Introduction to the data
The concept of the tutorial

Our data
In this tutorial, we use a dataset that is called housingrents.csv. You find the dataset in our Moodle course, or, alternatively, you may download it here and store it in a folder, e.g. BAQM_SimpleRegression.
After generating a project in R or after setting the work-directory in R that contains, the data, the data can be read in with the following code:
data <- read.csv("housingrents.csv",sep=";")
For the tutorial, the data is already available in the dataframe data. Display the head of the data below. Also, with the command str you can investigate what kind of variables the data contain.
head(data)
str(data)
spec(data)We have the following variables:
id, an unique identifier of the apartments in the datasetrooms, size of the apartments (can be treated as numeric variable or as a factor)area, size of the apartments, in \(m^2\) (numeric variable)rent, monthly rent fee of the apartments in \(CHF\) (numeric variable)nre, dummy variable that indicates whether the apartment is rented out by company nre (factor variable)econage, economic age of the apartment, years since the apartment was built or last renovated (numeric variable)balcony, character indicating whether the apartment has a balcony or not (factor variable)
Our overall goal is to build a regression model that can estimate rents (the dependent variable), given a set of independent or explanatory variables.
Recall that categorical variables are factor variables. In R, they can be summarised using frequency tables (table()) or by building a barplot using the command barplot().
For numeric variables, we can provide a five-number summary statistic using the command summary. For a simple graphical analysis of a numerical variable, we can use commands hist() and boxplot(). In the code below, please provide a univariate analysis of all variables in the data.
table(data$rooms)
summary(data$rooms)# rooms
table(data$rooms)
summary(data$rooms)
# area
summary(data$area)
# rent
summary(data$rent)
# nre
summary(data$nre)
table(data$nre)
# econage
summary(data$econage)
# balcony
table(data$balcony)Answer the following questions on our data
# rent
summary(data$rent)
hist(data$rent)
boxplot(data$rent)
# rooms
table(data$rooms)
barplot(table(data$rooms))
length(which(is.na(data$rooms)))
# area
mean(data$area,na.rm=T)
quantile(data$area,c(0.1,0.9),type=2,na.rm=TRUE)
# age
length(which(is.na(data$econage)))
cor(data$econage,data$rent,use="pairwise.complete")
# balcony
table(data$balcony)
length(which(is.na(data$balcony)))
# nre
table(data$nre)Now, you may copy and save this part of code to a file 01_SimpleRegression.R.
- Store the code in the same folder as you previously stored the
housingrents.csvfile
- Then, open the code by double-clicking it.
- Navigate to
File\(\rightarrow\)New Projectand presssavewhen being prompted.
- The new project wizard will open and you choose
Existing Directoryand then, you navigate to the folderBAQM_SimpleRegression
- Done - you have generated a
R-project.
Important Information
how we work...
Notes on a Data Science Project
Normally, a data-science project deals with at least these steps:
- Overview, data cleaning and matching (not necessary)
- Descriptive Statistics and data wrangling - done (data wrangling not necessary here)
- Exploratory Analysis (bivariate and multivariate analysis of the data)
- Feature Engineering - create new features as predictors (new variables) - here, it might be interesting to add, e.g., commuting-time to the next railway station or so (if possible)
- Model Selection (estimate many models and choose the best one in a certain metric)
- Model deployment - deploy your model as a webservice to other persons
Our first regression
We have already seen that our data consist in \(n=152\) observations.
In order to start our introduction to regression analysis, we first only analyse a subset of the data.
This is not a train-test-split as often done in Machine Learning, but an approach that is rather handy since it allows you to follow calculations more accurately with less data points.
We want to choose \(n=10\) random data points. We set the random number generator with the code-snippet:
RNGkind(sample.kind="Rounding")
set.seed(33)
This ensures that everyone who executes the code will obtain the same ‘random’ data points.
RNGkind(sample.kind="Rounding")
set.seed(33)
subdata <- data[sample(1:nrow(data),size=10,replace=F),c("area","rent")]area | 80 | 87 | 93 | 200 | 174 | 105 | 77 | 45 | 50 | 40 |
rent | 860 | 896 | 870 | 2,345 | 2,730 | 1,547 | 974 | 1,040 | 281 | 274 |
Descriptive Statistics
Now, calculate descriptive statistics for rent and area in the subdata dataframe.
mx<-mean(subdata$area,na.rm=T)
my<-mean(subdata$rent,na.rm=T)
sx<-sd(subdata$area,na.rm=T)
sy<-sd(subdata$rent,na.rm=T)
r<-cor(subdata$area,subdata$rent,use="pairwise.complete")Apparently, we obtain the following descriptive statistics:
mean.area | mean.rent | sd.area | sd.rent | corr |
|---|---|---|---|---|
95.1 | 1,181.7 | 53.26 | 807.23 | 0.923 |
Simple Regression
The objective is to calculate the best linear predictor for the dependent variable \(y\) (rent) with the independent variable \(x\) (area), thus:
\(y_i = a\cdot x_i + b + e_i\)
\(\hat{y_i}=a\cdot x_i + b\)
\(e_i\) is the error term or the difference between real values for rents \(y_i\) and predicted values \(\hat{y_i}\). Thus, \(e_i=y_i - \hat{y_i}\).
The main question is how we can estimate \(a\) and \(b\), the slope and the intercept of the regression equation.
\(\color{red}{\text{$\hat{y_1}=2.5\cdot x + 750$}}\)
\(\color{blue}{\text{$\hat{y_2}=14\cdot x - 150$}}\)
\(\color{green}{\text{$\hat{y_3}=20\cdot x + 750$}}\)
We draw a scatter plot (blue points, the cross indicates the mean coordinates) and try to decide which regression line \(\hat{y_i}\) is the best fit for our data.
Below, you find a scatter plot of the \(10\) data points, along with the three proposed regression lines. With the App below, you can move around the black line (which currently lies on the \(\color{red}{\text{red}}\) line. You can also draw the residuals - which line leads to the smallest sum of squared residuals?
\(SSR = \sum e_i^2\).
The \(\color{blue}{\text{blue}}\) line represents the best fit.
The minimization process of \(SSR = \sum (y_i - a\cdot x_i - b)^2\) with respect to \(a\) and \(b\) leads to the following formulas:
\[a = r\cdot \frac{s_y}{s_x}\] \[b = \bar{y}-a\cdot \bar{x}\]
We obtain: \(a=0.923 \cdot \frac{807.23}{53.26} = 13.99\).
and for the intercept: \(b=1181.7-13.99\cdot 1181.7 = -148.46\)
Thus, the regression line is:
\[\hat{y_i}=13.99\cdot x -148.46\]
Where \(x\) stands for the area and \(\hat{y}\) for the predicted rent.
For instance, we see that the mean area of \(\bar{x}=95.1\) is not a data point, but the regression line allows a prediction for the rent of an apartment of this size:
\(\hat{y}=13.99\cdot 95.1 -148.46 = 1181.7\)
Obviously, the regression line hits the mean of the data perfectly.
What does the result mean? \(a=13.99\) is the slope of the regression line and measures the (linear) dependency of rent on area, thus, a \(1m^2\) increase in the size of a flat increases the rent by \(13.99\) CHF. It makes sense that the coefficient is positive. \(b\) is the predicted rent of a flat, when the area \(x\) is set to zero (\(x=0\)). We would expect a rent of 0 if area \(x\) is zero.
Regression with R
With the following R-code, we perform a regression:
mymodel <- lm(rent~area, data=subdata)
summary(mymodel)
The first line represents the specification of the regression model: rent, the dependent variable, is regressed on area, the independent variable. The second argument specifies that the data is within the dataframe subdata. The second line of code returns the output of the regression.
mymodel <- lm(rent~area, data=subdata)
summary(mymodel)Now, you may copy the second part of the code 02_SimpleRegression.R.
- Store the code in the same folder as you previously stored the
housingrents.csvfile
Interpret our first regression
We now want to interpret the regression results:
##
## Call:
## lm(formula = rent ~ area, data = subdata)
##
## Residuals:
## Min 1Q Median 3Q Max
## -303.9 -245.5 -123.8 181.5 559.0
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -148.462 222.182 -0.668 0.522813
## area 13.987 2.063 6.779 0.000141 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 329.7 on 8 degrees of freedom
## Multiple R-squared: 0.8517, Adjusted R-squared: 0.8332
## F-statistic: 45.96 on 1 and 8 DF, p-value: 0.0001407Overall interpretation
- The standard deviation of the residuals \(e_i\) is: \(s_e = 329.67\). Recall that the standard deviation of the rents was \(s_y = 807.23\).
- The degrees of freedom (\(df\)) is \(n-k-1=10-1-1=8\). \(k\) stands for the number of regressors used, here \(k=1\).
- \(R^2\) amounts to 0.8517. This means that our model, where we explain rents with the area variable, can explain 85.17% in the variation of the dependent variable, the rents.
- We focus on adjusted \(R^2\): Formula: \(R_{adj}^2 = 1-(1-R^2)\cdot \frac{n-1}{n-k-1}\). This means: The more independent variables we use in our model, the more we get ‘penalized’ and explained variation is reduced. Do not use ‘unneccessary’ independent variables in your model, (here, \(n=10\), \(k=1\)). Adjusted \(R^2\) is: 83.32%.
Further, The \(F\)-statistic tests whether all coefficients in the model are significantly different from zero. Our model from the sample is: \(y_i = a\cdot x_i +b+e_i\). With greek letters, we want to refer to the true coefficients in the population (all apartments in Switzerland, thus \(y_i=\alpha \cdot x_i+\beta+\epsilon_i\)). The null hypothesis is:
\(H_0\): \(\alpha=0\) and \(\beta=0\), e.g. at confidence level \(100-\alpha=95\%\),
\(H_A\): \(\alpha \neq 0\) or \(\beta \neq 0\), \(\alpha = 5\%\).
From the table above, we can see that the \(p\)-Value is below \(\alpha=5\%\). Thus, we reject \(H_0\) and say that the coefficients are (jointly) significantly different from zero - this is a result which we desire! Our sample allows us to conclude that there is a significant linear relationship between rents and area!
Coefficient-based interpretation for area
- The coefficient \(a\) amounts to \(a=13.99\frac{CHF}{m^2}\). This means that a \(1m^2\) increase in the size of a flat increases the monthly rent by \(13.99CHF\).
- The standard error of this coefficient is \(SE_a = 2.06\frac{CHF}{m2}\). The standard error measures the statistical uncertainty of the sample.
- The \(t\)-statistic tells us how far the coefficient \(a\) is away from zero, expressed in numbers of standard-errors. We obtain \(t=\frac{13.99}{2.06}=6.78\). This yields a \(p\)-value of 0.01% and tests the Null-hypothesis \(H_0\) whether the coefficient is zero or not.
\(H_0\): \(\alpha = 0\), \(100-\alpha=95\%\)
\(H_A\): \(\alpha \neq 0\), \(\alpha = 5\%\).
Since the \(p\)-value falls below \(\alpha = 5\%\), we reject \(H_0\) and say that the coefficient of area is statistically significantly different from zero. Of course we desire this result - we expact area to have a positive impact on rents.
Coefficient-based interpretation for the intercept
- The coefficient \(a\) amounts to \(a=-148.46CHF\). This means that an apartment of size \(0m^2\) is valued by the model at \(-148.46CHF\).
- The standard error of this coefficient is \(SE_b = 222.18CHF\). The standard error measures the statistical uncertainty of the sample.
- The \(t\)-statistic tells us how far the coefficient \(b\) is away from zero, expressed in numbers of standard-errors. We obtain \(t=\frac{-148.46}{2.06}=-0.67\). This yields a \(p\)-value of 52.28% and tests the Null-hypothesis \(H_0\) whether the coefficient is zero or not.
\(H_0\): \(\beta = 0\), \(100-\alpha=95\%\)
\(H_A\): \(\beta \neq 0\), \(\alpha = 5\%\).
Since the \(p\)-value falls above \(\alpha = 5\%\), we accept \(H_0\) and say that the intercept of the model is statistically not significantly different from zero. We also are ‘glad’ about this result: A \(0m^2\) room apartment’s value is zero.
Note on interpreting model coefficients from a regression…
- A coefficient exhibits a strong significance (significantly different from \(0\)), if the \(p\)-value falls below \(1\%\), medium significance, if the \(p\)-value falls below \(5\%\), and weak significance, if the coefficent falls below \(10\%\)
- Make sure you apply reasoning on the sign of the coefficient
- Also, check the \(F\)-statistic - it could be that its \(p\)-value reveals an overall significance of the model even if none of the coefficients are significant!
- Make sure you check adjusted \(R^2\) and not \(R^2\). Adjusted \(R^2\) penalizes a regression model when taking up too many explanatory variables.
Univariate Regression with full sample
Now, we take the full sample and have a closer look at regression results.
The file data now consists in the full sample. Below, run a univariate regression that explains rent with area and then answer the following questions.
mymodel <- lm(rent~area, data=data)
summary(mymodel)Inference after Univariate Regression
Predictions
With a regression model, we can on one hand quantify the effect that area has on rents. On the other hand, we also want to be able to make predictions.
The mymodel object stores two vectors in itself: fitted.values and residuals. For the moment, we only look at the first observation with Index 1: Write an R-Code that gives the following output: area and rent of this apartment, predicted rent of this apartment and the residuals. Also, try to replicate the predicted rent using the coefficients object within mymodel.
area1 <- data$area[1]
rent1 <- data$rent[1]
predicted.rent1 <- mymodel$fitted.values[1]
residuals.rent1 <- mymodel$residuals[1]
print(paste("area: ",area1," rent: ",rent1," predicted rent: ",predicted.rent1," residual:",residuals.rent1,sep=""))
a<-mymodel$coefficients[2]
b<-mymodel$coefficients[1]
a*area1+bThis was probably not too difficult. However, what if we wanted to make predictions at area values that we do not observe in the data, e.g. at a hypothethical area of c(0,30,87,300) square-meters? For doing this, we need the predict-command.
The command is:
predict(object, newdata = , interval = c('confidence','prediction'), se.fit=c(TRUE,FALSE), level = 0.95)
- The
objectis the previously estimatedmymodel-object, or any other model
- The option
newdatais indicating that the model should make predictions at new data, the input should be of type data.frame
- With the option
interval, we are indicating whether we want an estimation of the standard-error of the prediction at the mean (optionconfidence) OR for an individual value (optionprediction). What does this mean - consider the apartment ofareasize \(30m^2\). Then, the optionconfidencecalculates the standard-error for an ‘average’ apartment of size \(30m^2\). As you know, there might be many different \(30m^2\) apartments, e.g. such with or without a balcony, newly built apartments vs. 50 years old apartments and so on. Accordingly, the optionconfidenceis resulting in the standard-error of the average rent for such apartments, whereas the optionpredictionis giving the standard-error of an individual rent for such an apartment - the standard-error for the first type will be smaller than for the second type.
se.fit = TRUEspecifies to display the standard-error for each prediction.
levelspecifies the confidence-level \(1-\alpha\), which is set by default to \(0.95\).
Create a dataframe new with a column area=c(0,30,87,300). Then, make a prediction once for the option prediction and once for the option confidence - what do you note?
new <- data.frame(area=c(0,30,87,300))new <- data.frame(area=c(0,30,87,300))
# prediction at the mean
predict(mymodel, newdata = new, interval='confidence', se.fit=TRUE)
# individual prediction
predict(mymodel, newdata = new, interval='prediction', se.fit=TRUE)Note on interpreting model coefficients from a regression…
- Note that the coefficients are: For
area: \(a = 10.64\). This coefficient is equal to \(a=r\cdot \frac{s_y}{s_x}\), where \(r\) is the correlation between the two variables and \(s_y\) and \(s_x\) are the standard deviations. Convince yourself of this equality in the code below.
r <- cor(data$area,data$rent)
sy <- sd(data$rent)
sx <- sd(data$area)
r*sy/sx- Second, the
interceptof the regression line \(y=a\cdot x + b\) goes through the point \((\bar{x}|\bar{y})\). In other words, a prediction atarea=86.84is the mean value ofrent, which isrent = 1046. This means a regression line is able to perfectly predict the mean of the data!
- Predictions have lowest standard error at the mean of the data. The standard error however increases when moving away from the mean. Therefore, be careful with predictions that are out of sample,

Testing Coefficient - Hypotheses
Finally, we want to obtain Confidence-Intervals for our coefficients. Since our data just represent a sample, we do not know about the ‘true’ parameters \(\alpha\) and \(\beta\) in the population. We obtain confidence-intervals using the function confint.lm(mymodel,level=...) - Now, calculate a \(95\%\) and \(99\%\) confidence interval for our coefficients.
confint.lm(mymodel, level=0.95)
confint.lm(mymodel, level=0.99)What does this mean?
E.g. we might test the null-hypothesis that:
\(H_0\): \(\alpha = 13 \frac{CHF}{m^2}\), at a confidence level of \(1-\alpha = 95\%\),
\(H_A\): \(\alpha \neq 13 \frac{CHF}{m^2}\), at \(\alpha = 5\%\)
Since \(\alpha = 13\frac{CHF}{m^2}\) is not within the 95%-confidence-interval, we reject \(H_0\). The rent per sqm is significantly different from \(13\frac{CHF}{m^2}\)
In addition, we also might test the coefficient to be equal to \(13\), we use the function linearHypothesis from the car-package.
linearHypothesis(mymodel, "area=13")linearHypothesis(mymodel, "area=13")
# other tests
linearHypothesis(mymodel,"(Intercept)=0")
linearHypothesis(mymodel,"1*(Intercept)+87*area = 1150")Explanation:
1. The p-value of the test falls below \(5\%\), therefore, we reject \(H_0\) that \(\alpha=13\).
2. The p-value, of course, is the same as in the output of summary(mymodel) (look at the intercept) - it is significantly different from zero.
3. The last line represents a test for a prediction with area=87 (at the mean). The actual value is \(1240.3\) CHF per month, which is significantly different from \(1150\) CHF per month since the p-value falls below \(5\%\).
Now, you may copy the second part of the code 03_SimpleRegression.R.
- Store the code in the same folder as you previously stored the
housingrents.csvfile
Model Diagnostics
A regression model has several theoretical assumptions which should be checked. If these observations are fulfilled, we call the regression estimator (ordinary least squares estimator or OLS estimator) BLUE (Best Linear Unbiased Estimator).
- Best means, that the estimator has the lowest possible variance (efficient estimator)
- Unbiased means that the expected value of our coefficients are identical with the value from the population, e.g. \(E(a) = \alpha\).
Assumption (1): Linearity
The regression model \(y_i = a\cdot x_i + b + e_i\) assumes a linear relationship between the dependent variable \(y\) and the independent variable \(x\).
The linearity can be visually checked by plotting the error terms \(e_i\) (residuals) over the predicted values of the model (\(\hat{y_i}\)).
There should not be any obvious functional dependency between the residuals and the fitted values (e.g. parabolic shape or seasonal pattern).
If linearity of a model is not fulfilled, adding new variables such as squared variables may solve the situation.
The first graph of the autoplot() function allows for visual inspection of linearity.
# consider first graph
autoplot(mymodel)In the specific example, linearity seems to be fulfilled - the blue trend line is (more or less) horizontal.
A non-linear relationship tells us that our coefficient estimates are biased.
In addition, we might test for serial correlation in the error terms - serial correlation would be present in a pattern where residuals show some recurring pattern, e.g. seasonality. We accomplish this with the durbinWatsonTest() from the car package.
# consider first graph
durbinWatsonTest(mymodel)Since the \(p\)-value lies above \(5\%\), we accept the null-hypothesis of no serial-correlation.
Assumption (2): Normal distribution of the error terms
If the error terms \(e_i\) are normally distributed, the points lie on a 45°-line in a QQ-Plot, or at least only randomly fluctuate around that line.
If this is not the case, we see certain paterns around the 45°-line.
A non-normal distribution can potentially be corrected by transforming the variables in the model, e.g. by taking logarithms.
The second graph in autoplot() allows for investigating a QQ-Plot of the residuals \(e_i\). In addition, the command shapiro.test() applies a statistical test for normality of the residuals - if it’s \(p\)-value is above \(5\%\), normality can be assumed.
# consider second graph
autoplot(mymodel)
shapiro.test(mymodel$residuals)Obviously, the upper quantiles of our residuals deviate from the 45°-line. This is a rather typical behavior for right-skewed data. Non-normality of residuals leads to unbiased but inefficient coefficients.
Shortly re-estimate the model by taking logarithms of rent and area below. What do you note?
mymodel2 <- lm(log(rent)~log(area), data = data)
summary(mymodel2)
# consider second graph
autoplot(mymodel2)
shapiro.test(mymodel2$residuals)- The \(p\)-value is still below \(5\%\) but at least above \(1\%\), accordingly the problem would no more be that persistent.
- The interpretation changes. Looking at the results, we interpret the coefficient of
log(area)as follows: If theareaof an apartment increases by 1%, the price is expected to increase by 0.747%.
- Note that \(R_{adj}^2\) has (quite) substantially increased - therefore, taking logarithms would be an appropriate solution here (which we not do at the moment for reasons of interpretation).
Assumption (3) - Homoscedasticity
Homoscedasticity means that the variance of the residuals should be constant.
The variance of the error term is constant over the predicted values
In the scale-location plot, there should not be any obvious dependency between scale and location (of predictions).
Heteroscedasticity leads to inefficient coefficient estimates.
In the case of multiple regression, heteroscedasticity can be avoided by omitting certain variables. In practice, robust estimates of the variance-covariance matrix should be obtained (package sandwich)
The R function
ols_test_breusch_pagan()from packageolsrrtests the null hypothesis of homoscedasticity. If the p-value falls below 5%, the model suffers from heteroscedasticity.
# consider third graph
autoplot(mymodel)
ols_test_breusch_pagan(mymodel)In the 3rd plot, we can see that the Variance (more accurately the square root of standardized residuals) are increasing with increasing fitted values \(\hat{y_i}\). This means that heteroscedasticity is present - which yields inefficient coefficient estimates. Also, the \(p\)-value from the Breusch-Pagan test indicates heteroscedasticity.
Below, re-run the model again with log-transformed variables and interpret the result of the Breusch-Pagan test.
mymodel2 <- lm(log(rent)~log(area), data = data)
summary(mymodel2)
# consider third graph
autoplot(mymodel2)
ols_test_breusch_pagan(mymodel2)Also here, we can clearly see that log-transformation not only improves non-normality of the residuals but also results in homoscedasticity. For ease of interpretation, we still stick with the original values in the model. If heteroscedasticity is present, you also can use a different Variance-Covariance-Matrix that accounts for heteroscedasticity using the vcovHC() function from the sandwhich package (later…).
Assumption (4) - no influential observations or outliers
Outliers are observations that are badly predicted by the model. The either have extremely large or negative residuals. We can identify outliers using the function outlierTest() from the car package.
Outliers are present if the limit for the standardised residuals of \(\pm 3\) are violated, or if there is a leverage larger than \(\frac{2(k+1)}{n}\).
Outliers that are marked (with numbers) should be investigated more closely.
Outliers distort both: accuracy of coefficient estimates (bias) and efficiency!
Test your model against influential outliers.
Possibility 1: Remove outliers from your model, recalculate the model, compare coefficients and other results. (A problem might be that new data points will be marked as outliers).
Possibility 2: Transform the data in the model (e.g. by taking logarithms)
Possibility 3: The packageMASSenables you to calculate robust regression:rlm()The function uses a different weighting of observations than OLS does. Influential outliers are given less weight.
Possibility 4: Apply quantile regression (e.g. regression not at the mean but regression at conditional quantiles – packagequantreg, usingrq()).
Re-run function autoplot() and consider the fourth graph:
In addition, use the function outlierTest() form car package to identify potential outliers.
# consider fourth graph
autoplot(mymodel)
ot <- outlierTest(mymodel)
otNow, we might remove these outliers - but let’s shortly look at rows 98 and 151.
# consider fourth graph
autoplot(mymodel)
ot <- outlierTest(mymodel)
index <- sort(as.numeric(names(ot$rstudent)))
data[index,c("rent","area")]We can see that the rent for both flat is surprisingly high - given the fact we estimated a value of \(a = 10.6 \frac{CHF}{m^2}\). We now remove the outliers from the data and recalculate our model according to Possibility 1 above.
# consider fourth graph
autoplot(mymodel)
ot <- outlierTest(mymodel)
index <- sort(as.numeric(names(ot$rstudent)))
data1 <- data[-index,]
mymodel.p1 <- lm(rent~area,data=data1)
summary(mymodel.p1)
outlierTest(mymodel.p1)
# we also might remove '63'
data2 <- data1[-which(rownames(data1)=='63'),]
mymodel2 <- lm(rent~area,data=data2)
outlierTest(mymodel2)
# we also might remove '102'
data3 <- data2[-which(rownames(data2)=='102'),]
mymodel3 <- lm(rent~area,data=data3)
outlierTest(mymodel3)
summary(mymodel3)As we can see, adjusted \(R^2\) is increasing by approximately \(1\%\), so we might remove the two outliers and test again if we identify outliers - and remove them as long as Bonferroni \(p\)-values are below \(1\%\). We alreday tested possibility 2 from above - there are no outliers in the upper part of the distribution using this method. We proceed with possibilities 3 and 4:
# rlm()
mymodel.rlm <- MASS::rlm(rent~area,data=data)
summary(mymodel.rlm)
# rq()
mymodel.rq <- quantreg::rq(rent~area,data=data,tau = c(0.5))
summary(mymodel.rq)In contrast to outliers, high-influential data points are not necessarily having high residuals but uncommon combinations of predictor variables.
Using the function influencePlot(), we now may identify outliers: 98, 151, and we may identify influential observations: 137, 148 - interestingly, these are the observations with the two largest living areas of \(200m^2\) and \(250m^2\) in the data.
influencePlot(mymodel)Now, you may copy the second part of the code 04_SimpleRegression.R.
- Store the code in the same folder as you previously stored the
housingrents.csvfile
The fun-part - Homegate
The univariate regression explains a dependent variable \(y\) with an independent variable \(x\). We stay with the example of rents and want to explain monthly rents (in CHF) with living space (in \(m^2\)).
Consider, for instance, the municipality 8712 Stäfa (ZH). The variables are as follows:
i | 1.0 | 2.0 | 3.0 | 4.0 | 5.0 | 6.0 | 7.0 | 8 | 9.0 | 10 | 11 |
rent | 4.5 | 1.5 | 2.5 | 2.5 | 3.5 | 3.5 | 3.5 | 4 | 4.5 | ||
area | 148.0 | 40.0 | 77.0 | 64.0 | 75.0 | 82.0 | 88.0 | 76 | 122.0 |
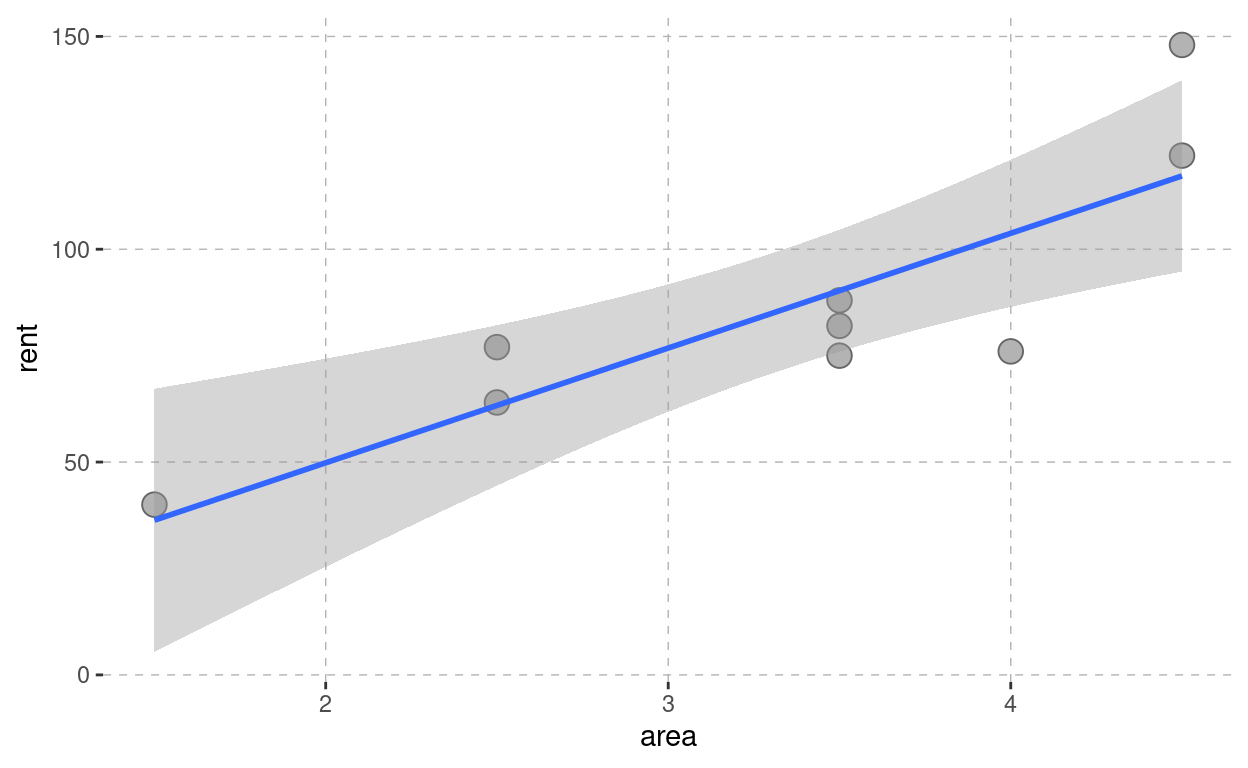
Descriptive Statistics:
Variable | mean | std.dev | correlation |
|---|---|---|---|
area x | 3.33 | 1.00 | |
rent y | 85.78 | 31.74 | 0.849 |
The goal of the univariate regression calculation is to find the parameters \(a\) and \(b\). The following applies:
\(y_i = a\cdot x_i + b + e_i\)
Where:
- \(x_i\) and \(y_i\) are the coordinates \(x\) and \(y\) of an arbitrary data point \(i\)
- \(a\) and \(b\) are the parameters (slope and intercept) of the regression line to be estimated.
- We call the part \(a\cdot x_i+b\) the value predicted by the regression calculation \(\hat{y_i}\).
- \(e_i\) denote the error terms or residuals. These are the prediction errors of the model \(\hat{y_i}=a\cdot x_i+b\).
Now, to determine the parameters \(a\) and \(b\), it is necessary to establish a quality measure based on the prediction errors and to minimize this measure.
This quality measure is the sum of the squared error terms.
With the app below, you can retrieve data from homegate for a date (today or in the past) you might want to choose. Then, you may choose your home municipality by clicking in the box ‘choose PLZ’, delete the entry with backspace-button, and write the PLZ of your choice.
Afterwards, you may download the data and play with the app a bit - the goal is that you repeat our analysis with your own data.
Descriptive Statistics
What is the 'best' parameter choice?
R-Code
The code below assumes that the data exists as dataframe df: mymodel <- lm(rent~area,data=df)
summary(mymodel)Short explanation of R-Output
Calculate a prediction with R
.
Your turn! Download the data file for the specific municipality you have chosen. Then perform a simple regression of rents on area, make predictions, and run all kind of specification tests and model diagnostics.