Zweck von diesem Tutorial 1
Das Lehrfonds-Projekt DAWS meint Data-Science mit Amazon-Web-Services, also kurz “Data-Science mit Cloud-Lösungen” - marginal werden auch andere Clouds wie die Google-Cloud einbezogen.
Allgemeine Warnung kurz vorweg:
Es ist wichtig, als Data-ScientistIn Cloud-Lösungen zu kennen und diese auch zu benutzen. Gleichzeitig sei von den teilweise enormen Kosten gewarnt, welche gewisse Services nach sich ziehen. Der Support beim Löschen von Services seitens Amazon oder Google hat sich als sehr ungenügend erwiesen und die Nutzung erfolgt ausschliesslich auf eigenes Risiko.
Zu empfehlen ist daher folgendes:
Benutzt man die Services “nur” zum Üben, so reserviert man sich ein Budget, zum Beispiel CHF 100 und ist nicht beunruhigt, wenn Kosten entstehen.
Man absolviert die Tutorials und löscht alle Objekte wie Data-Buckets, Modell-Endpunkte usw. gleich nach Beenden
der Tutorials.
Registrieren bei AWS
Um sich bei AWS zu registrieren, brauchen Sie eine gültige Kreditkarte und eine gültige Email. Auf Ihrem Computer verfügen Sie über Admin-Rechte. Die Ausführungen werden hier absichtlich nicht zu detailliert beschrieben, da sich auf AWS hin und wieder die Einstellungen etc. ändern. Die Hilfe von AWS ist zum Erstellen der Services aber gut, daher sei das vorgehen untenstehend generisch beschrieben.
- Navigieren Sie zu https://aws.amazon.com/de/
- Klicken Sie oben rechts auf “AWS-Konto erstellen”. Geben Sie dann eine Email-Adresse an und optional einen Konto-Namen.
- Geben Sie Ihre Kreditkarte an.
- Loggen Sie sich aus und anschliessend mit Ihrer Email-Adresse und Benutzername wieder ein.
- Gehen Sie zum Konto-Name oben rechts, dann auf Sicherheitsanmeldeinformationen, und dann auf Zugriffsschlüssel generieren. Notieren Sie folgende Schlüssel:
aws_access_key_idundaws_secret_access_key, so dass Sie diese jederzeit zur Verfügung haben!
Vorbereitungen: reticulate - R lokal mit Python verbinden
Wir beginnen, indem wir R/RStudio starten, um das Paket reticulate und miniconda auf Ihrem Rechner zu installieren:
reticulate ist ein R-package, welches die Kommunikation mit Python erlaubt (von R aus).
Je nach Systemversion von Windows könnte es sein, dass Sie untenstehenden Schritt ebenfalls machen müssen:
Wenn Sie Windows verwenden, dann stellen Sie bitte sicher, dass Sie nach der Installation von miniconda die folgenden Einträge zu Ihrer Systemvariablen PATH hinzufügen, da sonst die folgenden Befehle reticulate::conda_install() fehlschlagen, wenn Sie das Argument pip = TRUE setzen. Siehe hierzu diese Diskussion auf GitHub zu diesem Thema: https://github.com/pypa/virtualenv/issues/1139. (Wenn Sie die Systemvariable PATH nicht bearbeiten wollen, lesen Sie bitte den Abschnitt Alternative Paketinstallation im nächsten Abschnitt als alternativen Ansatz bei der Erstellung unserer Amazon SageMaker-spezifischen conda-Umgebung).
System-Variablen in Windows:
C:\%Miniconda3_DIR%;
C:\%Miniconda3_DIR%\Scripts;
C:\%Miniconda3_DIR%\Library\bin%Miniconda3_DIR% sollte durch Ihren Miniconda-Installationspfad ersetzt werden.
Bitte schliessen Sie R/RStudio und öffnen Sie es erneut, nachdem Sie Ihre Systemvariable PATH bearbeitet haben (ein Neustart der R-Sitzung innerhalb von RStudio reicht nicht aus).
install.packages("reticulate")
library(reticulate)
install_miniconda()Denken Sie bitte dran, dass Sie allenfalls noch die oben genannten PATH-Variablen setzen müssen. Hierfür brauchen Sie Admin-Rechte.
Anschliessend starten Sie R-Studio neu.
Bevor Sie in Ihrem neuen Code nun die library reticulate laden, erstellen Sie über folgenden Befehl untenstehend eine Systemumgebung conda, unsere wird hier r-reticulate genannt, wir können Sie aber beliebig bennen. Die erste und dritte Zeile unten wird nach erfolgreicher Installation der conda-Umgebung auskommentiert. Wenn Sie vorab die Bibliothek mit library(reticulate) laden, funktioniert es nicht, der Befehl muss implizit erfolgen durch: reticulate:: ...
# reticulate::conda_create("r-reticulate")
reticulate::use_condaenv("r-reticulate")
# reticulate::conda_install("r-reticulate",c('keras','tensorflow','sagemaker','awscli','boto3','keras_visualizer'), pip = TRUE)
Die dritte Zeile können Sie später bei Bedarf wieder benutzen, um weitere Python packages in Ihre conda-Umgebung zu installieren (z.B. numpy oder pandas).
Erste Gehversuche auf AWS mit R
Navigieren Sie nun in Ihr AWS Konto. Oben links unter Services suchen Sie nun nach S3. S3 steht für skalierbare Speicherkapazität in der Cloud. Aktivieren Sie den S3-Service für Ihr Konto.
Zusätzlich müssen Sie in der Billing Management Console die Region eu-central-2 (Zürich) aktivieren.
Hinweis:
Es kann immer wieder sein, als dass gewisse Services für gewisse Regionen seitens AWS nicht verfügbar sind. Angenommen, diese Services brauchen einen S3-bucket, so müssen Sie diesen natürlich dort anlegen, wo der Service auch Zugriff hat.
Nachdem der Service aktiviert ist, wollen wir nun einen bucket anlegen - das ist ein Container, wo wir Datensätze in AWS ablegen können und die AWS Machine-Learning-Umgebung (sagemaker) im Nachhinein darauf zugreifen kann.
Anlegen eines Bucket in Amazon S3
Um bei AWS Daten hoch- und runterladen zu können, nutzen wir den S3-Service und erstellen einen Bucket.
Obiger Code soll natürlich die Buckets von Fabian Heimsch auflisten.
Der Code liefert folgenden existierenden Bucket-Namen auf:
[1]mynewbucketfhnw
Dieser scheint tatsächlich (bei Fabian Heimsch) zu existieren, loggen Sie sich bei AWS ein und gehen Sie über Suchen zum S3-Service (in der Suchmaske oben “S3”) eingeben. Ihre Seite wird leer sein. Die aktuelle (von Fabian Heimsch) zeigt folgendes:
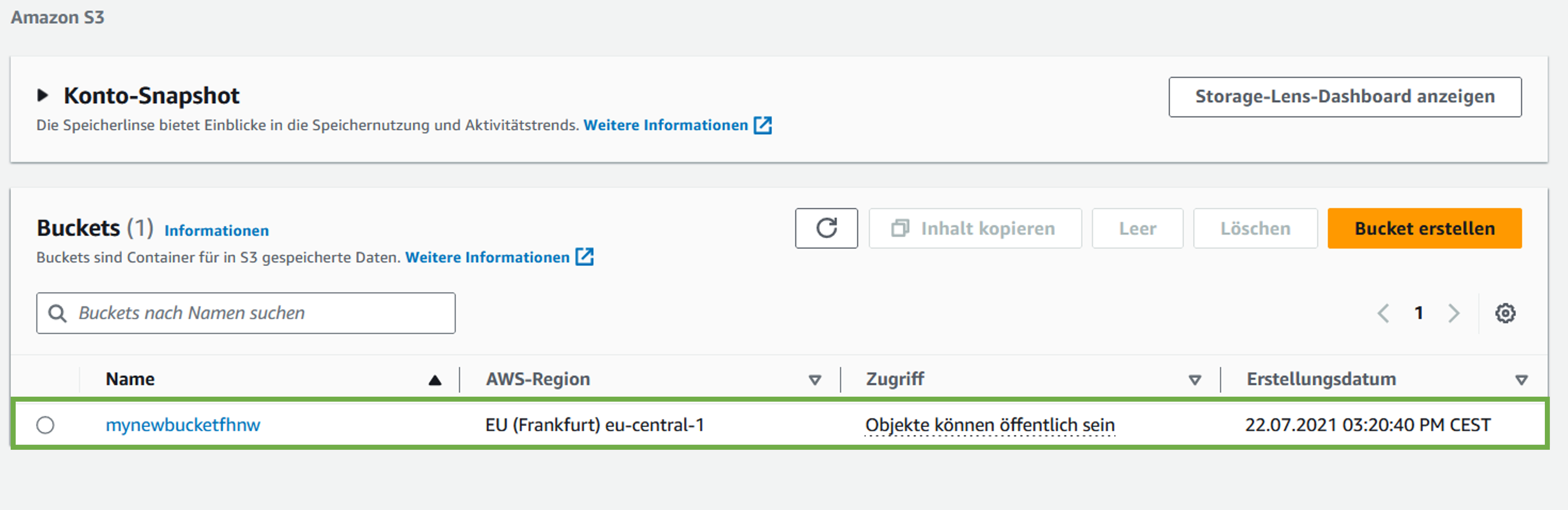
Der Service verbindet sich also korrekt mit AWS und ist fähig, die existierenden Buckets zu listen. Nun wollen wir einen neuen Bucket kreieren und Daten hoch- resp. runterladen.
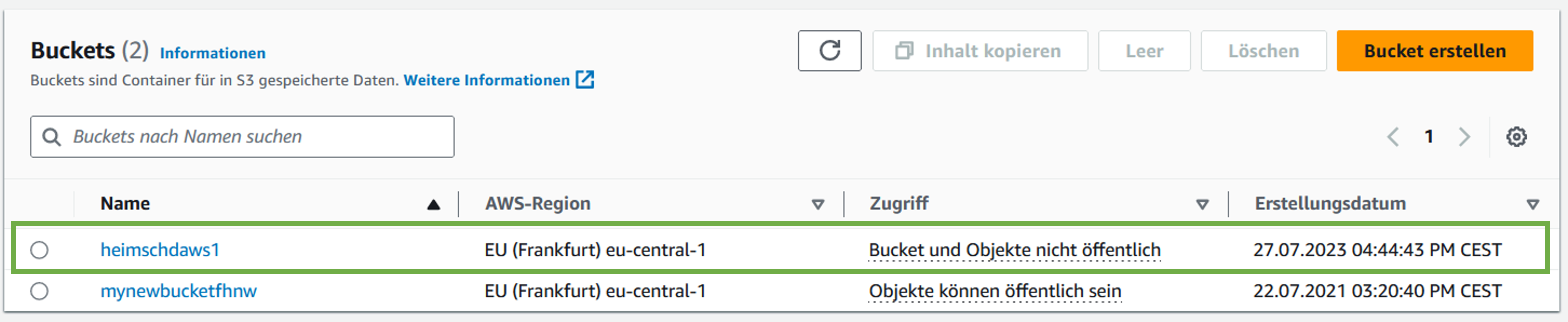
Wir nennen unseren Bucket nachnamedaws1, also im vorliegenden Fall heimschdaws1, wobei Sie Ihren Nachnamen entsprechend einfügen.
[1]heimschdaws1
[2]mynewbucketfhnw
Wenn wir nun noch auf der S3-Seite von Amazon “F5” drücken, um die Seite zu erneuern, so erscheinen folgende Buckets:
Hochladen, Runterladen und Löschen von Daten in einen Amazon S3 Bucket
Wir speichern nun bei uns lokal einen R-Datensatz. Wir nehmen den berühmten iris-Datensatz, der mit dem Befehl iris aufgerufen werden kann. Er beinhaltet die Länge von Blütenblättern und -Kelchen und hat das Ziel, daraus die Spezies der Lilienart vorherzusagen.
Bei Klick auf den Bucket heimschdaws1 ist dieser leer:
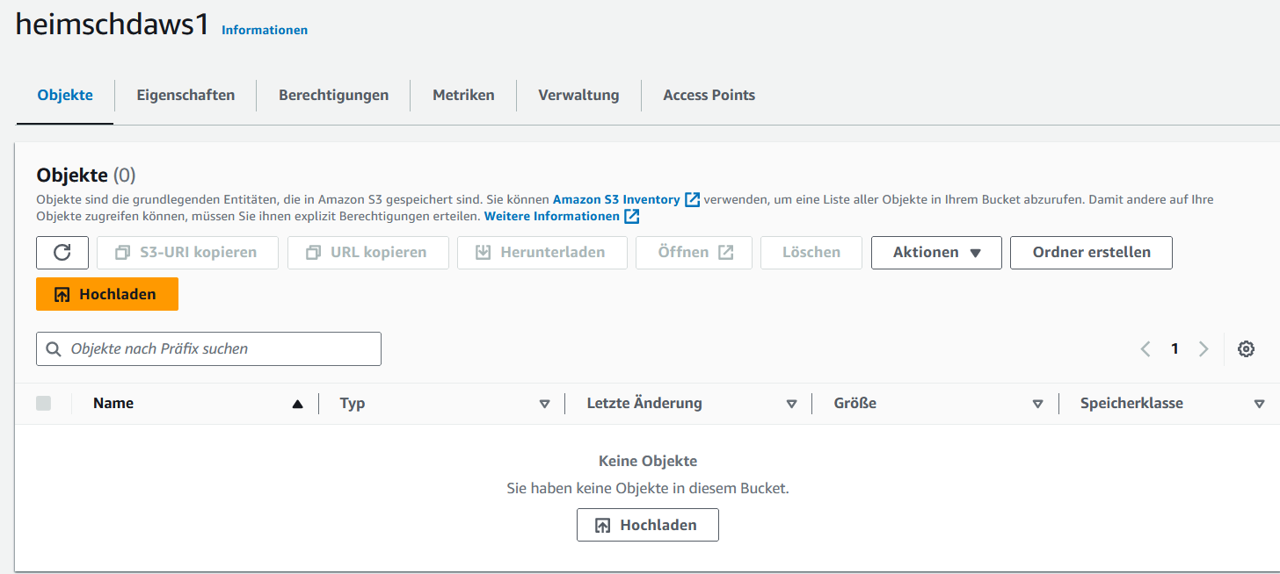
Mit folgendem Code bewerkstelligen wir nun folgendes:
- In Zeile 40 speichern wir den
Iris-Datensatz lokal auf unserem Rechner
- In Zeile 46 laden wir den Datensatz hoch in den AWS-Bucket und nennen ihn
Key = iris.csv. Das Resultat nach Erneuern der Website mit “F5” schaut wie folgt aus:
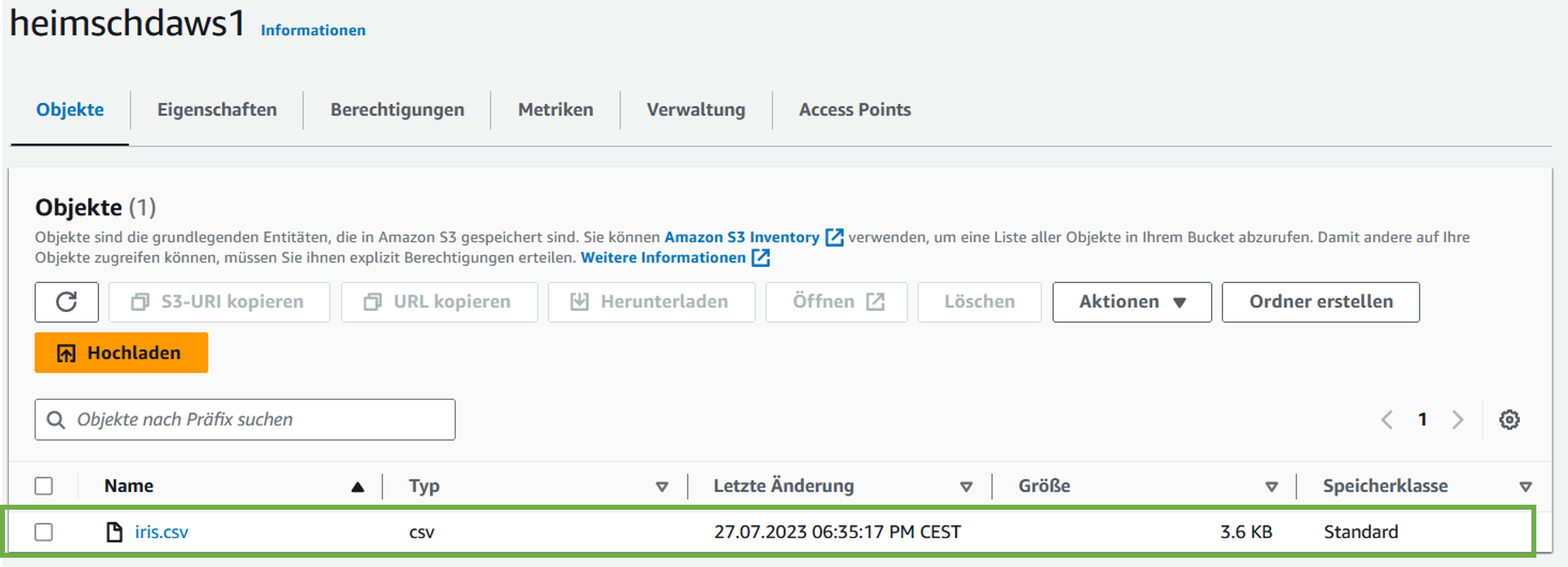
- Faszinierend, oder? - Nun wollen wir den Datensatz vom Bucket herunterladen, was wir mit Zeile 49 erledigen. Das Resultat ist als lokal aufgenommener Screenshot untenstehend abgebildet.
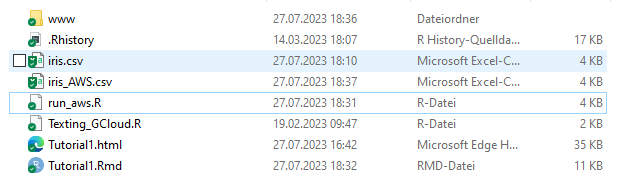
- Jetzt löschen wir den Datensatz auf AWS mit Zeile 52. Nach Erneuern der Website sehen wir, dass der Datensatz wiederum verschwunden ist.
- Zum Schluss löschen wir den Bucket mit Zeile 55, das Erneuern der S3-Website zeigt:
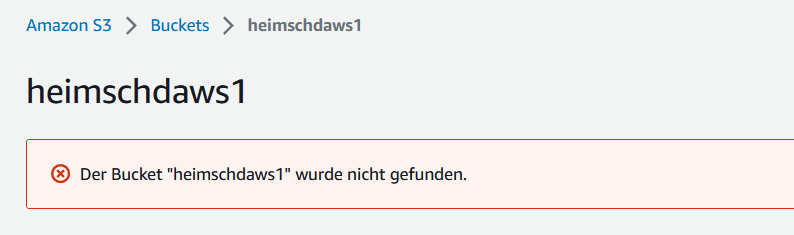
Learnings
1. Wir können Data-Container (Buckets) auf AWS erstellen
2. Wir können Daten hoch- und runterladen und wieder löschen.
3. Nach erledigtem Tutorial löschen wir den Bucket, damit keine Kosten anfallen.