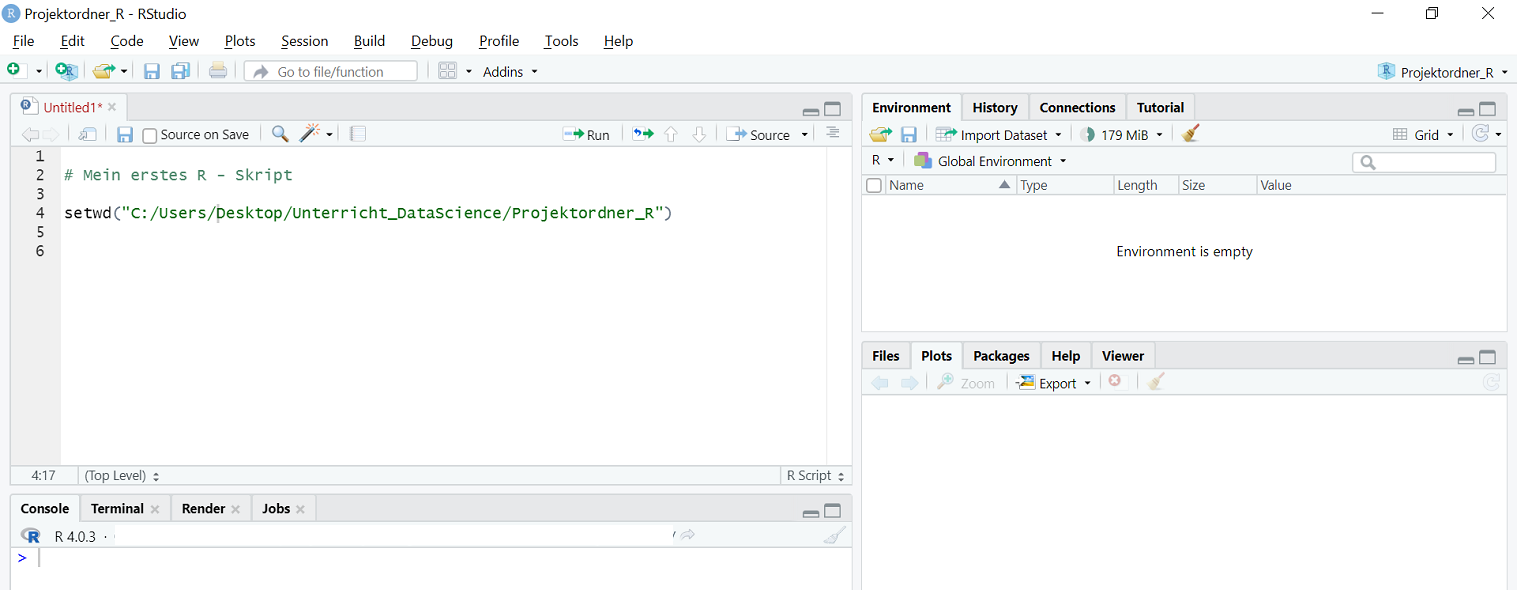
Sie können nun zur Überprüfung das Skript ausführen. Markieren Sie hierfür die erstellten Zeilen (mit der Maus oder über CTRL+A) und klicken Sie anschliessend oben rechts im Skript auf Run. In der Konsole erscheint dann das nochmalige Setzen des Working Directories (ohne Fehlermeldung).
Mit dem Befehl getwd() können Sie prüfen, welches Verzeichnis gerade als Arbeitsverzeichnis verwendet wird.
Mit dem Befehl dir() können Sie alle Dateien und Verzeichnisse im aktuellen Arbeitsverzeichnis auflisten.
Das Ergebnis wird Ihnen wieder in der Console (links unten) dargestellt.
Tipps für die Bedienung von R
Im Editor (links oben) können Sie Ihre Befehle eingeben. Sie können sie ausführen indem Sie entweder den Cursor auf die eingegebene Befehlszeile bewegen und ctrl und ENTER drücken oder Sie klicken auf Run.
Hintergrundinformationen über Befehle erhalten Sie im Output-Fenster (rechts unten), wenn Sie vor den Befehl ein Fragezeichen schreiben und dann die Befehlszeile ausführen.
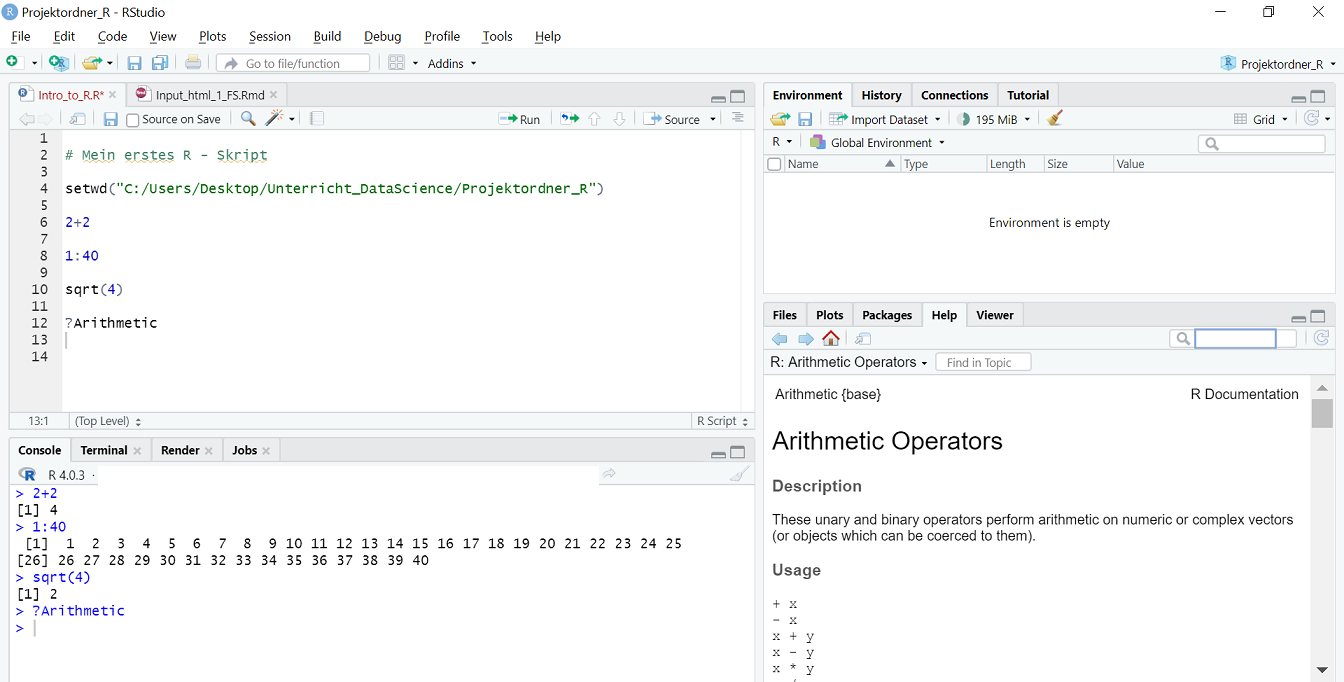
Sollte es zu einer Fehleingabe wie 2 + kommen, bei der bspw. der zweite Summand vergessen wurde, erhalten Sie eine Ausgabe in der Console die mit +endet. Damit sagt Ihnen R, dass die Ausführung nicht beendet wurde.
Entweder kann man den Befehl korrigieren und erneut ausführen oder während der Ausführung stoppen indem man das Consolefenster anklickt und ESC drückt.
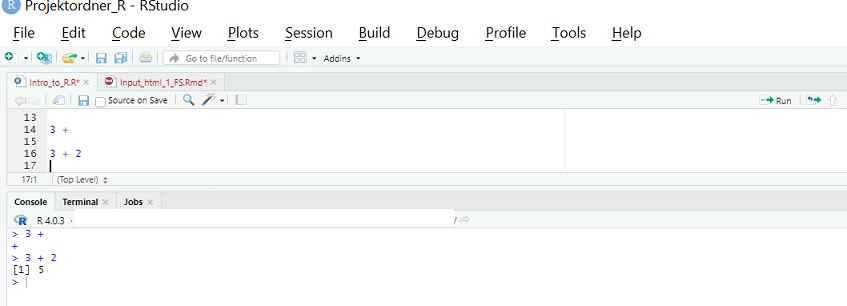
Abschliessend kann man im Consolefenster auch mittels Pfeiltasten ↑ zu vorangegangen oder ↓ nachfolgenden Befehlszeilen wechseln.
Wichtigte Shortcuts (Tastenkombinationen) für zeitsparendes Arbeiten mit R:
Aktion Zeichen Eingabe per Tastatur
Setzen des Pipe Operators: %>% crtl shift m
Hinweis: Der Pipe Operator kann aktuell auch in der Form |> verwendet werden.
Das Aus/Entkommentieren von Befehlszeilen: # crtl shift c
Der Zuweisungoperator: <- alt + - (nur in Skripten)
Alle Shortcuts und Bedienungshilfen in R: alt shift k Quiz zu Projekten und Skripten in RStudio
Importieren von Daten
Datensätze werden häufig als Kalkulationstabelle (mit Zeilen und Spalten) gespeichert. Einige können als Rohtextdatei im Texteditor eingelesen werden.
Andere - proprietäre - Dateien (wie bspw. Microsoft Excel) nicht.
In Rohtextdateien werden Zeilen oft durch Zeilenumbrüche und Spalten durch ein Begrenzungszeichen getrennt. Die dort gebräuchlichsten Begrenzungszeichen sind Komma, Semikolon, Leerzeichen und Tabulator.
Man verwendet die readr Funktionen in R für den Import von Rohtextdateien, die readxl Funktionen für den Import von Exceldateien, die read - Funktionen des "haven" - Paketes für den Import von Datensätzen anderer Statistikprogramme wie SPSS, Stata oder SAS und load zum laden von in R gespeicherten Daten bzw. Objekten. Die Funktionen können mit library(readr), library(readxl) usw. in R geladen werden.
Weitere Informationen zu den hier verwendeten packages finden Sie unter:
https://www.tidyverse.org/packages/#import
Dort können Sie auch das entsprechende cheatsheet herunterladen:
https://raw.githubusercontent.com/rstudio/cheatsheets/main/data-import.pdf
Sollen die importierten Daten automatisch als tibble (ähnlich einer Datentabelle) in R gespeichert werden, weisst man einen Namen zu. Der Unterschied zwischen dataframe und tibble wird näher beschrieben unter: https://posit.co/blog/tibble-1-0-0/
Beispiel:
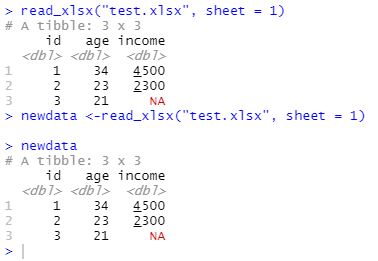
new_data <- read_...
In den folgenden Abschnitten wird gezeigt, wie der Teil "read_..." zu ergänzen ist.Durch die Eingabe des jeweiligen read-Befehls oder durch Eingabe und Bestätigung des neu zugewiesenen Namens erhält man in der Console einen ersten Überblick über Spalten (Variablenanzahl) und Zeilenanzahl (Anzahl der Einträge bzw. Fälle).
readr - Funktionen zum Datenimport in R
readr ist die tidyverse-Bibliothek, die Funktionen zum Lesen von tabellarischen oder in Textdateien gespeicherten Daten in R enthält.
In Abhängigkeit vom Trennzeichen, wird eine der folgenden readr - Funktionen für den Datenimport verwendet: Sofern nicht anders beschrieben, wir in den folgenden Beispielen angenommen, dass sich in Ihrem Projektordner ein Unterverzeichnis “www” befindet, welches jeweils die zu ladenden Dateien enthält. Sind die Daten in einem anderen Ordner, müssen Sie dessen Pfad eingeben. Achtung: in Windows sind Ordnernamen durch “" voneinander getrennt. In R werden die Verzeichnisnamen nur gelesen, wenn Sie durch den”/" ersetzt werden.
1. read_delim (für jede Art von Begrenzungszeichen):
Beispiel: dat<-read_delim("www/data1.txt", delim = ",")
Bei delim handelt es sich oft um txt - Dateien, die tabstopp, d.h. delim = "\t"
oder ein Komma, d.h. delim = "," als Trennzeichen verwenden.
2. read_csv (für Komma separierte Werte):
Beispiel: dat<-read_csv("www/data1.csv")
3. read_csv2 (für Semikolon separierte Werte):
Beispiel: dat<-read_csv2("www/data1_semi.csv")
4. read_tsv (für Tabulator separierte Werte):
Beispiel: dat<-read_tsv("www/data1.tsv")
Zusatz:
read.table zum Einlesen verschiedener Datentypen als “Data Frame”.
Mehr dazu zu Beginn der nächsten Sitzung.
Beispiel: dat <- read.table("www/datei.csv", header = TRUE, sep = ",", stringsAsFactors = TRUE, col.names = c("Alter", "Einkommen"))
Übung: Datenimport
1. Sie möchten die Datei übung.txt in R importieren und haben dazu ein Projekt unter C:\Users\Desktop\Projekt eröffnet.
Die tabstopp-separierten Daten sind im Ordner C:\Users\Desktop\DS gespeichert.
2. Speichern Sie den Datensatz delimdata.txt in Ihrem lokalen Projektordner.
Beim öffnen der Daten mit dem Editor sehen Sie, dass als Trennzeichen das Komma verwendet wurde. Importieren und speichern Sie die Daten nun lokal auf Ihrem Rechner mittels read_delim Funktion in R in einen tibble mit dem Namen dat.
Denken Sie daran, dass Sie gegebenenfalls erst die library(readr) laden müssen um die read_delim Funktion verwenden zu können. Sofern notwendig, finden Sie den Lösungshinweis in folgendem Eingabefenster.
#library(readr)
#dat<-read_delim("delimdata.txt", delim = ",")
#datBeantworten Sie anschliessend folgende Frage.
readxl - Funktionen zum Datenimport in R
readxl ist Teil der tidyverse-Bibliothek, die Funktionen zum Lesen von in Tabellen- bzw. Arbeitsblättern gespeicherten Daten in R enthält.
Um es benutzen zu können, wird auf die entsprechende Bibliothek zugegriffen, indem man im Skript library(readxl) eingibt und bestätigt.
Import von Microsoft Excel-formatierten Dateien
Die Funktion excel_sheets(“excel_file.xlsx”) zeigt die Namen der Blätter in der Excel-Datei an. Der oder die Namen werden anschliessend an das Blatt-Argument für eine der folgenden readxl-Funktionen übergeben:
5. read_excel()
6. read_xls()
7. read_xlsx()
Beispiel:
Befehl: excel_sheets("www/Data1.xlsx")
Output: [1] "Tabelle1" "Tabelle2"Nun kann, bspw. mit read_excel, das entsprechende Tabellenblatt aus der Datei eingelesen werden:
Beispiel:
dat<-read_excel("www/Data1.xlsx", sheet = "Tabelle1")
ODER
dat<-read_excel("www/Data1.xlsx", sheet = 1)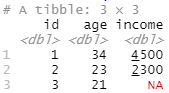
Es können auch mehrere Tabellenblätter in ein Dokument in R eingelesen werden:
Beispiel:
dat<-read_excel("www/Data1.xlsx")
pfad <- "C:/Users/Desktop/Unterricht_DataScience/Projektordner_R/Data1.xlsx"
data_new <- pfad %>%
excel_sheets() %>%
# set_names() %>%
map_dfr(read_excel, path = pfad)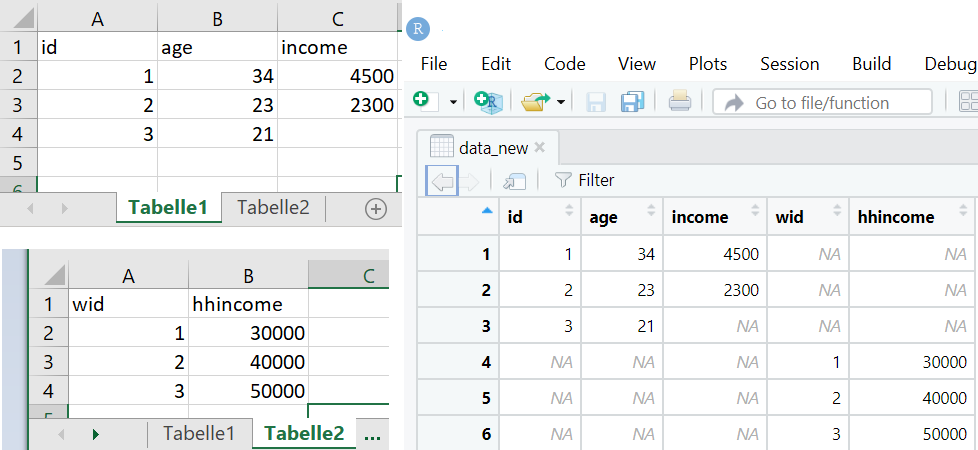
Übung: Datenimport
1. Sie möchten die Datei uebung.xlsx in R importieren und unter dem Namem lohndaten speichern.
Sie wollen ausschliesslich die Informationen aus dem 2. Tabellenblatt importieren, welches die Lohndaten enthält.
2. Speichern Sie den Datensatz mietspiegel.xlsx in Ihrem lokalen Projektordner.
Er enthält einen Auszug aus den deutschen Mietspiegeldaten.
Importieren Sie die Daten in R und inspizieren Sie sie mithilfe der read_xlsx Funktion.
Denken Sie daran, dass Sie erst die library(readxl) laden müssen um die read_xlsx Funktion verwenden zu können.
Sofern notwendig, finden Sie den Lösungshinweis in folgendem Eingabefenster. Beantworten Sie anschliessend die Quizfrage.
#library(readxl)
#read_xlsx("mietspiegel.xlsx", sheet = 1)
#read_xlsx("mietspiegel.xlsx", sheet = 2)
Einige nützliche Argumente der read Funktion (nicht alle sind auf Exceldateien anwendbar)
- Importieren von Daten, wobei Dezimaltrennzeichen von anderen Trennzeichen unterschieden werden:
Beispieldaten: 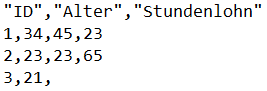
Beispiel: dat<-read_delim("data111.txt", delim = ",", locale = locale(decimal_mark=","))
Wir definieren das Komma als Dezimaltrennzeichen und unterscheiden es damit von
anderen Trennzeichen (bspw. dem Semikolon oder anderen Kommas), die die Spalten voneinander trennen.
ohne Beachtung der Trennung von Zeilen und Zeichen: 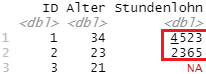
mit Beachtung der Trennung von Zeilen und Zeichen: 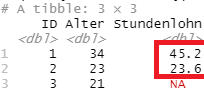
- Einlesen und Benennung der Kopfzeile:
Vor dem Datenimport sollte man prüfen, ob es eine Kopfzeile mit Spaltennamen gibt.
Optionen zur Kopfzeile:
- Inspizieren der Kopfzeile:
Beispiel:
dat<-read_excel("www/Data1.xlsx", n_max = 3)
dat<-read_csv("www/Data1.csv", n_max = 3)
Es werden hier jeweils die Kopfzeile und die ersten 3 Zeilen angezeigt.
- Kopfzeile soll als solche erkannt und eingelesen werden:
Beispiel: Befehl weglassen oder col_names = TRUE
- Kopfzeile existiert nicht bzw. soll nicht als solche eingelesen werden:
Beispiel mit read_csv: dat<-read_csv("www/data1.csv", col_names = FALSE)
Beispiel mit read_excel: dat<-read_excel("www/data1.xlsx", sheet = "Tabelle1", col_names = FALSE)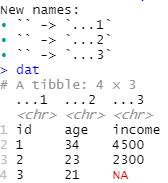
- Eigene Benennung der Kopfzeile:
Beispiel: dat<-read_excel("www/data11.xlsx", sheet = "Tabelle1", col_names = c("ID","Alter","Einkommen"))
- Eigene Benennung: Ersetzen bereits bestehender Kopfzeile
(col_names fügt neue erste Zeile hinzu, wobei alte Kopfzeile in Tabelle rutscht. Diese mit "skip" auslassen)
Bild oben: dat<-read_excel("www/Data1.xlsx", sheet = "Tabelle1")
Bild mittig: dat<-read_excel("www/Data1.xlsx", sheet = "Tabelle1", col_names = c("ID","Alter","Einkommen"))
Bild unten: dat<-read_excel("www/Data1.xlsx", sheet = "Tabelle1", col_names = c("ID","Alter","Einkommen"), skip = 1)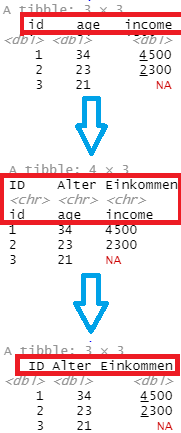
- Importieren mehrerer Dateien (mit allenfalls gleichen Spaltenbezeichnungen) in eine Zieldatei:
Beispiel: dat<-read_csv(c("www/data1.csv", "www/data2.csv"), id = "origin")
Wir erzeugen eine neue Spalte "origin", die den Namen der Ursprungsdatei pro Zeile enthält.
- Auslassen von Zeilen beim Import:
Beispiel: dat<-read_excel("www/data12.xlsx")
Beispiel: dat<-read_excel("www/data12.xlsx", skip = 1)
Zeile 1 wird nicht importiert, da sie bspw. fehlerhafte Angaben enthält.
- Importieren von subsets von Zeilen:
Bild oben: dat<-read_excel("www/data12.xlsx")
Bild unten: dat<-read_excel("www/data12.xlsx", n_max = 2)
Im 2ten Bild (unten) importieren wir bis zur Zeile 2.
- Importieren von Daten, wobei Werte als Fehlwerte definiert werden:
Bild oben: dat<-read_csv("www/data12.csv")
Bild unten: dat<-read_excel("www/data12.xlsx", na = c("6", "9999"))
Wir definieren die Werte 6 und 9999 als Fehlwerte.
Fehlwerte werden üblicherweise als "NA" dargestellt.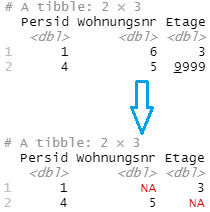
Übung: Datenimport
Sie wollen die Daten aus dem Mietspiegel.xlsx in einen tibble “newdata” importieren.
Wählen Sie nur die Daten aus Tabellenblatt 2 aus. Ersetzen Sie bei der Variable bjahr den Wert 1939 durch einen Fehlwert (NA).
Sofern notwendig, finden Sie den Lösungshinweis in folgendem Eingabefenster.
# library(readxl)
# newdata<-read_xlsx("mietspiegel.xlsx", sheet = 2, na = "1939", n_max = 5)Wählen Sie nur die ersten 5 Zeilen zur Anzeige aus. Führen Sie “newdata” aus und beantworten Sie anschliessend die Quizfrage.
Weitere Funktionen zum Datenimport in R
8. read_sav ist auch Teil der tidyverse-Bibliothek. Man kann damit Daten aus dem Statistikprogramm SPSS, die als sav - Dateien abgespeichert wurden, importieren. Dazu muss man die Bibliothek haven laden, die auch in tidyverse enthalten ist.
Beispiel:
library(haven)
Erkennen und Auslesen der Kopfzeile als solcher und der ersten 3 Zeilen:
read_sav("C:/Users/..../data1.sav", n_max=3)
Importieren und speichern der Daten als tibble:
Daten_SPSS <- read_sav("C:/Users/..../data1.sav")9. load ist Teil der R Basisfunktionen. Man kann damit in R gespeicherte Daten bzw. Objekte, die als rdata - Dateien abgespeichert wurden, importieren.
Beispiel:
load("C:/Users/..../Data1.rdata")Download des R-Skriptes zum Datenimport
Um nun mit der Arbeit an den eingangs heruntergeladenen Daten beginnen zu können, müssen wir sie in RStudio importieren.
Wir gehen so vor, dass Sie die Skripte zum Bearbeiten der jeweiligen Sitzung selbständig entwickeln. Sie werden hierbei Schritt für Schritt angeleitet. Die ersten Schritte und das erste Ausprobieren findet immer interaktiv statt - Ziel ist aber, dass Sie am Ende R-Skripte bei sich lokal ausführen können.
Laden Sie nun den Datensatz “CafeTransactionStore”.
Die Daten sind Kommasepariert und wurden mit read_csv() Befehl in einem tibble “cts” importiert.
Mit dem Befehl colnames() kann man die Kopfzeile inspizieren, mit ncol() die Anzahl der Variablen bzw. Spalten im tibble.
Den Variablentyp erhält man mit spec() und die Zeilenanzahl mit nrow().
Lassen Sie sich Spaltenanzahl und Spaltennamen, Variablentypen und abschliessend die Zeilanzahl von “cts” anzeigen.
# library(tidyverse)
# library(readxl)
# read file in CSV format
# cts<-read_csv("CafeTransactionStore.csv", col_names = TRUE)#Spaltenanzahl und Namen
ncol(cts)
colnames(cts)
#Variablentypen
spec(cts)
#Zeilenanzahl
nrow(cts)
Speichern Sie nun das ‘Skript’ für das Einlesen der Daten, und zwar direkt in Ihrem Projekt-Ordner.
Wir werden den Code im Skript laufend erneuern.
Einführung/Wiederholung von Basisbefehlen in R: “Taschenrechner & Variablen”
(Zeit: ca. 30 min)
Bevor wir nun mit den importierten Daten arbeiten, erhalten Sie Zeit um sich mit R vertraut zu machen. Wenn Sie bereits mit R gearbeitet haben, können Sie die Zeit nutzen um Ihr Wissen aufzufrischen.
Nutzen Sie dazu das Tutorial learn, welches aus einem Lehrfondsprojekt entstanden ist. Es ermöglicht den Studierenden der Studiengänge Betriebsökonomie und International Management die ersten Schritte in R kennenzulernen. Der VPN der FHNW muss zum Absolvieren des Tutorials eingestellt sein. Das Tutorial auf Englisch finden Sie hier: http://learn.fhnw.ch/english.html
Hinweise zum Vorgehen:
Bitte studieren Sie nun zuerst die Teile Overview bis inklusive working with variables aus dem learn Tutorial Unit 1.3 The basics und lösen Sie im Anschluss die hier hinterlegten Übungsaufgaben.
Bei Fragen erhalten Sie Unterstützung von den Dozierenden.
Übungen: R als Taschenrechner und Variablen
R als Taschenrechner: Berechnen Sie die Lösungen der folgenden Aufgaben:
1. Berechnen Sie: 2 mal 34 plus 7 mal 9.
2*34+7*9
2. Berechnen Sie: 2 plus 34 mal 9. Die Addition soll zuerst ausgeführt werden.
(2+34)*9
3. Ziehen Sie die Quadratwurzel aus 324.
sqrt(324)
4. Potenzieren Sie die Zahl 7 (Basis) mit dem Exponenten 4.
7^4
5. Logarithmieren Sie die Zahl 100000 zur Basis 10.
log10(100000)
6. Logarithmieren Sie die Zahl 1 zur Basis = e (e = 2.718282)
log(1)
Arbeiten mit Variablen: Lösen Sie die folgenden Aufgaben:
7. Erstellen Sie die Variable x und weisen sie ihr den Wert 10 zu. Inspizieren Sie den eingegebenen Wert der Variablen x in der Ausgabe der Console.
Ändern Sie den Wert von 10 auf 4 und prüfen Sie erneut, ob die Wertänderung funktioniert hat.
x<-10
x
x<-4
x
8. Leeren Sie den Arbeitsspeicher mit “rm(list = ls())”. Erstellen Sie die Variablen x und y. Weisen Sie x den Wert 20 und y den Wert 10 zu.
Inspizieren Sie die Variablen x und y.
Prüfen Sie, ob die Variablen im Arbeitsspeicher von R hinterlegt sind.
Entfernen (löschen) Sie die Variable x wieder.
Prüfen Sie, welche Variable im Arbeitsspeicher von R noch enthalten sind.
rm(list = ls())
x<-20
y<-10
x
y
ls()
rm(x)
ls()
9. Erstellen Sie die Variablen x und y. Weisen Sie x den Wert 20 und y den Wert 10 zu.
Dividieren Sie die Variable x durch die Variable y und ziehen Sie anschliessend den Wert 2 ab.
x<-20
y<-10
x/y-2Bei Bedarf: Klärung offener Fragen
Einführung/Wiederholung von Basisbefehlen in R: “Vektoren” I
Hinweise zum Vorgehen:
(Zeit: ca. 25 min)
Studieren Sie zuerst den Teil zu Datenvektoren bei learn (Unit 1.3 The basics - Data vectors). Das Tutorial auf Englisch finden Sie hier: http://learn.fhnw.ch/english.html
Danach erfolgt ein weiterer Input seitens der Dozierenden und abschliessend Übungsaufgaben zu diesem Thema.
Einführung/Wiederholung von Basisbefehlen in R: “Vektoren” II
Sortieren von Vektoren
Man unterscheidet in R beim sortieren danach, ob man Vektoren oder ganze Datentabellen sortieren will. Letzteres besprechen wir in einer späteren Sitzung, wenn es um Datentabellen bzw. Data Frames geht. Für Vektoren nutzt man folgende Funktion(en).
sort() - sortieren von Vektoren
Mit der Funktion sort() können Sie Vektoren der Groesse ihrer Werte nach sortieren. Die Grundeinstellung ist “aufsteigend”. Will man absteigend sortieren, bedarf es dem Zusatz
decreasing = TRUE.Beispiel:
x <- c(8, 5, 23) x x ist unsortiert:## [1] 8 5 23sort(x, decreasing = TRUE) x ist absteigend sortiert:## [1] 23 8 5
Weitere Funktionen, die beim Sortieren von Vektoren nützlich sind
order() - Zugriff auf die Ordnungsnummern bzw. -Indices von Vektoren
Mit der Funktion order() können Sie auf die Ordnungsnummern - bzw. Indizes von Vektoren zugreifen. Die Funktion nimmt einen Vektor und gibt die Indizes zurück, die sich bei Sortierung des Vektors ergeben würden.
Im untenstehenden Beispiel sehen Sie die Zahlen 8, 5 und 23. Die 8 hat den Index = 1, die 5 den Index = 2 und die 3 den Index = 3. In geordneter aufsteigender Reihenfolge würde 5, 8, 23 stehen, d.h. der der geordnete Index würde nun lauten: 2 (Zahl 5 stand in Originalvektor an 2ter Stelle), 1, 3.
Wie schon bei dersort()Funktion kann man auch beiorder()mit dem Zusatzdecreasing = TRUEdie Reihenfolge der Ordnung umkehren.Beispiel:
x <- c(8, 5, 23) x x ist ungeordnet:## [1] 8 5 23order(x) Zeigt die Ordnungsnummern, die bei aufsteigendem Sortieren von x resultieren (5, 8, 23). 5 stand ursprüglich an 2ter Stelle (Ordnungsnummer = 2) und würde geordnet an 1ter Stelle stehen.## [1] 2 1 3order(x, decreasing = TRUE)## [1] 3 1 2Anwendung über Indexvariable
index <- order(x) # gibt Position der Elemente von x wieder, wenn x (aufsteigend) sortiert wäre index## [1] 2 1 3a<-x[index] # Umordnung der Elemente von x nach diesem Index und speichern in neuem Vektor a## [1] 5 8 23order(a)## [1] 1 2 3
rank() - Zugriff auf die Ränge der Ausprägungen von Vektoren
Mit der Funktion rank() können Sie auf die Ränge von Vektoren zugreifen. Wie Sie sicher bereits aus Statistikkursen wissen, kann es bei der Rangvergabe zur mehrfachen Vergabe desselben Ranges an mehrere “gleich” gerankte Objekte bzw. Einträge kommen. Als Grundeinstellung wird der mittlere Rang vergeben.
Beispiel:
x <- c(8, 5, 23) x## [1] 8 5 23Die Zahlen in aufsteigender Rangordnung: 5, 8 ,23 ; d.h. "5" bekommt Rang 1, "8" Rang 2 und "23" Rang 3. rank(x)## [1] 2 1 3bei gleichen Rängen wird (als Grundeinstellung) der mittlere Rang vergeben.
x <- c(8, 5, 5) x## [1] 8 5 5rank(x)## [1] 3.0 1.5 1.5
max(), which.max(), min(), which.min() - Zugriff auf die grösste Ausprägung und deren Index. Äquivalent dazu min(), which.min()
Mit den Funktion max() bzw. min() können Sie auf das Maximum bzw. Minimum und mit which.max() und which.min() auf die jeweiligen Ordnungs- bzw. Indexpositionen von Vektoren zugreifen.
Beispiel:
x <- c(8, 5, 23) x## [1] 8 5 23max(x) which.max(x)## [1] 23## [1] 3
Übungen: Vektoren in R
Arbeiten mit Vektoren: Lösen Sie die folgenden Aufgaben:
1. Erstellen Sie einen Vektor x. Weisen Sie ihm die Werte 1 bis 5 zu.
Inspizieren Sie die Werte der Variable x.
Prüfen Sie den Datentyp.
Welchen Mittelwert hat der Vektor x?
# (x ist vom type "double"):
x<-c(1,2,3,4,5)
x
typeof(x)
mean(x)
2. Erstellen Sie einen Vektor y, der die Werte: 1 - 4 enthält.
Erstellen Sie einen Vektor x. Er enthält die Werte von Y geteilt durch die Länge von y.
Welche Summe ergibt sich aus x?
y<-c(1,2,3,4)
x<-y/length(y)
sum(x)
3. Erstellen Sie einen Vektor x, der die Zahlen 1 bis 161 enthält.
Welcher Werte ergibt sich, wenn man die Quadratwurzel aus dem Mittelwert des Vektors berechnet?
Beantworten Sie die Frage mit den Befehlen “sqrt()” und “mean()”.
x<-1:161
mean(x)
sqrt(mean(x))
4. Erstellen Sie einen Vektor x, der alle ungeraden Zahlen im Bereich von 1 bis 200 enthält.
Welche Summe ergibt sich? Beantworten Sie die Frage mit dem Befehl “sum()”.
x<-seq(from=1, to=200, by=2)
x
sum(x)
5. Erstellen Sie einen Vektor x, der 5 mal hintereinander alle ungeraden Zahlen im Bereich von 1 bis 10 enthält.
Nutzen Sie die Funktion rep() und seq().
Welcher Wert steht an Position 17 des Vektors?
x<-rep(seq(from=1, to=10, by=2), times = 5)
x
x[17]
6. Erstellen Sie einen Vektor x, der alle geraden Zahlen von 2 bis 30 enthält.
Welche Summe ergibt sich aus den Werten an der Position 2, 5 und 8 bis 10 des Vektors?
x<-seq(from=2, to=30, by=2)
x
sum(x[c(2,5)], x[8:10])
7. Erstellen Sie einen Vektor x, der alle geraden Zahlen von 2 bis 30 enthält.
Welche Summe von x ergibt sich, wenn man alle ausser den ersten drei Zahlen des Vektors x einbezieht??
x<-seq(from=2, to=30, by=2)
x
sum(x[-(1:3)])
8. Erstellen Sie die 2 Vektoren, “names” und “age”. Der Vektor “names” enthält die Namen von 5 Personen (Peter, Harry, John, Julia, Sabrina), “age” das Alter von 5 Personen (23, 34, 53, 44, 36).
Speichern Sie die Namen in alphabetisch und das Alter in aufsteigend sortierter Reihenfolge in jeweils derselben Variable.
Geben Sie das Minimumalter aus.
names <- c("Peter", "Harry", "John", "Julia", "Sabrina")
age <- c(23, 34, 53, 44, 36)
names <- sort(names)
names
age<-sort(age)
age
min(age)
9. Erstellen Sie erneut den Vektor “age”. Der Vektor “age” enthält das Alter von 6 Personen (23, 34, 53, 44, 36, 5). Geben Sie die Indexnummer des Eintrags der jüngsten Person aus.
#age <- c(23, 34, 53, 44, 36, 5)#1
age <- c(23, 34, 53, 44, 36, 5)
which.min(age)
#2
age <- c(23, 34, 53, 44, 36, 5)
ord<-as.numeric(order(age))
ord
which.min(ord[age])
10. Erstellen Sie erneut die 2 Vektoren, “names” und “age”. Der Vektor “names” enthält die Namen von 5 Personen (Peter, Harry, John, Julia, Sabrina), “age” das Alter von 5 Personen (23, 34, 53, 44, 36). Definieren Sie die Variable “i” als Index der ältesten Person.
Nutzen Sie “i”, um den Namen der ältesten Person zu finden. Lassen Sie sich den Namen ausgeben.
#names <- c("Peter", "Harry", "John", "Julia", "Sabrina")
#age <- c(23, 34, 53, 44, 36)names <- c("Peter", "Harry", "John", "Julia", "Sabrina")
age <- c(23, 34, 53, 44, 36)
i<-which.max(age)
names[i]
11. Erstellen Sie erneut die 2 Vektoren, “names” und “age”. Der Vektor “names” enthält die Namen von 5 Personen (Peter, Harry, John, Julia, Sabrina), “age” das Alter von 5 Personen (23, 34, 53, 44, 36). Definieren Sie die Variable “rang” (rank()) als Rang des Alters der Personen.
Nutzen Sie “rang”, um den Namen der jüngsten Person zu finden. Lassen Sie sich den Namen ausgeben.
#names <- c("Peter", "Harry", "John", "Julia", "Sabrina")
#age <- c(23, 34, 53, 44, 21)names <- c("Peter", "Harry", "John", "Julia", "Sabrina")
age <- c(23, 34, 53, 44, 21)
rang<-rank(age)
rang
names[rang==1]
!!Geschafft!!
Weitere Inputs und Übungen zum Thema “Vektoren” und “Data Frames” folgen in Sitzung II.
Was haben wir gelernt:
Wir haben ein grundlegendes Verständnis der Programmiersprache R und können R mittels Console oder RStudio bedienen.
Wir können lokal auf unserem Rechner ein R-Projekt anlegen, Code-Files benutzen und Daten einlesen.
Wir können verschiedene Datenformate, wie csv, txt oder proprietäre Format (Excel), aber auch aus anderen Statistikprogrammen wie bswp. SPSS als tibble (Data Frame - mehr dazu in Sitzung II) in R importieren.
Wir wissen, wie man R als Taschenrechner für verschiedene Rechenarten benutzt. Wir können Vektoren erstellen, bearbeiten und Informationen aus den in ihnen gespeicherten Daten extrahieren.
Homework
Laden Sie das R-Skript herunter und folgen Sie den dort angegebenen Arbeitsschritten.